 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShixiang Tang
DetToolChain: A New Prompting Paradigm to Unleash Detection Ability of MLLM
Mar 19, 2024
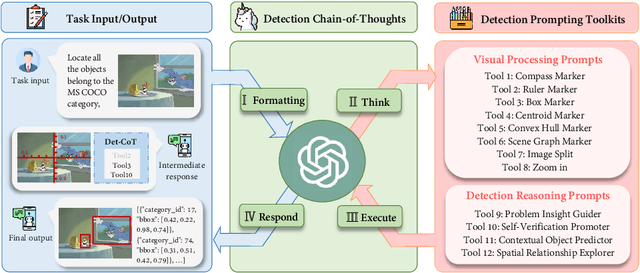

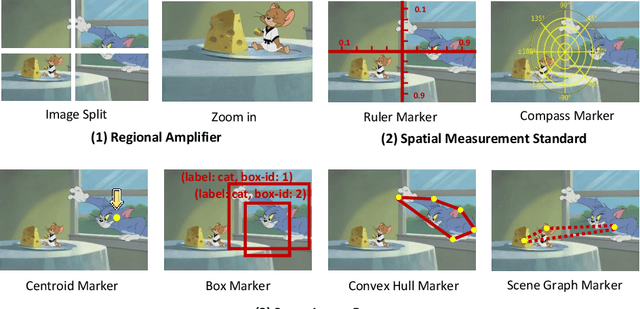
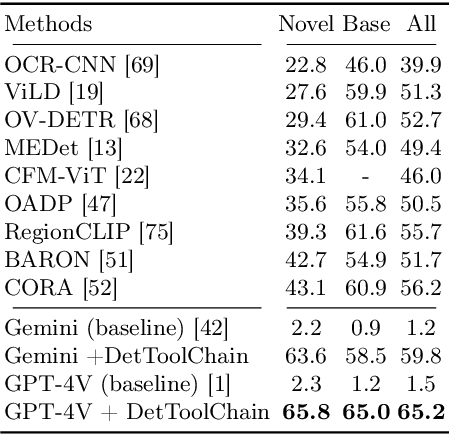
We present DetToolChain, a novel prompting paradigm, to unleash the zero-shot object detection ability of multimodal large language models (MLLMs), such as GPT-4V and Gemini. Our approach consists of a detection prompting toolkit inspired by high-precision detection priors and a new Chain-of-Thought to implement these prompts. Specifically, the prompts in the toolkit are designed to guide the MLLM to focus on regional information (e.g., zooming in), read coordinates according to measure standards (e.g., overlaying rulers and compasses), and infer from the contextual information (e.g., overlaying scene graphs). Building upon these tools, the new detection chain-of-thought can automatically decompose the task into simple subtasks, diagnose the predictions, and plan for progressive box refinements. The effectiveness of our framework is demonstrated across a spectrum of detection tasks, especially hard cases. Compared to existing state-of-the-art methods, GPT-4V with our DetToolChain improves state-of-the-art object detectors by +21.5% AP50 on MS COCO Novel class set for open-vocabulary detection, +24.23% Acc on RefCOCO val set for zero-shot referring expression comprehension, +14.5% AP on D-cube describe object detection FULL setting.
Agent3D-Zero: An Agent for Zero-shot 3D Understanding
Mar 18, 2024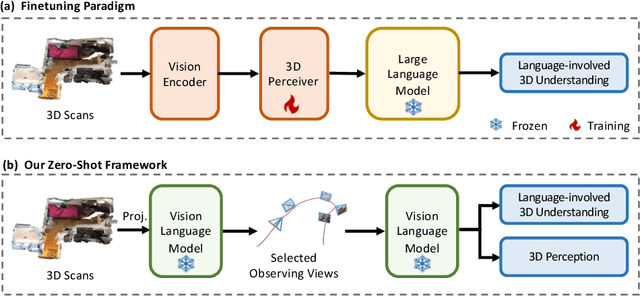
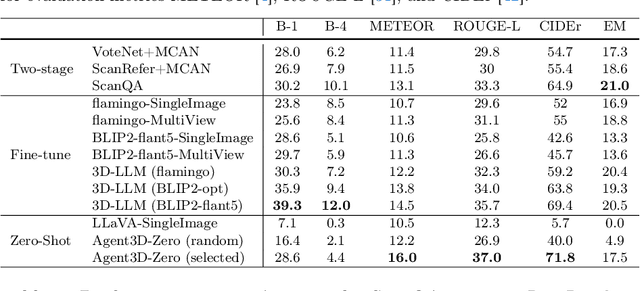
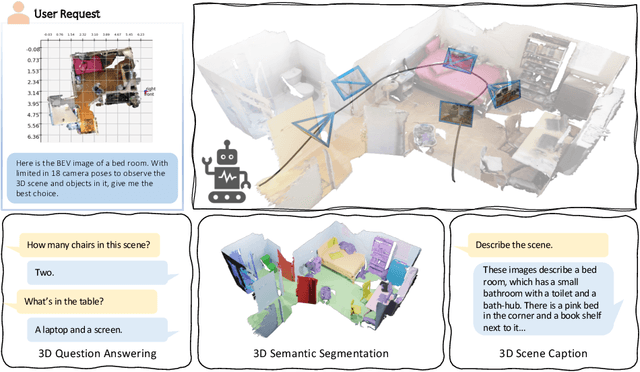
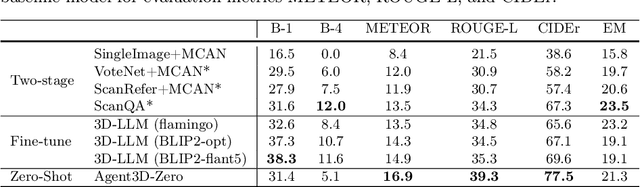
The ability to understand and reason the 3D real world is a crucial milestone towards artificial general intelligence. The current common practice is to finetune Large Language Models (LLMs) with 3D data and texts to enable 3D understanding. Despite their effectiveness, these approaches are inherently limited by the scale and diversity of the available 3D data. Alternatively, in this work, we introduce Agent3D-Zero, an innovative 3D-aware agent framework addressing the 3D scene understanding in a zero-shot manner. The essence of our approach centers on reconceptualizing the challenge of 3D scene perception as a process of understanding and synthesizing insights from multiple images, inspired by how our human beings attempt to understand 3D scenes. By consolidating this idea, we propose a novel way to make use of a Large Visual Language Model (VLM) via actively selecting and analyzing a series of viewpoints for 3D understanding. Specifically, given an input 3D scene, Agent3D-Zero first processes a bird's-eye view image with custom-designed visual prompts, then iteratively chooses the next viewpoints to observe and summarize the underlying knowledge. A distinctive advantage of Agent3D-Zero is the introduction of novel visual prompts, which significantly unleash the VLMs' ability to identify the most informative viewpoints and thus facilitate observing 3D scenes. Extensive experiments demonstrate the effectiveness of the proposed framework in understanding diverse and previously unseen 3D environments.
SCott: Accelerating Diffusion Models with Stochastic Consistency Distillation
Mar 03, 2024
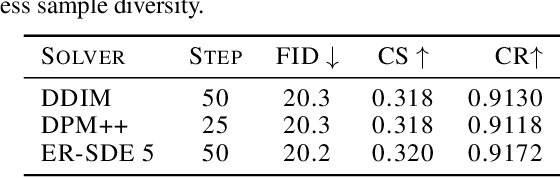

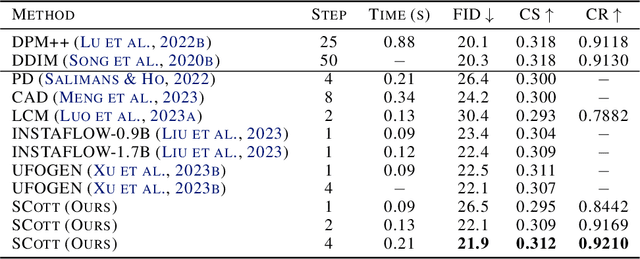
The iterative sampling procedure employed by diffusion models (DMs) often leads to significant inference latency. To address this, we propose Stochastic Consistency Distillation (SCott) to enable accelerated text-to-image generation, where high-quality generations can be achieved with just 1-2 sampling steps, and further improvements can be obtained by adding additional steps. In contrast to vanilla consistency distillation (CD) which distills the ordinary differential equation solvers-based sampling process of a pretrained teacher model into a student, SCott explores the possibility and validates the efficacy of integrating stochastic differential equation (SDE) solvers into CD to fully unleash the potential of the teacher. SCott is augmented with elaborate strategies to control the noise strength and sampling process of the SDE solver. An adversarial loss is further incorporated to strengthen the sample quality with rare sampling steps. Empirically, on the MSCOCO-2017 5K dataset with a Stable Diffusion-V1.5 teacher, SCott achieves an FID (Frechet Inceptio Distance) of 22.1, surpassing that (23.4) of the 1-step InstaFlow (Liu et al., 2023) and matching that of 4-step UFOGen (Xue et al., 2023b). Moreover, SCott can yield more diverse samples than other consistency models for high-resolution image generation (Luo et al., 2023a), with up to 16% improvement in a qualified metric. The code and checkpoints are coming soon.
A Comprehensive Survey on 3D Content Generation
Feb 02, 2024Recent years have witnessed remarkable advances in artificial intelligence generated content(AIGC), with diverse input modalities, e.g., text, image, video, audio and 3D. The 3D is the most close visual modality to real-world 3D environment and carries enormous knowledge. The 3D content generation shows both academic and practical values while also presenting formidable technical challenges. This review aims to consolidate developments within the burgeoning domain of 3D content generation. Specifically, a new taxonomy is proposed that categorizes existing approaches into three types: 3D native generative methods, 2D prior-based 3D generative methods, and hybrid 3D generative methods. The survey covers approximately 60 papers spanning the major techniques. Besides, we discuss limitations of current 3D content generation techniques, and point out open challenges as well as promising directions for future work. Accompanied with this survey, we have established a project website where the resources on 3D content generation research are provided. The project page is available at https://github.com/hitcslj/Awesome-AIGC-3D.
Hulk: A Universal Knowledge Translator for Human-Centric Tasks
Dec 05, 2023Human-centric perception tasks, e.g., human mesh recovery, pedestrian detection, skeleton-based action recognition, and pose estimation, have wide industrial applications, such as metaverse and sports analysis. There is a recent surge to develop human-centric foundation models that can benefit a broad range of human-centric perception tasks. While many human-centric foundation models have achieved success, most of them only excel in 2D vision tasks or require extensive fine-tuning for practical deployment in real-world scenarios. These limitations severely restrict their usability across various downstream tasks and situations. To tackle these problems, we present Hulk, the first multimodal human-centric generalist model, capable of addressing most of the mainstream tasks simultaneously without task-specific finetuning, covering 2D vision, 3D vision, skeleton-based, and vision-language tasks. The key to achieving this is condensing various task-specific heads into two general heads, one for discrete representations, e.g., languages, and the other for continuous representations, e.g., location coordinates. The outputs of two heads can be further stacked into four distinct input and output modalities. This uniform representation enables Hulk to treat human-centric tasks as modality translation, integrating knowledge across a wide range of tasks. To validate the effectiveness of our proposed method, we conduct comprehensive experiments on 11 benchmarks across 8 human-centric tasks. Experimental results surpass previous methods substantially, demonstrating the superiority of our proposed method. The code will be available on https://github.com/OpenGVLab/HumanBench.
UniPAD: A Universal Pre-training Paradigm for Autonomous Driving
Oct 12, 2023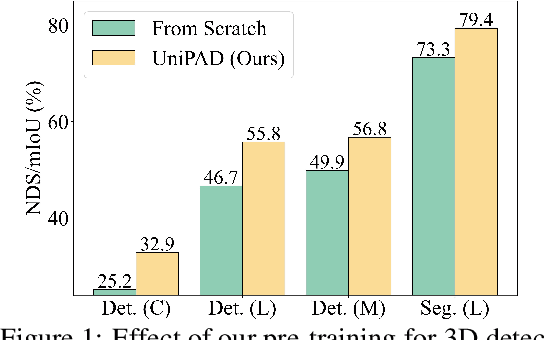
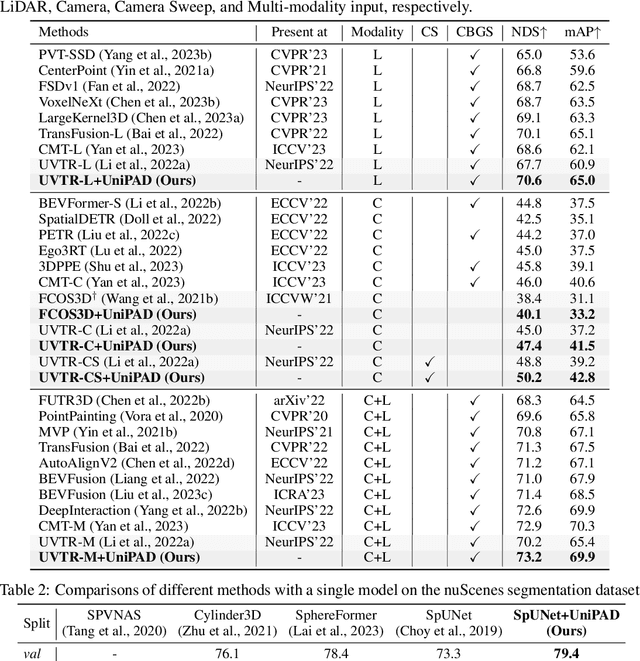
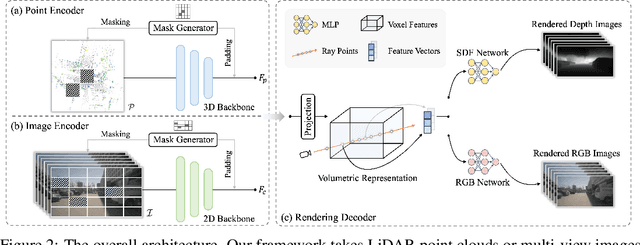

In the context of autonomous driving, the significance of effective feature learning is widely acknowledged. While conventional 3D self-supervised pre-training methods have shown widespread success, most methods follow the ideas originally designed for 2D images. In this paper, we present UniPAD, a novel self-supervised learning paradigm applying 3D volumetric differentiable rendering. UniPAD implicitly encodes 3D space, facilitating the reconstruction of continuous 3D shape structures and the intricate appearance characteristics of their 2D projections. The flexibility of our method enables seamless integration into both 2D and 3D frameworks, enabling a more holistic comprehension of the scenes. We manifest the feasibility and effectiveness of UniPAD by conducting extensive experiments on various downstream 3D tasks. Our method significantly improves lidar-, camera-, and lidar-camera-based baseline by 9.1, 7.7, and 6.9 NDS, respectively. Notably, our pre-training pipeline achieves 73.2 NDS for 3D object detection and 79.4 mIoU for 3D semantic segmentation on the nuScenes validation set, achieving state-of-the-art results in comparison with previous methods. The code will be available at https://github.com/Nightmare-n/UniPAD.
Relation-Aware Distribution Representation Network for Person Clustering with Multiple Modalities
Aug 01, 2023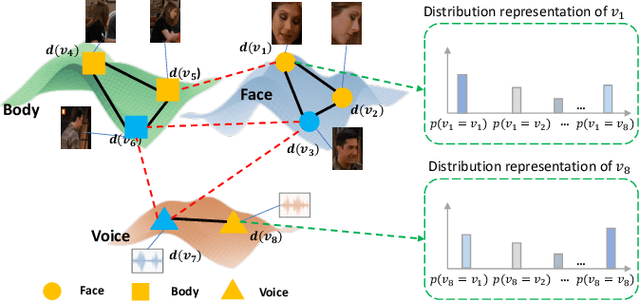
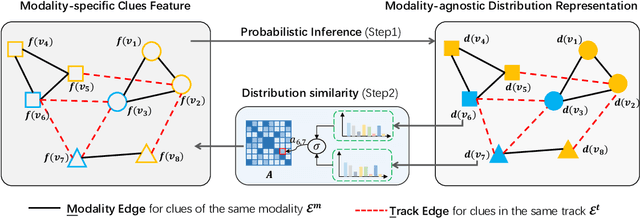


Person clustering with multi-modal clues, including faces, bodies, and voices, is critical for various tasks, such as movie parsing and identity-based movie editing. Related methods such as multi-view clustering mainly project multi-modal features into a joint feature space. However, multi-modal clue features are usually rather weakly correlated due to the semantic gap from the modality-specific uniqueness. As a result, these methods are not suitable for person clustering. In this paper, we propose a Relation-Aware Distribution representation Network (RAD-Net) to generate a distribution representation for multi-modal clues. The distribution representation of a clue is a vector consisting of the relation between this clue and all other clues from all modalities, thus being modality agnostic and good for person clustering. Accordingly, we introduce a graph-based method to construct distribution representation and employ a cyclic update policy to refine distribution representation progressively. Our method achieves substantial improvements of +6% and +8.2% in F-score on the Video Person-Clustering Dataset (VPCD) and VoxCeleb2 multi-view clustering dataset, respectively. Codes will be released publicly upon acceptance.
Retrieve Anyone: A General-purpose Person Re-identification Task with Instructions
Jul 04, 2023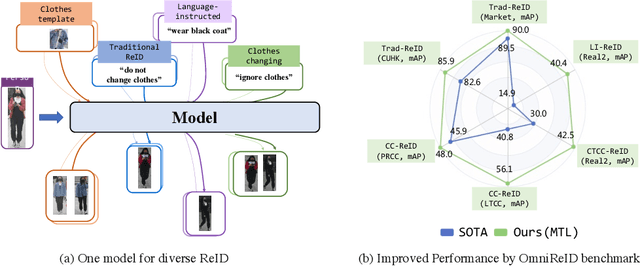
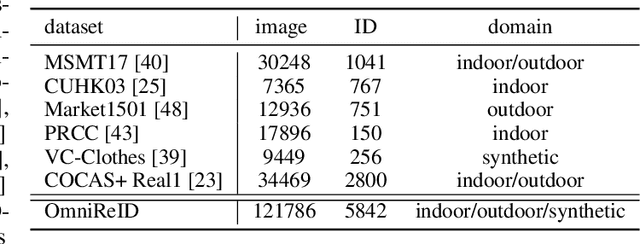
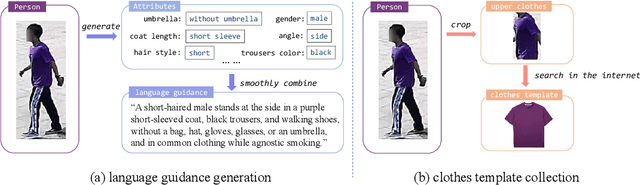
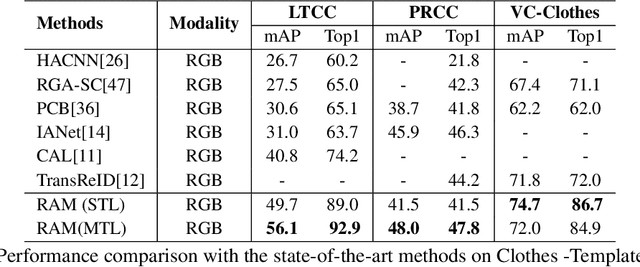
Human intelligence can retrieve any person according to both visual and language descriptions. However, the current computer vision community studies specific person re-identification (ReID) tasks in different scenarios separately, which limits the applications in the real world. This paper strives to resolve this problem by proposing a new instruct-ReID task that requires the model to retrieve images according to the given image or language instructions.Our instruct-ReID is a more general ReID setting, where existing ReID tasks can be viewed as special cases by designing different instructions. We propose a large-scale OmniReID benchmark and an adaptive triplet loss as a baseline method to facilitate research in this new setting. Experimental results show that the baseline model trained on our OmniReID benchmark can improve +0.6%, +1.4%, 0.2% mAP on Market1501, CUHK03, MSMT17 for traditional ReID, +0.8%, +2.0%, +13.4% mAP on PRCC, VC-Clothes, LTCC for clothes-changing ReID, +11.7% mAP on COCAS+ real2 for clothestemplate based clothes-changing ReID when using only RGB images, +25.4% mAP on COCAS+ real2 for our newly defined language-instructed ReID. The dataset, model, and code will be available at https://github.com/hwz-zju/Instruct-ReID.
MotionGPT: Finetuned LLMs are General-Purpose Motion Generators
Jun 19, 2023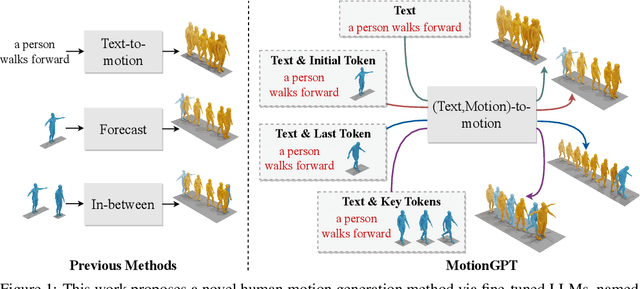
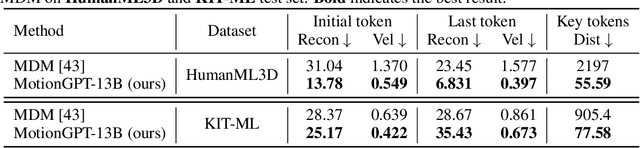
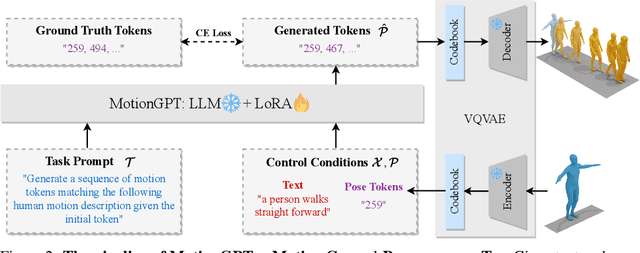
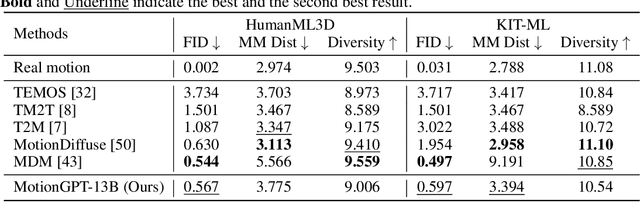
Generating realistic human motion from given action descriptions has experienced significant advancements because of the emerging requirement of digital humans. While recent works have achieved impressive results in generating motion directly from textual action descriptions, they often support only a single modality of the control signal, which limits their application in the real digital human industry. This paper presents a Motion General-Purpose generaTor (MotionGPT) that can use multimodal control signals, e.g., text and single-frame poses, for generating consecutive human motions by treating multimodal signals as special input tokens in large language models (LLMs). Specifically, we first quantize multimodal control signals into discrete codes and then formulate them in a unified prompt instruction to ask the LLMs to generate the motion answer. Our MotionGPT demonstrates a unified human motion generation model with multimodal control signals by tuning a mere 0.4% of LLM parameters. To the best of our knowledge, MotionGPT is the first method to generate human motion by multimodal control signals, which we hope can shed light on this new direction. Codes shall be released upon acceptance.
UniHCP: A Unified Model for Human-Centric Perceptions
Mar 19, 2023
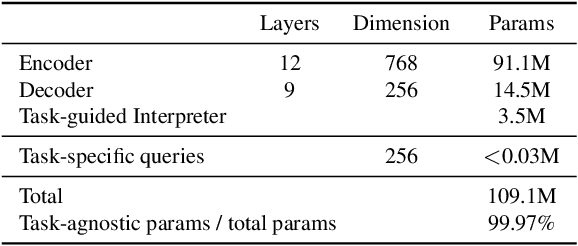
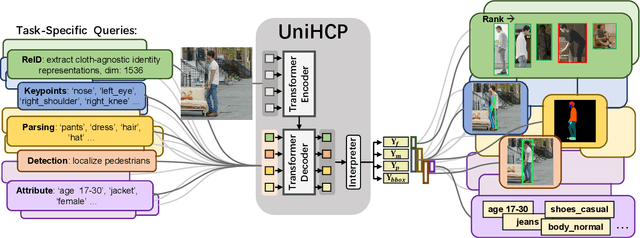
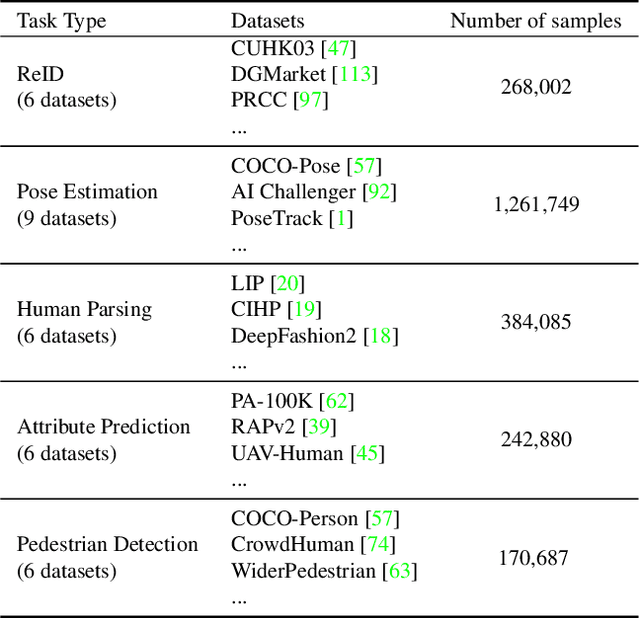
Human-centric perceptions (e.g., pose estimation, human parsing, pedestrian detection, person re-identification, etc.) play a key role in industrial applications of visual models. While specific human-centric tasks have their own relevant semantic aspect to focus on, they also share the same underlying semantic structure of the human body. However, few works have attempted to exploit such homogeneity and design a general-propose model for human-centric tasks. In this work, we revisit a broad range of human-centric tasks and unify them in a minimalist manner. We propose UniHCP, a Unified Model for Human-Centric Perceptions, which unifies a wide range of human-centric tasks in a simplified end-to-end manner with the plain vision transformer architecture. With large-scale joint training on 33 human-centric datasets, UniHCP can outperform strong baselines on several in-domain and downstream tasks by direct evaluation. When adapted to a specific task, UniHCP achieves new SOTAs on a wide range of human-centric tasks, e.g., 69.8 mIoU on CIHP for human parsing, 86.18 mA on PA-100K for attribute prediction, 90.3 mAP on Market1501 for ReID, and 85.8 JI on CrowdHuman for pedestrian detection, performing better than specialized models tailored for each task.