 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaofei He
Model Compression and Efficient Inference for Large Language Models: A Survey
Feb 15, 2024
Transformer based large language models have achieved tremendous success. However, the significant memory and computational costs incurred during the inference process make it challenging to deploy large models on resource-constrained devices. In this paper, we investigate compression and efficient inference methods for large language models from an algorithmic perspective. Regarding taxonomy, similar to smaller models, compression and acceleration algorithms for large language models can still be categorized into quantization, pruning, distillation, compact architecture design, dynamic networks. However, Large language models have two prominent characteristics compared to smaller models: (1) Most of compression algorithms require finetuning or even retraining the model after compression. The most notable aspect of large models is the very high cost associated with model finetuning or training. Therefore, many algorithms for large models, such as quantization and pruning, start to explore tuning-free algorithms. (2) Large models emphasize versatility and generalization rather than performance on a single task. Hence, many algorithms, such as knowledge distillation, focus on how to preserving their versatility and generalization after compression. Since these two characteristics were not very pronounced in early large models, we further distinguish large language models into medium models and ``real'' large models. Additionally, we also provide an introduction to some mature frameworks for efficient inference of large models, which can support basic compression or acceleration algorithms, greatly facilitating model deployment for users.
Few-shot Hybrid Domain Adaptation of Image Generators
Oct 30, 2023Can a pre-trained generator be adapted to the hybrid of multiple target domains and generate images with integrated attributes of them? In this work, we introduce a new task -- Few-shot Hybrid Domain Adaptation (HDA). Given a source generator and several target domains, HDA aims to acquire an adapted generator that preserves the integrated attributes of all target domains, without overriding the source domain's characteristics. Compared with Domain Adaptation (DA), HDA offers greater flexibility and versatility to adapt generators to more composite and expansive domains. Simultaneously, HDA also presents more challenges than DA as we have access only to images from individual target domains and lack authentic images from the hybrid domain. To address this issue, we introduce a discriminator-free framework that directly encodes different domains' images into well-separable subspaces. To achieve HDA, we propose a novel directional subspace loss comprised of a distance loss and a direction loss. Concretely, the distance loss blends the attributes of all target domains by reducing the distances from generated images to all target subspaces. The direction loss preserves the characteristics from the source domain by guiding the adaptation along the perpendicular to subspaces. Experiments show that our method can obtain numerous domain-specific attributes in a single adapted generator, which surpasses the baseline methods in semantic similarity, image fidelity, and cross-domain consistency.
UniPAD: A Universal Pre-training Paradigm for Autonomous Driving
Oct 12, 2023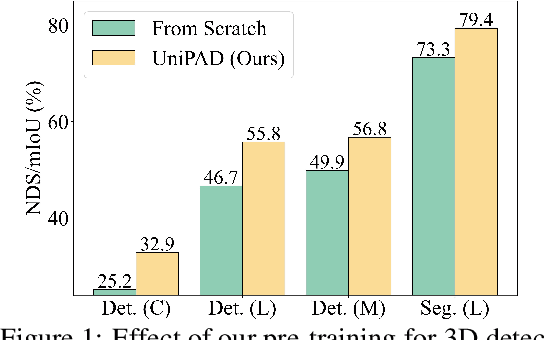
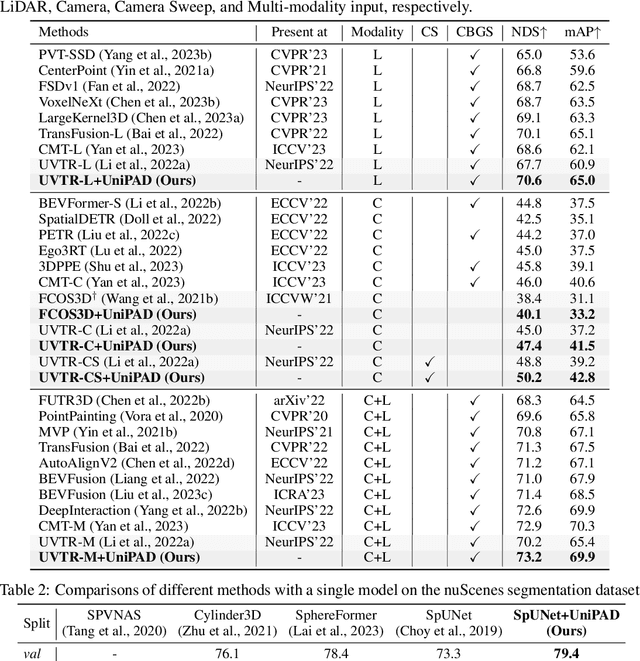
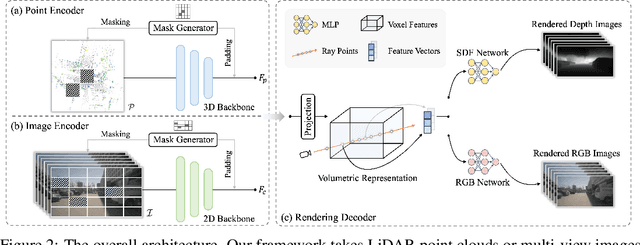

In the context of autonomous driving, the significance of effective feature learning is widely acknowledged. While conventional 3D self-supervised pre-training methods have shown widespread success, most methods follow the ideas originally designed for 2D images. In this paper, we present UniPAD, a novel self-supervised learning paradigm applying 3D volumetric differentiable rendering. UniPAD implicitly encodes 3D space, facilitating the reconstruction of continuous 3D shape structures and the intricate appearance characteristics of their 2D projections. The flexibility of our method enables seamless integration into both 2D and 3D frameworks, enabling a more holistic comprehension of the scenes. We manifest the feasibility and effectiveness of UniPAD by conducting extensive experiments on various downstream 3D tasks. Our method significantly improves lidar-, camera-, and lidar-camera-based baseline by 9.1, 7.7, and 6.9 NDS, respectively. Notably, our pre-training pipeline achieves 73.2 NDS for 3D object detection and 79.4 mIoU for 3D semantic segmentation on the nuScenes validation set, achieving state-of-the-art results in comparison with previous methods. The code will be available at https://github.com/Nightmare-n/UniPAD.
Few-Shot Domain Adaptation for Charge Prediction on Unprofessional Descriptions
Sep 29, 2023Recent works considering professional legal-linguistic style (PLLS) texts have shown promising results on the charge prediction task. However, unprofessional users also show an increasing demand on such a prediction service. There is a clear domain discrepancy between PLLS texts and non-PLLS texts expressed by those laypersons, which degrades the current SOTA models' performance on non-PLLS texts. A key challenge is the scarcity of non-PLLS data for most charge classes. This paper proposes a novel few-shot domain adaptation (FSDA) method named Disentangled Legal Content for Charge Prediction (DLCCP). Compared with existing FSDA works, which solely perform instance-level alignment without considering the negative impact of text style information existing in latent features, DLCCP (1) disentangles the content and style representations for better domain-invariant legal content learning with carefully designed optimization goals for content and style spaces and, (2) employs the constitutive elements knowledge of charges to extract and align element-level and instance-level content representations simultaneously. We contribute the first publicly available non-PLLS dataset named NCCP for developing layperson-friendly charge prediction models. Experiments on NCCP show the superiority of our methods over competitive baselines.
M$^3$CS: Multi-Target Masked Point Modeling with Learnable Codebook and Siamese Decoders
Sep 23, 2023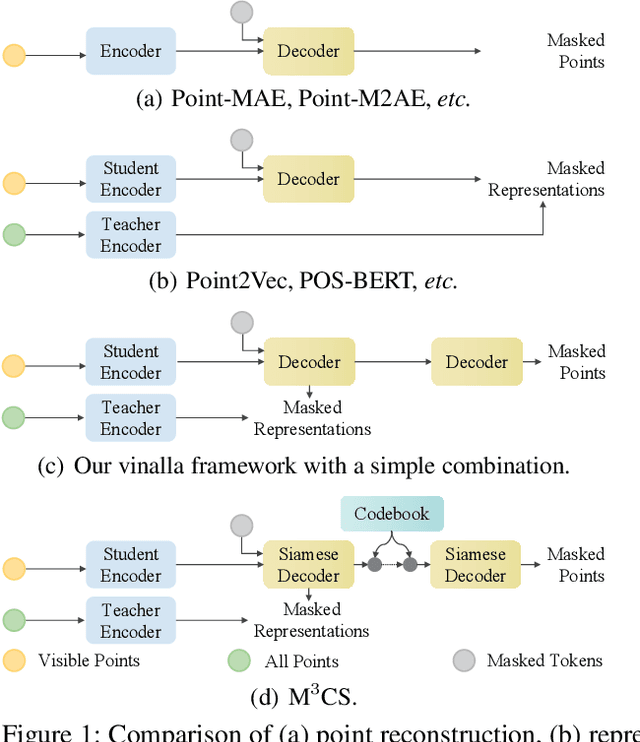

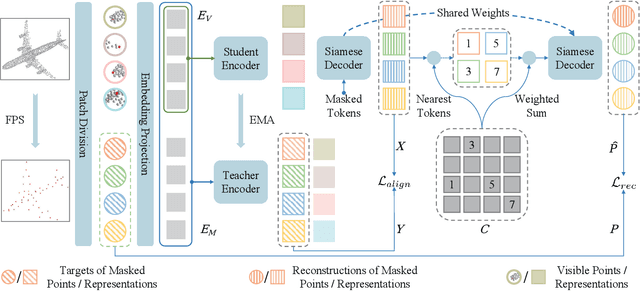
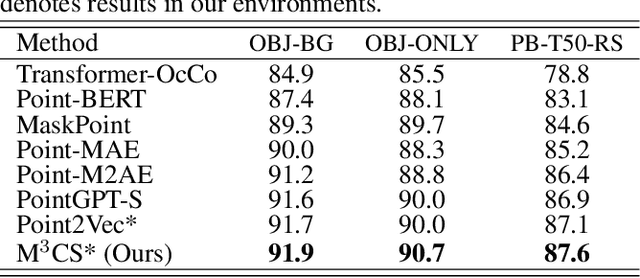
Masked point modeling has become a promising scheme of self-supervised pre-training for point clouds. Existing methods reconstruct either the original points or related features as the objective of pre-training. However, considering the diversity of downstream tasks, it is necessary for the model to have both low- and high-level representation modeling capabilities to capture geometric details and semantic contexts during pre-training. To this end, M$^3$CS is proposed to enable the model with the above abilities. Specifically, with masked point cloud as input, M$^3$CS introduces two decoders to predict masked representations and the original points simultaneously. While an extra decoder doubles parameters for the decoding process and may lead to overfitting, we propose siamese decoders to keep the amount of learnable parameters unchanged. Further, we propose an online codebook projecting continuous tokens into discrete ones before reconstructing masked points. In such way, we can enforce the decoder to take effect through the combinations of tokens rather than remembering each token. Comprehensive experiments show that M$^3$CS achieves superior performance at both classification and segmentation tasks, outperforming existing methods.
A Study of Unsupervised Evaluation Metrics for Practical and Automatic Domain Adaptation
Aug 01, 2023
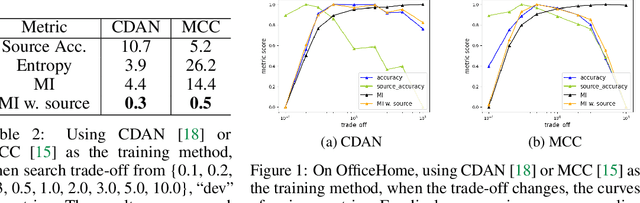
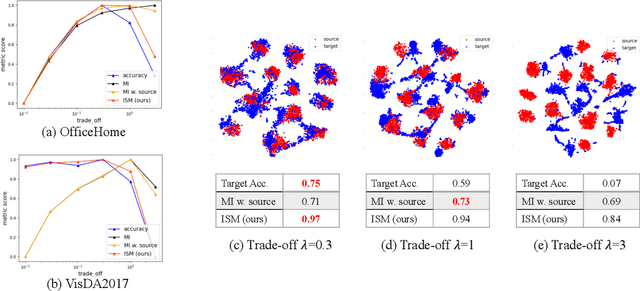
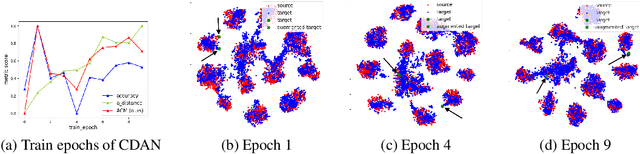
Unsupervised domain adaptation (UDA) methods facilitate the transfer of models to target domains without labels. However, these methods necessitate a labeled target validation set for hyper-parameter tuning and model selection. In this paper, we aim to find an evaluation metric capable of assessing the quality of a transferred model without access to target validation labels. We begin with the metric based on mutual information of the model prediction. Through empirical analysis, we identify three prevalent issues with this metric: 1) It does not account for the source structure. 2) It can be easily attacked. 3) It fails to detect negative transfer caused by the over-alignment of source and target features. To address the first two issues, we incorporate source accuracy into the metric and employ a new MLP classifier that is held out during training, significantly improving the result. To tackle the final issue, we integrate this enhanced metric with data augmentation, resulting in a novel unsupervised UDA metric called the Augmentation Consistency Metric (ACM). Additionally, we empirically demonstrate the shortcomings of previous experiment settings and conduct large-scale experiments to validate the effectiveness of our proposed metric. Furthermore, we employ our metric to automatically search for the optimal hyper-parameter set, achieving superior performance compared to manually tuned sets across four common benchmarks. Codes will be available soon.
SelFLoc: Selective Feature Fusion for Large-scale Point Cloud-based Place Recognition
Jun 05, 2023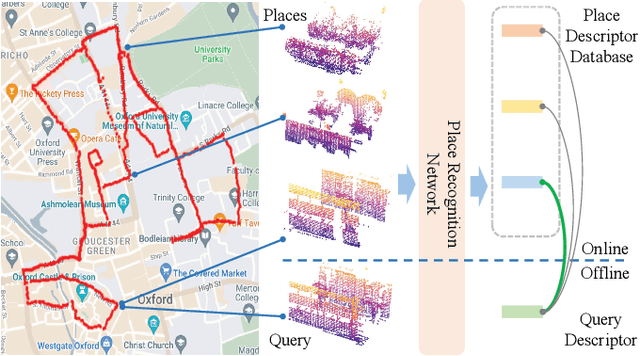
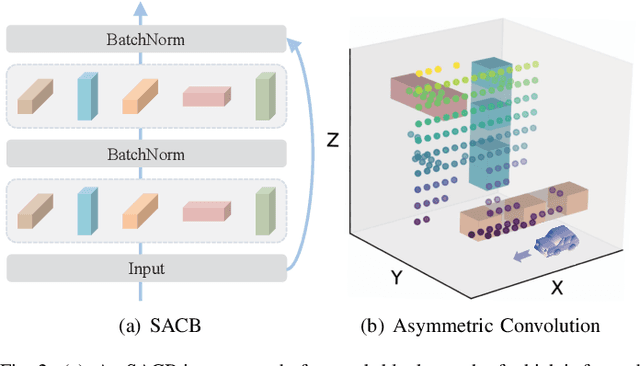
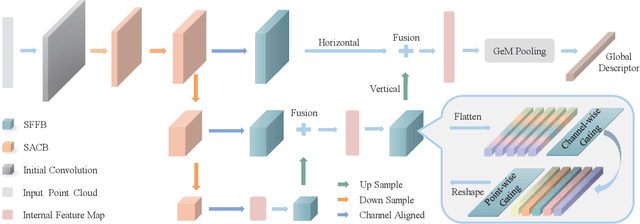

Point cloud-based place recognition is crucial for mobile robots and autonomous vehicles, especially when the global positioning sensor is not accessible. LiDAR points are scattered on the surface of objects and buildings, which have strong shape priors along different axes. To enhance message passing along particular axes, Stacked Asymmetric Convolution Block (SACB) is designed, which is one of the main contributions in this paper. Comprehensive experiments demonstrate that asymmetric convolution and its corresponding strategies employed by SACB can contribute to the more effective representation of point cloud feature. On this basis, Selective Feature Fusion Block (SFFB), which is formed by stacking point- and channel-wise gating layers in a predefined sequence, is proposed to selectively boost salient local features in certain key regions, as well as to align the features before fusion phase. SACBs and SFFBs are combined to construct a robust and accurate architecture for point cloud-based place recognition, which is termed SelFLoc. Comparative experimental results show that SelFLoc achieves the state-of-the-art (SOTA) performance on the Oxford and other three in-house benchmarks with an improvement of 1.6 absolute percentages on mean average recall@1.
PVT-SSD: Single-Stage 3D Object Detector with Point-Voxel Transformer
May 11, 2023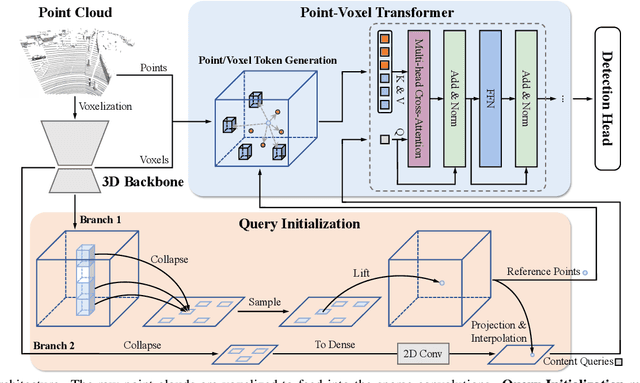
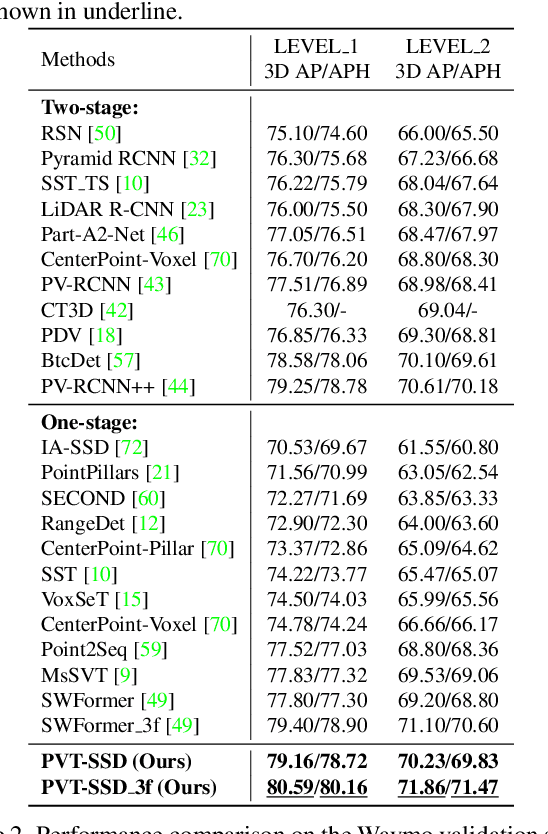
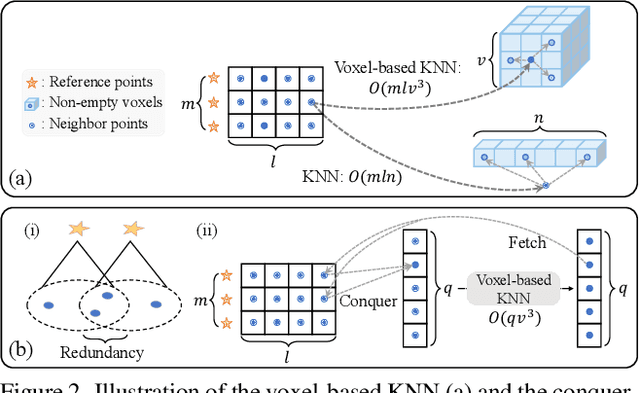
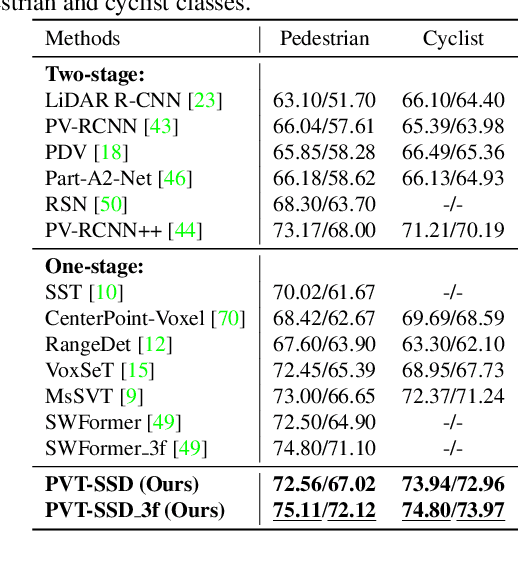
Recent Transformer-based 3D object detectors learn point cloud features either from point- or voxel-based representations. However, the former requires time-consuming sampling while the latter introduces quantization errors. In this paper, we present a novel Point-Voxel Transformer for single-stage 3D detection (PVT-SSD) that takes advantage of these two representations. Specifically, we first use voxel-based sparse convolutions for efficient feature encoding. Then, we propose a Point-Voxel Transformer (PVT) module that obtains long-range contexts in a cheap manner from voxels while attaining accurate positions from points. The key to associating the two different representations is our introduced input-dependent Query Initialization module, which could efficiently generate reference points and content queries. Then, PVT adaptively fuses long-range contextual and local geometric information around reference points into content queries. Further, to quickly find the neighboring points of reference points, we design the Virtual Range Image module, which generalizes the native range image to multi-sensor and multi-frame. The experiments on several autonomous driving benchmarks verify the effectiveness and efficiency of the proposed method. Code will be available at https://github.com/Nightmare-n/PVT-SSD.
Denoising Multi-modal Sequential Recommenders with Contrastive Learning
May 03, 2023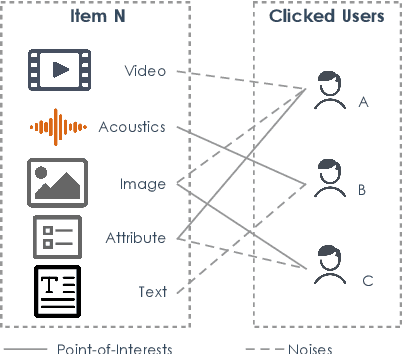

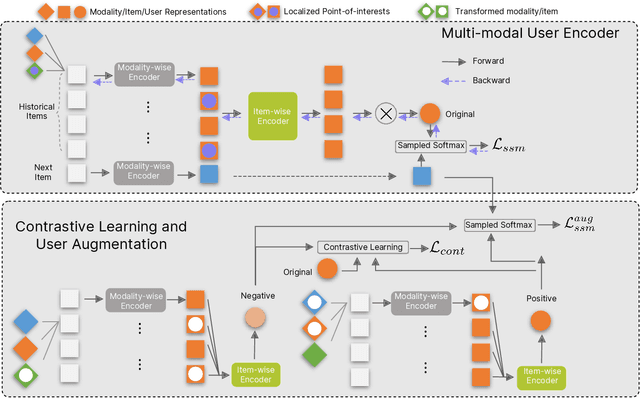
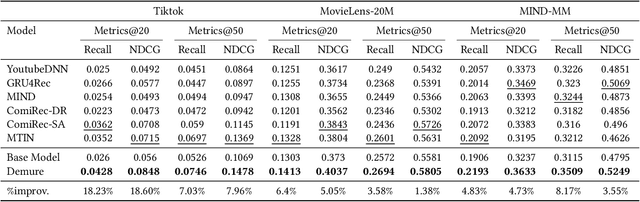
There is a rapidly-growing research interest in engaging users with multi-modal data for accurate user modeling on recommender systems. Existing multimedia recommenders have achieved substantial improvements by incorporating various modalities and devising delicate modules. However, when users decide to interact with items, most of them do not fully read the content of all modalities. We refer to modalities that directly cause users' behaviors as point-of-interests, which are important aspects to capture users' interests. In contrast, modalities that do not cause users' behaviors are potential noises and might mislead the learning of a recommendation model. Not surprisingly, little research in the literature has been devoted to denoising such potential noises due to the inaccessibility of users' explicit feedback on their point-of-interests. To bridge the gap, we propose a weakly-supervised framework based on contrastive learning for denoising multi-modal recommenders (dubbed Demure). In a weakly-supervised manner, Demure circumvents the requirement of users' explicit feedback and identifies the noises by analyzing the modalities of all interacted items from a given user.
CrossFormer++: A Versatile Vision Transformer Hinging on Cross-scale Attention
Mar 13, 2023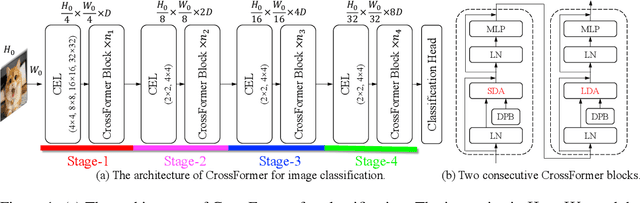
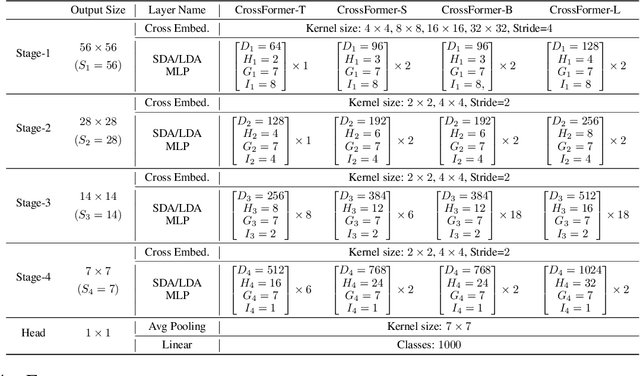
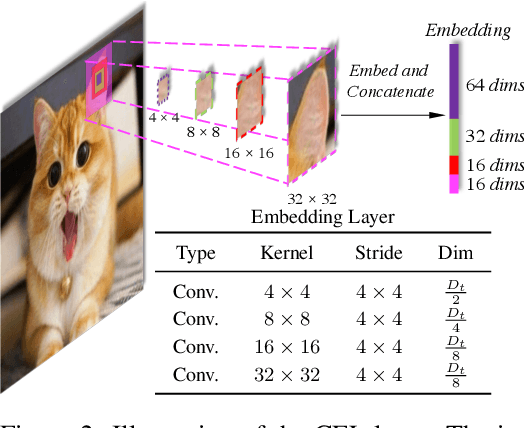
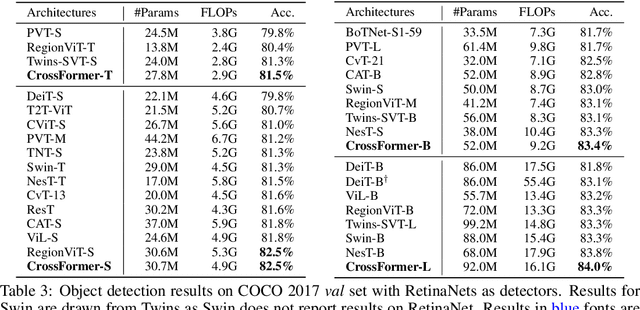
While features of different scales are perceptually important to visual inputs, existing vision transformers do not yet take advantage of them explicitly. To this end, we first propose a cross-scale vision transformer, CrossFormer. It introduces a cross-scale embedding layer (CEL) and a long-short distance attention (LSDA). On the one hand, CEL blends each token with multiple patches of different scales, providing the self-attention module itself with cross-scale features. On the other hand, LSDA splits the self-attention module into a short-distance one and a long-distance counterpart, which not only reduces the computational burden but also keeps both small-scale and large-scale features in the tokens. Moreover, through experiments on CrossFormer, we observe another two issues that affect vision transformers' performance, i.e. the enlarging self-attention maps and amplitude explosion. Thus, we further propose a progressive group size (PGS) paradigm and an amplitude cooling layer (ACL) to alleviate the two issues, respectively. The CrossFormer incorporating with PGS and ACL is called CrossFormer++. Extensive experiments show that CrossFormer++ outperforms the other vision transformers on image classification, object detection, instance segmentation, and semantic segmentation tasks. The code will be available at: https://github.com/cheerss/CrossFormer.