 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeizhen He
Hulk: A Universal Knowledge Translator for Human-Centric Tasks
Dec 05, 2023
Human-centric perception tasks, e.g., human mesh recovery, pedestrian detection, skeleton-based action recognition, and pose estimation, have wide industrial applications, such as metaverse and sports analysis. There is a recent surge to develop human-centric foundation models that can benefit a broad range of human-centric perception tasks. While many human-centric foundation models have achieved success, most of them only excel in 2D vision tasks or require extensive fine-tuning for practical deployment in real-world scenarios. These limitations severely restrict their usability across various downstream tasks and situations. To tackle these problems, we present Hulk, the first multimodal human-centric generalist model, capable of addressing most of the mainstream tasks simultaneously without task-specific finetuning, covering 2D vision, 3D vision, skeleton-based, and vision-language tasks. The key to achieving this is condensing various task-specific heads into two general heads, one for discrete representations, e.g., languages, and the other for continuous representations, e.g., location coordinates. The outputs of two heads can be further stacked into four distinct input and output modalities. This uniform representation enables Hulk to treat human-centric tasks as modality translation, integrating knowledge across a wide range of tasks. To validate the effectiveness of our proposed method, we conduct comprehensive experiments on 11 benchmarks across 8 human-centric tasks. Experimental results surpass previous methods substantially, demonstrating the superiority of our proposed method. The code will be available on https://github.com/OpenGVLab/HumanBench.
Retrieve Anyone: A General-purpose Person Re-identification Task with Instructions
Jul 04, 2023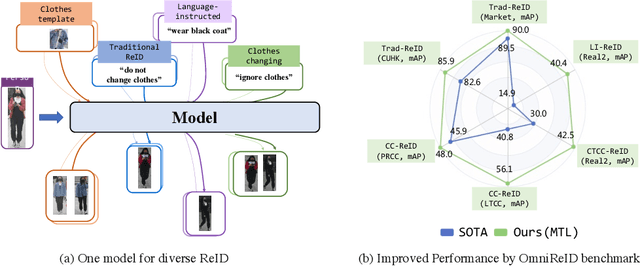
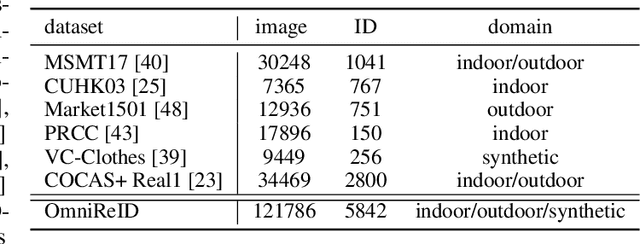
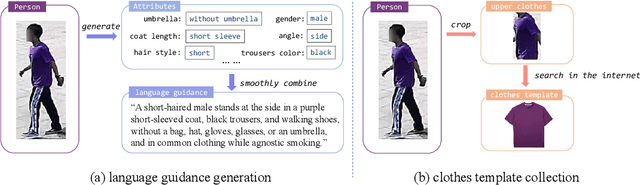
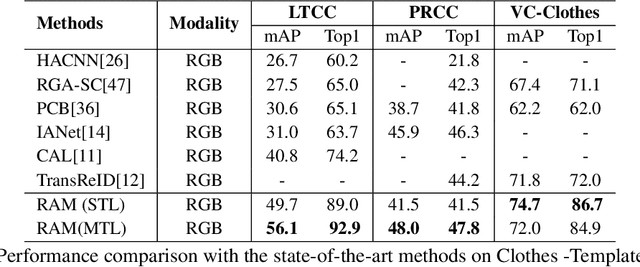
Human intelligence can retrieve any person according to both visual and language descriptions. However, the current computer vision community studies specific person re-identification (ReID) tasks in different scenarios separately, which limits the applications in the real world. This paper strives to resolve this problem by proposing a new instruct-ReID task that requires the model to retrieve images according to the given image or language instructions.Our instruct-ReID is a more general ReID setting, where existing ReID tasks can be viewed as special cases by designing different instructions. We propose a large-scale OmniReID benchmark and an adaptive triplet loss as a baseline method to facilitate research in this new setting. Experimental results show that the baseline model trained on our OmniReID benchmark can improve +0.6%, +1.4%, 0.2% mAP on Market1501, CUHK03, MSMT17 for traditional ReID, +0.8%, +2.0%, +13.4% mAP on PRCC, VC-Clothes, LTCC for clothes-changing ReID, +11.7% mAP on COCAS+ real2 for clothestemplate based clothes-changing ReID when using only RGB images, +25.4% mAP on COCAS+ real2 for our newly defined language-instructed ReID. The dataset, model, and code will be available at https://github.com/hwz-zju/Instruct-ReID.