 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRui Zhao
X-Light: Cross-City Traffic Signal Control Using Transformer on Transformer as Meta Multi-Agent Reinforcement Learner
Apr 18, 2024
The effectiveness of traffic light control has been significantly improved by current reinforcement learning-based approaches via better cooperation among multiple traffic lights. However, a persisting issue remains: how to obtain a multi-agent traffic signal control algorithm with remarkable transferability across diverse cities? In this paper, we propose a Transformer on Transformer (TonT) model for cross-city meta multi-agent traffic signal control, named as X-Light: We input the full Markov Decision Process trajectories, and the Lower Transformer aggregates the states, actions, rewards among the target intersection and its neighbors within a city, and the Upper Transformer learns the general decision trajectories across different cities. This dual-level approach bolsters the model's robust generalization and transferability. Notably, when directly transferring to unseen scenarios, ours surpasses all baseline methods with +7.91% on average, and even +16.3% in some cases, yielding the best results.
Balancing Speciality and Versatility: a Coarse to Fine Framework for Supervised Fine-tuning Large Language Model
Apr 16, 2024Aligned Large Language Models (LLMs) showcase remarkable versatility, capable of handling diverse real-world tasks. Meanwhile, aligned LLMs are also expected to exhibit speciality, excelling in specific applications. However, fine-tuning with extra data, a common practice to gain speciality, often leads to catastrophic forgetting (CF) of previously acquired versatility, hindering the model's performance across diverse tasks. In response to this challenge, we propose CoFiTune, a coarse to fine framework in an attempt to strike the balance between speciality and versatility. At the coarse-grained level, an empirical tree-search algorithm is utilized to pinpoint and update specific modules that are crucial for speciality, while keeping other parameters frozen; at the fine-grained level, a soft-masking mechanism regulates the update to the LLMs, mitigating the CF issue without harming speciality. In an overall evaluation of both speciality and versatility, CoFiTune consistently outperforms baseline methods across diverse tasks and model scales. Compared to the full-parameter SFT, CoFiTune leads to about 14% versatility improvement and marginal speciality loss on a 13B model. Lastly, based on further analysis, we provide a speculative insight into the information forwarding process in LLMs, which helps explain the effectiveness of the proposed method. The code is available at https://github.com/rattlesnakey/CoFiTune.
Sparse Global Matching for Video Frame Interpolation with Large Motion
Apr 15, 2024Large motion poses a critical challenge in Video Frame Interpolation (VFI) task. Existing methods are often constrained by limited receptive fields, resulting in sub-optimal performance when handling scenarios with large motion. In this paper, we introduce a new pipeline for VFI, which can effectively integrate global-level information to alleviate issues associated with large motion. Specifically, we first estimate a pair of initial intermediate flows using a high-resolution feature map for extracting local details. Then, we incorporate a sparse global matching branch to compensate for flow estimation, which consists of identifying flaws in initial flows and generating sparse flow compensation with a global receptive field. Finally, we adaptively merge the initial flow estimation with global flow compensation, yielding a more accurate intermediate flow. To evaluate the effectiveness of our method in handling large motion, we carefully curate a more challenging subset from commonly used benchmarks. Our method demonstrates the state-of-the-art performance on these VFI subsets with large motion.
Xiwu: A Basis Flexible and Learnable LLM for High Energy Physics
Apr 08, 2024Large Language Models (LLMs) are undergoing a period of rapid updates and changes, with state-of-the-art (SOTA) model frequently being replaced. When applying LLMs to a specific scientific field, it's challenging to acquire unique domain knowledge while keeping the model itself advanced. To address this challenge, a sophisticated large language model system named as Xiwu has been developed, allowing you switch between the most advanced foundation models and quickly teach the model domain knowledge. In this work, we will report on the best practices for applying LLMs in the field of high-energy physics (HEP), including: a seed fission technology is proposed and some data collection and cleaning tools are developed to quickly obtain domain AI-Ready dataset; a just-in-time learning system is implemented based on the vector store technology; an on-the-fly fine-tuning system has been developed to facilitate rapid training under a specified foundation model. The results show that Xiwu can smoothly switch between foundation models such as LLaMA, Vicuna, ChatGLM and Grok-1. The trained Xiwu model is significantly outperformed the benchmark model on the HEP knowledge question-and-answering and code generation. This strategy significantly enhances the potential for growth of our model's performance, with the hope of surpassing GPT-4 as it evolves with the development of open-source models. This work provides a customized LLM for the field of HEP, while also offering references for applying LLM to other fields, the corresponding codes are available on Github.
Advanced Long-Content Speech Recognition With Factorized Neural Transducer
Mar 20, 2024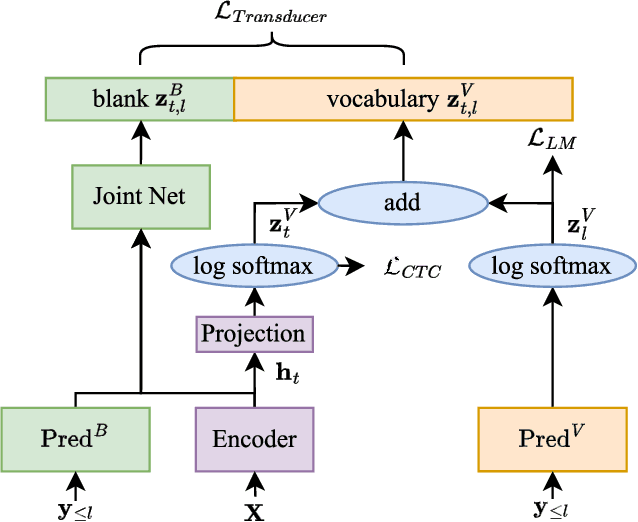
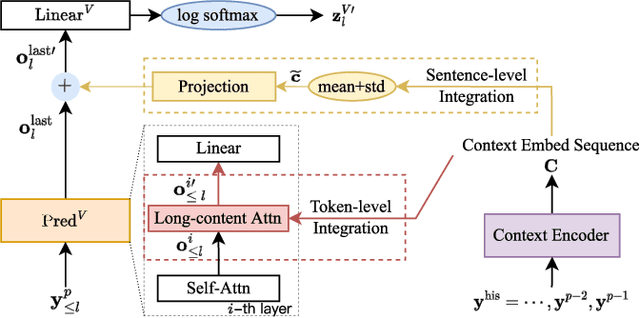
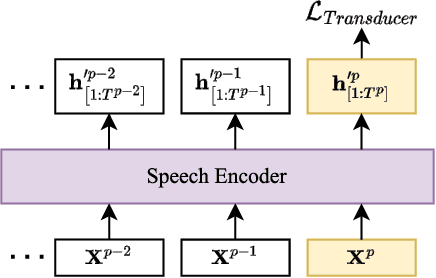
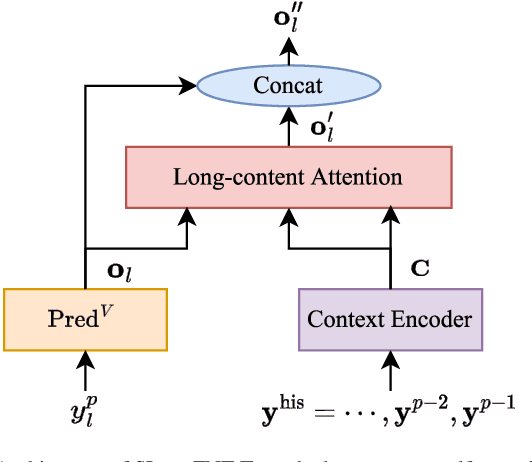
In this paper, we propose two novel approaches, which integrate long-content information into the factorized neural transducer (FNT) based architecture in both non-streaming (referred to as LongFNT ) and streaming (referred to as SLongFNT ) scenarios. We first investigate whether long-content transcriptions can improve the vanilla conformer transducer (C-T) models. Our experiments indicate that the vanilla C-T models do not exhibit improved performance when utilizing long-content transcriptions, possibly due to the predictor network of C-T models not functioning as a pure language model. Instead, FNT shows its potential in utilizing long-content information, where we propose the LongFNT model and explore the impact of long-content information in both text (LongFNT-Text) and speech (LongFNT-Speech). The proposed LongFNT-Text and LongFNT-Speech models further complement each other to achieve better performance, with transcription history proving more valuable to the model. The effectiveness of our LongFNT approach is evaluated on LibriSpeech and GigaSpeech corpora, and obtains relative 19% and 12% word error rate reduction, respectively. Furthermore, we extend the LongFNT model to the streaming scenario, which is named SLongFNT , consisting of SLongFNT-Text and SLongFNT-Speech approaches to utilize long-content text and speech information. Experiments show that the proposed SLongFNT model achieves relative 26% and 17% WER reduction on LibriSpeech and GigaSpeech respectively while keeping a good latency, compared to the FNT baseline. Overall, our proposed LongFNT and SLongFNT highlight the significance of considering long-content speech and transcription knowledge for improving both non-streaming and streaming speech recognition systems.
* Accepted by TASLP 2024
PET-SQL: A Prompt-enhanced Two-stage Text-to-SQL Framework with Cross-consistency
Mar 18, 2024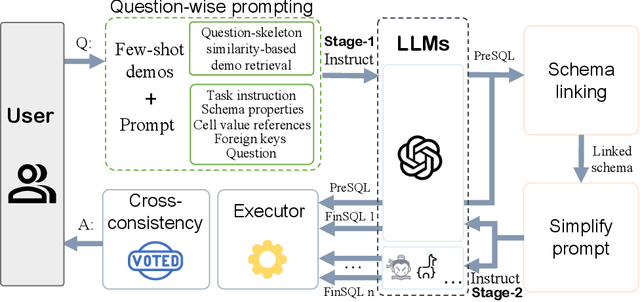

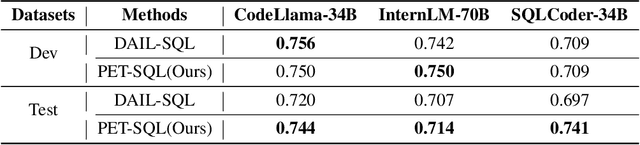
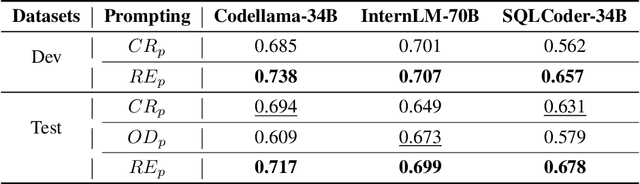
Recent advancements in Text-to-SQL (Text2SQL) emphasize stimulating the large language models (LLM) on in-context learning, achieving significant results. Nevertheless, they face challenges when dealing with verbose database information and complex user intentions. This paper presents a two-stage framework to enhance the performance of current LLM-based natural language to SQL systems. We first introduce a novel prompt representation, called reference-enhanced representation, which includes schema information and randomly sampled cell values from tables to instruct LLMs in generating SQL queries. Then, in the first stage, question-SQL pairs are retrieved as few-shot demonstrations, prompting the LLM to generate a preliminary SQL (PreSQL). After that, the mentioned entities in PreSQL are parsed to conduct schema linking, which can significantly compact the useful information. In the second stage, with the linked schema, we simplify the prompt's schema information and instruct the LLM to produce the final SQL. Finally, as the post-refinement module, we propose using cross-consistency across different LLMs rather than self-consistency within a particular LLM. Our methods achieve new SOTA results on the Spider benchmark, with an execution accuracy of 87.6%.
Deep Reinforcement Learning-based Large-scale Robot Exploration
Mar 16, 2024
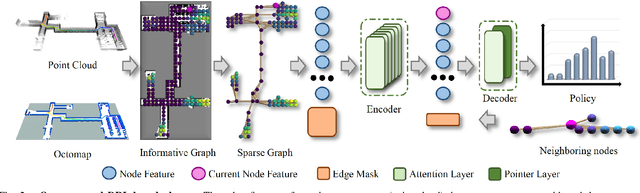
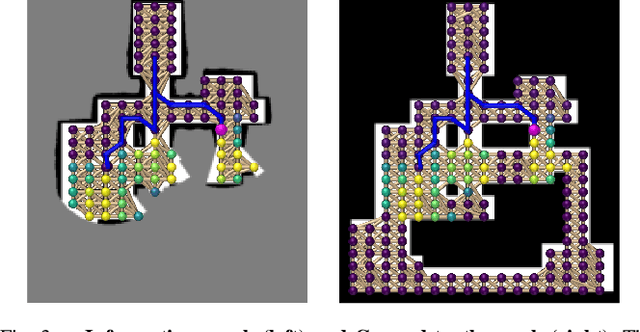
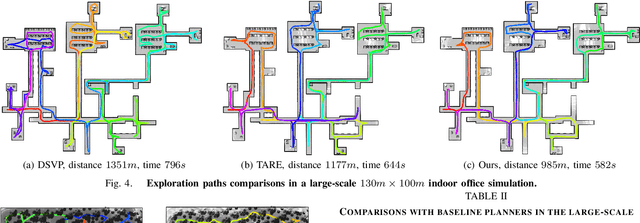
In this work, we propose a deep reinforcement learning (DRL) based reactive planner to solve large-scale Lidar-based autonomous robot exploration problems in 2D action space. Our DRL-based planner allows the agent to reactively plan its exploration path by making implicit predictions about unknown areas, based on a learned estimation of the underlying transition model of the environment. To this end, our approach relies on learned attention mechanisms for their powerful ability to capture long-term dependencies at different spatial scales to reason about the robot's entire belief over known areas. Our approach relies on ground truth information (i.e., privileged learning) to guide the environment estimation during training, as well as on a graph rarefaction algorithm, which allows models trained in small-scale environments to scale to large-scale ones. Simulation results show that our model exhibits better exploration efficiency (12% in path length, 6% in makespan) and lower planning time (60%) than the state-of-the-art planners in a 130m x 100m benchmark scenario. We also validate our learned model on hardware.
SocialGenPod: Privacy-Friendly Generative AI Social Web Applications with Decentralised Personal Data Stores
Mar 15, 2024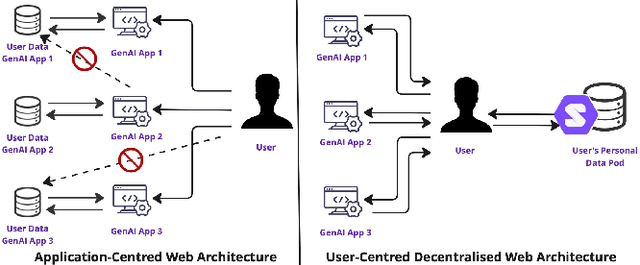
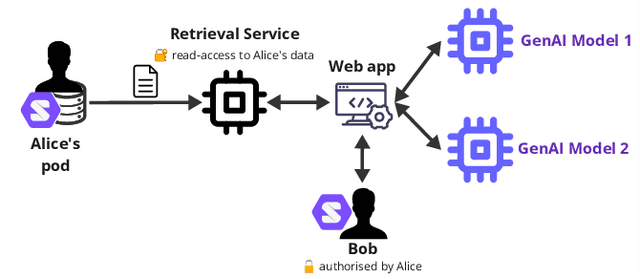
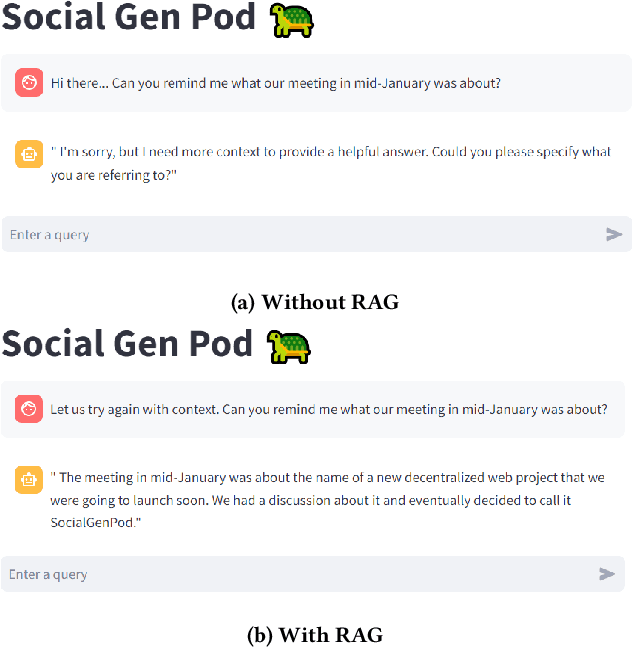
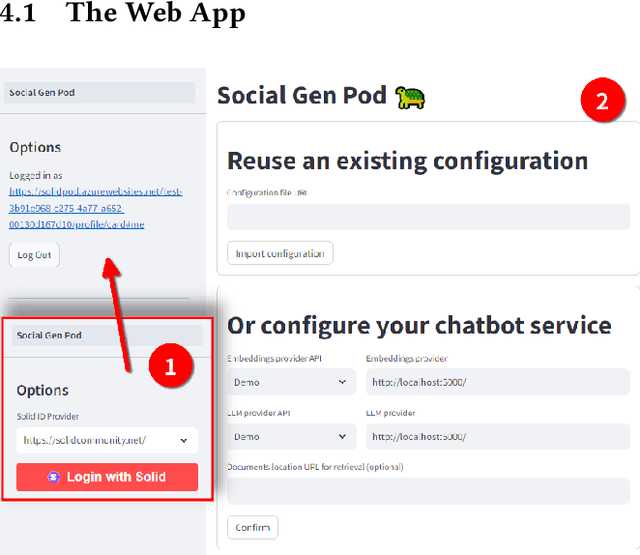
We present SocialGenPod, a decentralised and privacy-friendly way of deploying generative AI Web applications. Unlike centralised Web and data architectures that keep user data tied to application and service providers, we show how one can use Solid -- a decentralised Web specification -- to decouple user data from generative AI applications. We demonstrate SocialGenPod using a prototype that allows users to converse with different Large Language Models, optionally leveraging Retrieval Augmented Generation to generate answers grounded in private documents stored in any Solid Pod that the user is allowed to access, directly or indirectly. SocialGenPod makes use of Solid access control mechanisms to give users full control of determining who has access to data stored in their Pods. SocialGenPod keeps all user data (chat history, app configuration, personal documents, etc) securely in the user's personal Pod; separate from specific model or application providers. Besides better privacy controls, this approach also enables portability across different services and applications. Finally, we discuss challenges, posed by the large compute requirements of state-of-the-art models, that future research in this area should address. Our prototype is open-source and available at: https://github.com/Vidminas/socialgenpod/.
DragAnything: Motion Control for Anything using Entity Representation
Mar 15, 2024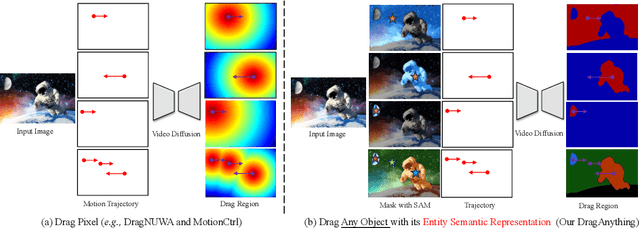

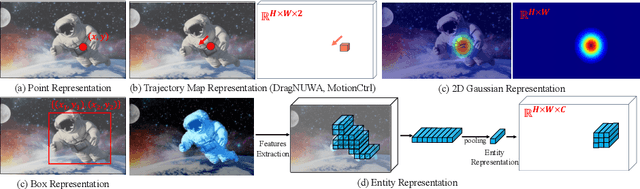

We introduce DragAnything, which utilizes a entity representation to achieve motion control for any object in controllable video generation. Comparison to existing motion control methods, DragAnything offers several advantages. Firstly, trajectory-based is more userfriendly for interaction, when acquiring other guidance signals (e.g., masks, depth maps) is labor-intensive. Users only need to draw a line (trajectory) during interaction. Secondly, our entity representation serves as an open-domain embedding capable of representing any object, enabling the control of motion for diverse entities, including background. Lastly, our entity representation allows simultaneous and distinct motion control for multiple objects. Extensive experiments demonstrate that our DragAnything achieves state-of-the-art performance for FVD, FID, and User Study, particularly in terms of object motion control, where our method surpasses the previous methods (e.g., DragNUWA) by 26% in human voting.