 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHengyuan Zhang
SemVecNet: Generalizable Vector Map Generation for Arbitrary Sensor Configurations
Apr 30, 2024
Vector maps are essential in autonomous driving for tasks like localization and planning, yet their creation and maintenance are notably costly. While recent advances in online vector map generation for autonomous vehicles are promising, current models lack adaptability to different sensor configurations. They tend to overfit to specific sensor poses, leading to decreased performance and higher retraining costs. This limitation hampers their practical use in real-world applications. In response to this challenge, we propose a modular pipeline for vector map generation with improved generalization to sensor configurations. The pipeline leverages probabilistic semantic mapping to generate a bird's-eye-view (BEV) semantic map as an intermediate representation. This intermediate representation is then converted to a vector map using the MapTRv2 decoder. By adopting a BEV semantic map robust to different sensor configurations, our proposed approach significantly improves the generalization performance. We evaluate the model on datasets with sensor configurations not used during training. Our evaluation sets includes larger public datasets, and smaller scale private data collected on our platform. Our model generalizes significantly better than the state-of-the-art methods.
Balancing Speciality and Versatility: a Coarse to Fine Framework for Supervised Fine-tuning Large Language Model
Apr 16, 2024Aligned Large Language Models (LLMs) showcase remarkable versatility, capable of handling diverse real-world tasks. Meanwhile, aligned LLMs are also expected to exhibit speciality, excelling in specific applications. However, fine-tuning with extra data, a common practice to gain speciality, often leads to catastrophic forgetting (CF) of previously acquired versatility, hindering the model's performance across diverse tasks. In response to this challenge, we propose CoFiTune, a coarse to fine framework in an attempt to strike the balance between speciality and versatility. At the coarse-grained level, an empirical tree-search algorithm is utilized to pinpoint and update specific modules that are crucial for speciality, while keeping other parameters frozen; at the fine-grained level, a soft-masking mechanism regulates the update to the LLMs, mitigating the CF issue without harming speciality. In an overall evaluation of both speciality and versatility, CoFiTune consistently outperforms baseline methods across diverse tasks and model scales. Compared to the full-parameter SFT, CoFiTune leads to about 14% versatility improvement and marginal speciality loss on a 13B model. Lastly, based on further analysis, we provide a speculative insight into the information forwarding process in LLMs, which helps explain the effectiveness of the proposed method. The code is available at https://github.com/rattlesnakey/CoFiTune.
Incremental Residual Concept Bottleneck Models
Apr 13, 2024Concept Bottleneck Models (CBMs) map the black-box visual representations extracted by deep neural networks onto a set of interpretable concepts and use the concepts to make predictions, enhancing the transparency of the decision-making process. Multimodal pre-trained models can match visual representations with textual concept embeddings, allowing for obtaining the interpretable concept bottleneck without the expertise concept annotations. Recent research has focused on the concept bank establishment and the high-quality concept selection. However, it is challenging to construct a comprehensive concept bank through humans or large language models, which severely limits the performance of CBMs. In this work, we propose the Incremental Residual Concept Bottleneck Model (Res-CBM) to address the challenge of concept completeness. Specifically, the residual concept bottleneck model employs a set of optimizable vectors to complete missing concepts, then the incremental concept discovery module converts the complemented vectors with unclear meanings into potential concepts in the candidate concept bank. Our approach can be applied to any user-defined concept bank, as a post-hoc processing method to enhance the performance of any CBMs. Furthermore, to measure the descriptive efficiency of CBMs, the Concept Utilization Efficiency (CUE) metric is proposed. Experiments show that the Res-CBM outperforms the current state-of-the-art methods in terms of both accuracy and efficiency and achieves comparable performance to black-box models across multiple datasets.
Understanding Multimodal Deep Neural Networks: A Concept Selection View
Apr 13, 2024The multimodal deep neural networks, represented by CLIP, have generated rich downstream applications owing to their excellent performance, thus making understanding the decision-making process of CLIP an essential research topic. Due to the complex structure and the massive pre-training data, it is often regarded as a black-box model that is too difficult to understand and interpret. Concept-based models map the black-box visual representations extracted by deep neural networks onto a set of human-understandable concepts and use the concepts to make predictions, enhancing the transparency of the decision-making process. However, these methods involve the datasets labeled with fine-grained attributes by expert knowledge, which incur high costs and introduce excessive human prior knowledge and bias. In this paper, we observe the long-tail distribution of concepts, based on which we propose a two-stage Concept Selection Model (CSM) to mine core concepts without introducing any human priors. The concept greedy rough selection algorithm is applied to extract head concepts, and then the concept mask fine selection method performs the extraction of core concepts. Experiments show that our approach achieves comparable performance to end-to-end black-box models, and human evaluation demonstrates that the concepts discovered by our method are interpretable and comprehensible for humans.
A Question-centric Multi-experts Contrastive Learning Framework for Improving the Accuracy and Interpretability of Deep Sequential Knowledge Tracing Models
Mar 12, 2024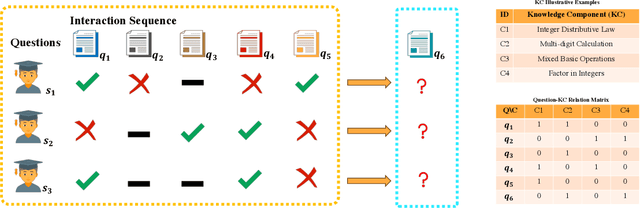
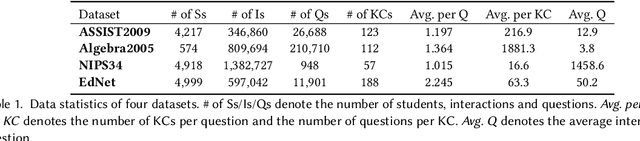
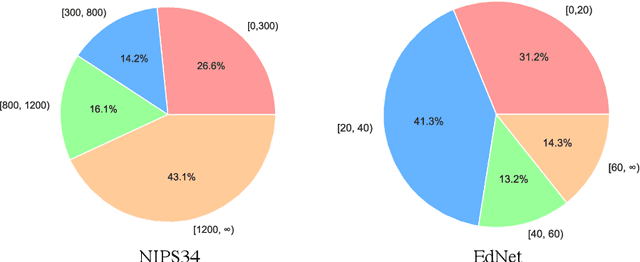
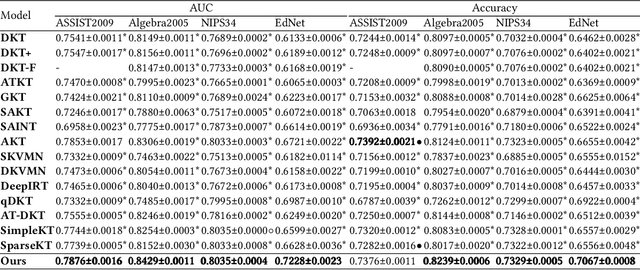
Knowledge tracing (KT) plays a crucial role in predicting students' future performance by analyzing their historical learning processes. Deep neural networks (DNNs) have shown great potential in solving the KT problem. However, there still exist some important challenges when applying deep learning techniques to model the KT process. The first challenge lies in taking the individual information of the question into modeling. This is crucial because, despite questions sharing the same knowledge component (KC), students' knowledge acquisition on homogeneous questions can vary significantly. The second challenge lies in interpreting the prediction results from existing deep learning-based KT models. In real-world applications, while it may not be necessary to have complete transparency and interpretability of the model parameters, it is crucial to present the model's prediction results in a manner that teachers find interpretable. This makes teachers accept the rationale behind the prediction results and utilize them to design teaching activities and tailored learning strategies for students. However, the inherent black-box nature of deep learning techniques often poses a hurdle for teachers to fully embrace the model's prediction results. To address these challenges, we propose a Question-centric Multi-experts Contrastive Learning framework for KT called Q-MCKT.
Improving Low-Resource Knowledge Tracing Tasks by Supervised Pre-training and Importance Mechanism Fine-tuning
Mar 11, 2024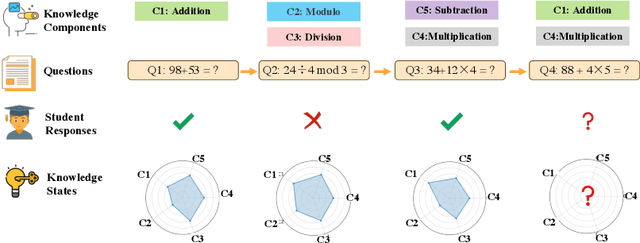
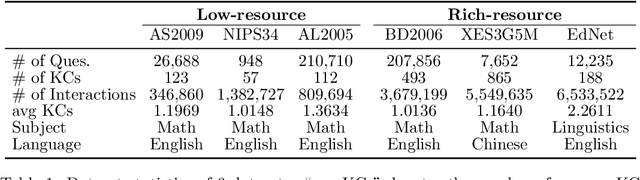
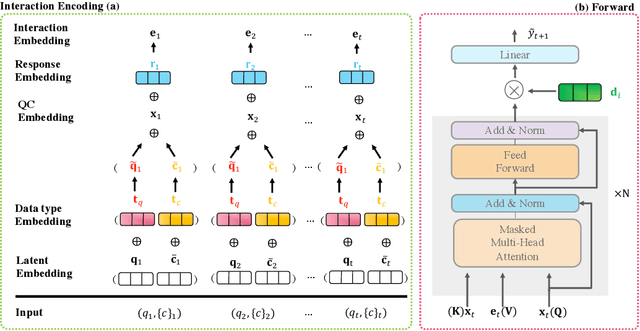
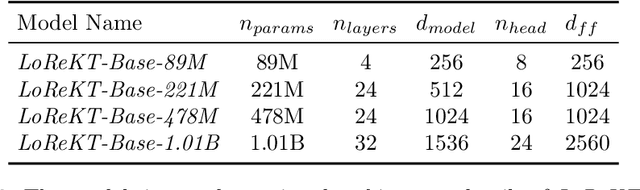
Knowledge tracing (KT) aims to estimate student's knowledge mastery based on their historical interactions. Recently, the deep learning based KT (DLKT) approaches have achieved impressive performance in the KT task. These DLKT models heavily rely on the large number of available student interactions. However, due to various reasons such as budget constraints and privacy concerns, observed interactions are very limited in many real-world scenarios, a.k.a, low-resource KT datasets. Directly training a DLKT model on a low-resource KT dataset may lead to overfitting and it is difficult to choose the appropriate deep neural architecture. Therefore, in this paper, we propose a low-resource KT framework called LoReKT to address above challenges. Inspired by the prevalent "pre-training and fine-tuning" paradigm, we aim to learn transferable parameters and representations from rich-resource KT datasets during the pre-training stage and subsequently facilitate effective adaptation to low-resource KT datasets. Specifically, we simplify existing sophisticated DLKT model architectures with purely a stack of transformer decoders. We design an encoding mechanism to incorporate student interactions from multiple KT data sources and develop an importance mechanism to prioritize updating parameters with high importance while constraining less important ones during the fine-tuning stage. We evaluate LoReKT on six public KT datasets and experimental results demonstrate the superiority of our approach in terms of AUC and Accuracy. To encourage reproducible research, we make our data and code publicly available at https://anonymous.4open.science/r/LoReKT-C619.
Multi-level Contrastive Learning for Script-based Character Understanding
Oct 20, 2023In this work, we tackle the scenario of understanding characters in scripts, which aims to learn the characters' personalities and identities from their utterances. We begin by analyzing several challenges in this scenario, and then propose a multi-level contrastive learning framework to capture characters' global information in a fine-grained manner. To validate the proposed framework, we conduct extensive experiments on three character understanding sub-tasks by comparing with strong pre-trained language models, including SpanBERT, Longformer, BigBird and ChatGPT-3.5. Experimental results demonstrate that our method improves the performances by a considerable margin. Through further in-depth analysis, we show the effectiveness of our method in addressing the challenges and provide more hints on the scenario of character understanding. We will open-source our work on github at https://github.com/David-Li0406/Script-based-Character-Understanding.
Bridging the Gap: Deciphering Tabular Data Using Large Language Model
Aug 28, 2023In the realm of natural language processing, the understanding of tabular data has perpetually stood as a focal point of scholarly inquiry. The emergence of expansive language models, exemplified by the likes of ChatGPT, has ushered in a wave of endeavors wherein researchers aim to harness these models for tasks related to table-based question answering. Central to our investigative pursuits is the elucidation of methodologies that amplify the aptitude of such large language models in discerning both the structural intricacies and inherent content of tables, ultimately facilitating their capacity to provide informed responses to pertinent queries. To this end, we have architected a distinctive module dedicated to the serialization of tables for seamless integration with expansive language models. Additionally, we've instituted a corrective mechanism within the model to rectify potential inaccuracies. Experimental results indicate that, although our proposed method trails the SOTA by approximately 11.7% in overall metrics, it surpasses the SOTA by about 1.2% in tests on specific datasets. This research marks the first application of large language models to table-based question answering tasks, enhancing the model's comprehension of both table structures and content.
Assisting Language Learners: Automated Trans-Lingual Definition Generation via Contrastive Prompt Learning
Jun 09, 2023

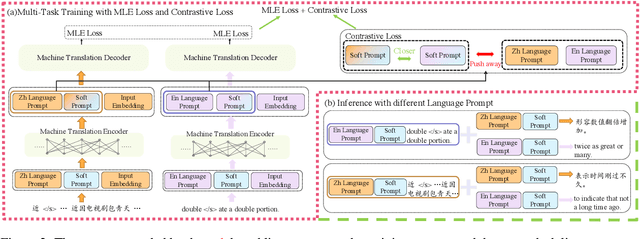
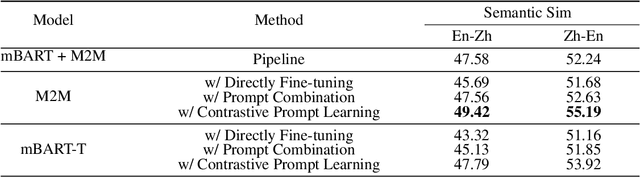
The standard definition generation task requires to automatically produce mono-lingual definitions (e.g., English definitions for English words), but ignores that the generated definitions may also consist of unfamiliar words for language learners. In this work, we propose a novel task of Trans-Lingual Definition Generation (TLDG), which aims to generate definitions in another language, i.e., the native speaker's language. Initially, we explore the unsupervised manner of this task and build up a simple implementation of fine-tuning the multi-lingual machine translation model. Then, we develop two novel methods, Prompt Combination and Contrastive Prompt Learning, for further enhancing the quality of the generation. Our methods are evaluated against the baseline Pipeline method in both rich- and low-resource settings, and we empirically establish its superiority in generating higher-quality trans-lingual definitions.
Robust Human Identity Anonymization using Pose Estimation
Jan 10, 2023
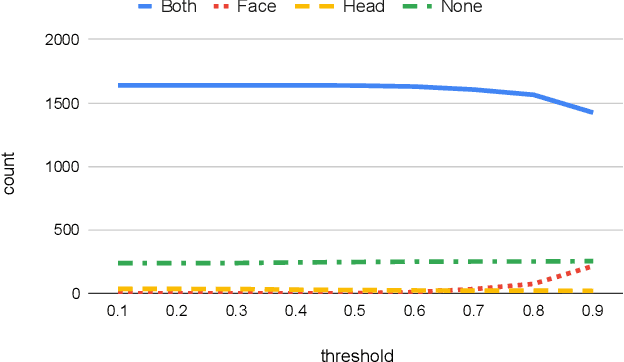

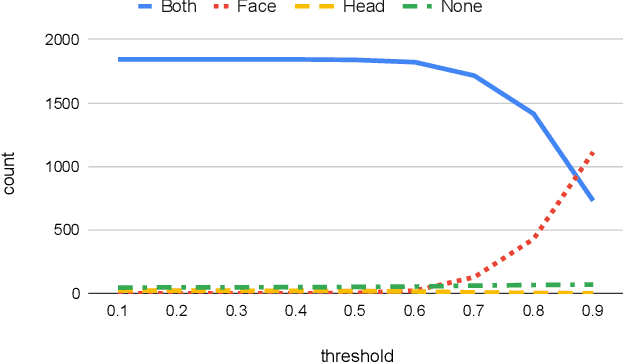
Many outdoor autonomous mobile platforms require more human identity anonymized data to power their data-driven algorithms. The human identity anonymization should be robust so that less manual intervention is needed, which remains a challenge for current face detection and anonymization systems. In this paper, we propose to use the skeleton generated from the state-of-the-art human pose estimation model to help localize human heads. We develop criteria to evaluate the performance and compare it with the face detection approach. We demonstrate that the proposed algorithm can reduce missed faces and thus better protect the identity information for the pedestrians. We also develop a confidence-based fusion method to further improve the performance.
* Source code will be available at https://github.com/AutonomousVehicleLaboratory/anonymization