 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYong Jiang
Exploring Key Point Analysis with Pairwise Generation and Graph Partitioning
Apr 17, 2024
Key Point Analysis (KPA), the summarization of multiple arguments into a concise collection of key points, continues to be a significant and unresolved issue within the field of argument mining. Existing models adapt a two-stage pipeline of clustering arguments or generating key points for argument clusters. This approach rely on semantic similarity instead of measuring the existence of shared key points among arguments. Additionally, it only models the intra-cluster relationship among arguments, disregarding the inter-cluster relationship between arguments that do not share key points. To address these limitations, we propose a novel approach for KPA with pairwise generation and graph partitioning. Our objective is to train a generative model that can simultaneously provide a score indicating the presence of shared key point between a pair of arguments and generate the shared key point. Subsequently, to map generated redundant key points to a concise set of key points, we proceed to construct an arguments graph by considering the arguments as vertices, the generated key points as edges, and the scores as edge weights. We then propose a graph partitioning algorithm to partition all arguments sharing the same key points to the same subgraph. Notably, our experimental findings demonstrate that our proposed model surpasses previous models when evaluated on both the ArgKP and QAM datasets.
Balancing Speciality and Versatility: a Coarse to Fine Framework for Supervised Fine-tuning Large Language Model
Apr 16, 2024Aligned Large Language Models (LLMs) showcase remarkable versatility, capable of handling diverse real-world tasks. Meanwhile, aligned LLMs are also expected to exhibit speciality, excelling in specific applications. However, fine-tuning with extra data, a common practice to gain speciality, often leads to catastrophic forgetting (CF) of previously acquired versatility, hindering the model's performance across diverse tasks. In response to this challenge, we propose CoFiTune, a coarse to fine framework in an attempt to strike the balance between speciality and versatility. At the coarse-grained level, an empirical tree-search algorithm is utilized to pinpoint and update specific modules that are crucial for speciality, while keeping other parameters frozen; at the fine-grained level, a soft-masking mechanism regulates the update to the LLMs, mitigating the CF issue without harming speciality. In an overall evaluation of both speciality and versatility, CoFiTune consistently outperforms baseline methods across diverse tasks and model scales. Compared to the full-parameter SFT, CoFiTune leads to about 14% versatility improvement and marginal speciality loss on a 13B model. Lastly, based on further analysis, we provide a speculative insight into the information forwarding process in LLMs, which helps explain the effectiveness of the proposed method. The code is available at https://github.com/rattlesnakey/CoFiTune.
Improving Retrieval Augmented Open-Domain Question-Answering with Vectorized Contexts
Apr 02, 2024In the era of large language models, applying techniques such as Retrieval Augmented Generation can better address Open-Domain Question-Answering problems. Due to constraints including model sizes and computing resources, the length of context is often limited, and it becomes challenging to empower the model to cover overlong contexts while answering questions from open domains. This paper proposes a general and convenient method to covering longer contexts in Open-Domain Question-Answering tasks. It leverages a small encoder language model that effectively encodes contexts, and the encoding applies cross-attention with origin inputs. With our method, the origin language models can cover several times longer contexts while keeping the computing requirements close to the baseline. Our experiments demonstrate that after fine-tuning, there is improved performance across two held-in datasets, four held-out datasets, and also in two In Context Learning settings.
Taming Pre-trained LLMs for Generalised Time Series Forecasting via Cross-modal Knowledge Distillation
Mar 12, 2024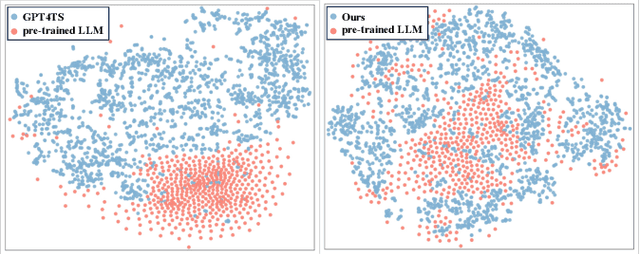
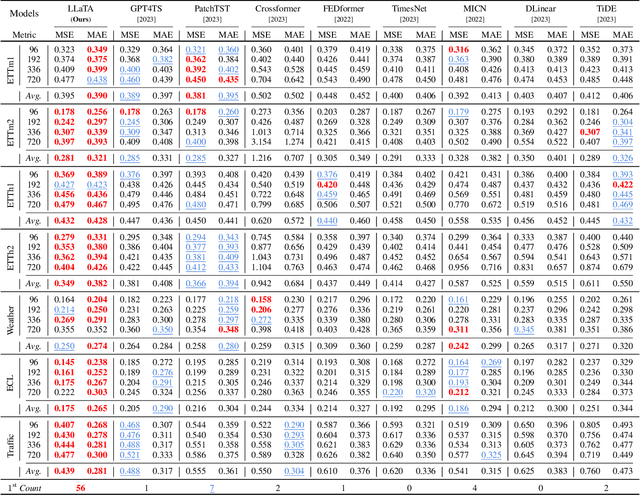
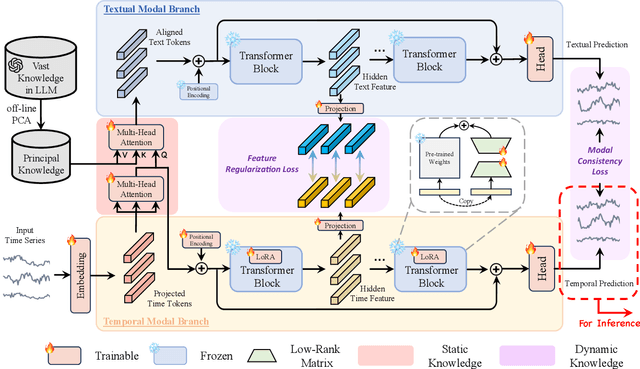
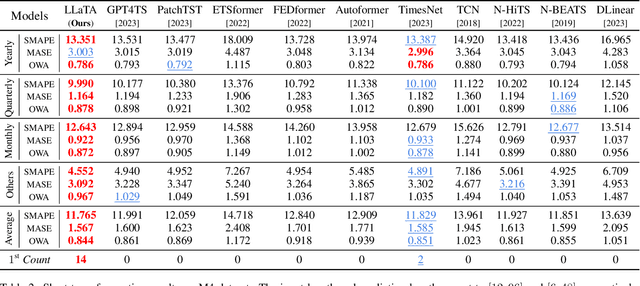
Multivariate time series forecasting has recently gained great success with the rapid growth of deep learning models. However, existing approaches usually train models from scratch using limited temporal data, preventing their generalization. Recently, with the surge of the Large Language Models (LLMs), several works have attempted to introduce LLMs into time series forecasting. Despite promising results, these methods directly take time series as the input to LLMs, ignoring the inherent modality gap between temporal and text data. In this work, we propose a novel Large Language Models and time series alignment framework, dubbed LLaTA, to fully unleash the potentials of LLMs in the time series forecasting challenge. Based on cross-modal knowledge distillation, the proposed method exploits both input-agnostic static knowledge and input-dependent dynamic knowledge in pre-trained LLMs. In this way, it empowers the forecasting model with favorable performance as well as strong generalization abilities. Extensive experiments demonstrate the proposed method establishes a new state of the art for both long- and short-term forecasting. Code is available at \url{https://github.com/Hank0626/LLaTA}.
A Question-centric Multi-experts Contrastive Learning Framework for Improving the Accuracy and Interpretability of Deep Sequential Knowledge Tracing Models
Mar 12, 2024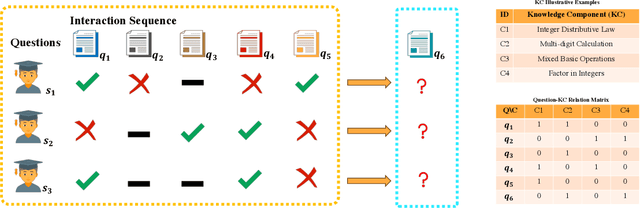
Knowledge tracing (KT) plays a crucial role in predicting students' future performance by analyzing their historical learning processes. Deep neural networks (DNNs) have shown great potential in solving the KT problem. However, there still exist some important challenges when applying deep learning techniques to model the KT process. The first challenge lies in taking the individual information of the question into modeling. This is crucial because, despite questions sharing the same knowledge component (KC), students' knowledge acquisition on homogeneous questions can vary significantly. The second challenge lies in interpreting the prediction results from existing deep learning-based KT models. In real-world applications, while it may not be necessary to have complete transparency and interpretability of the model parameters, it is crucial to present the model's prediction results in a manner that teachers find interpretable. This makes teachers accept the rationale behind the prediction results and utilize them to design teaching activities and tailored learning strategies for students. However, the inherent black-box nature of deep learning techniques often poses a hurdle for teachers to fully embrace the model's prediction results. To address these challenges, we propose a Question-centric Multi-experts Contrastive Learning framework for KT called Q-MCKT.
Improving Low-Resource Knowledge Tracing Tasks by Supervised Pre-training and Importance Mechanism Fine-tuning
Mar 11, 2024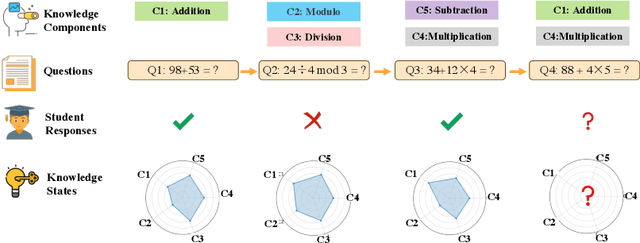
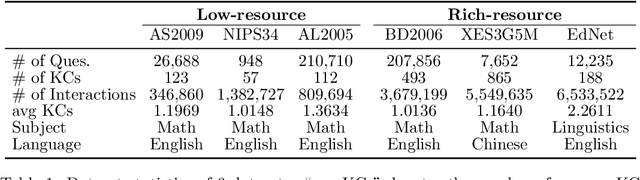
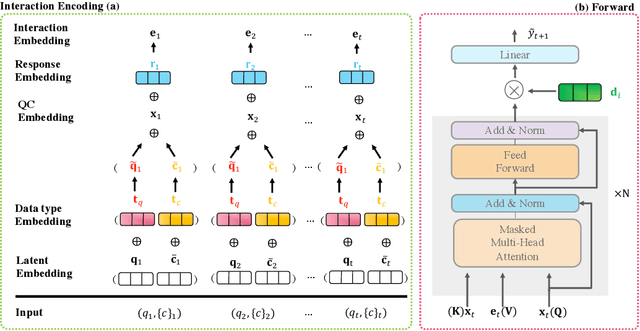
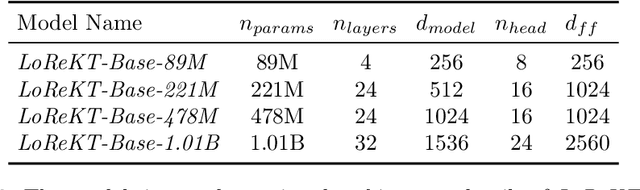
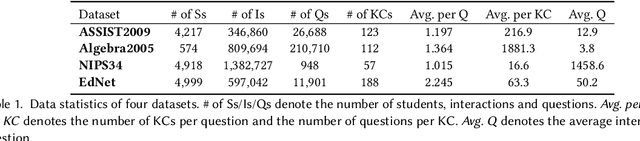
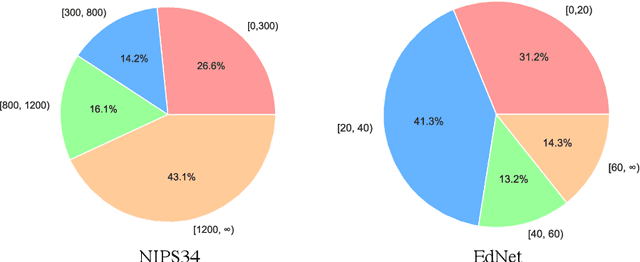
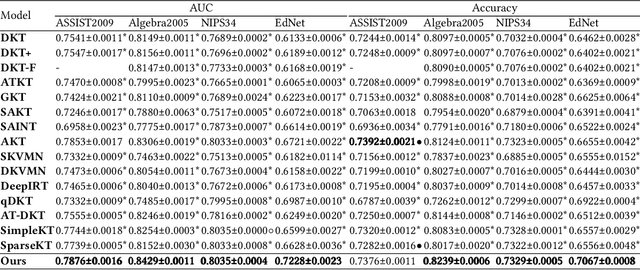
Knowledge tracing (KT) aims to estimate student's knowledge mastery based on their historical interactions. Recently, the deep learning based KT (DLKT) approaches have achieved impressive performance in the KT task. These DLKT models heavily rely on the large number of available student interactions. However, due to various reasons such as budget constraints and privacy concerns, observed interactions are very limited in many real-world scenarios, a.k.a, low-resource KT datasets. Directly training a DLKT model on a low-resource KT dataset may lead to overfitting and it is difficult to choose the appropriate deep neural architecture. Therefore, in this paper, we propose a low-resource KT framework called LoReKT to address above challenges. Inspired by the prevalent "pre-training and fine-tuning" paradigm, we aim to learn transferable parameters and representations from rich-resource KT datasets during the pre-training stage and subsequently facilitate effective adaptation to low-resource KT datasets. Specifically, we simplify existing sophisticated DLKT model architectures with purely a stack of transformer decoders. We design an encoding mechanism to incorporate student interactions from multiple KT data sources and develop an importance mechanism to prioritize updating parameters with high importance while constraining less important ones during the fine-tuning stage. We evaluate LoReKT on six public KT datasets and experimental results demonstrate the superiority of our approach in terms of AUC and Accuracy. To encourage reproducible research, we make our data and code publicly available at https://anonymous.4open.science/r/LoReKT-C619.
Let LLMs Take on the Latest Challenges! A Chinese Dynamic Question Answering Benchmark
Mar 02, 2024How to better evaluate the capabilities of Large Language Models (LLMs) is the focal point and hot topic in current LLMs research. Previous work has noted that due to the extremely high cost of iterative updates of LLMs, they are often unable to answer the latest dynamic questions well. To promote the improvement of Chinese LLMs' ability to answer dynamic questions, in this paper, we introduce CDQA, a Chinese Dynamic QA benchmark containing question-answer pairs related to the latest news on the Chinese Internet. We obtain high-quality data through a pipeline that combines humans and models, and carefully classify the samples according to the frequency of answer changes to facilitate a more fine-grained observation of LLMs' capabilities. We have also evaluated and analyzed mainstream and advanced Chinese LLMs on CDQA. Extensive experiments and valuable insights suggest that our proposed CDQA is challenging and worthy of more further study. We believe that the benchmark we provide will become one of the key data resources for improving LLMs' Chinese question-answering ability in the future.
Quantized Side Tuning: Fast and Memory-Efficient Tuning of Quantized Large Language Models
Jan 13, 2024Finetuning large language models (LLMs) has been empirically effective on a variety of downstream tasks. Existing approaches to finetuning an LLM either focus on parameter-efficient finetuning, which only updates a small number of trainable parameters, or attempt to reduce the memory footprint during the training phase of the finetuning. Typically, the memory footprint during finetuning stems from three contributors: model weights, optimizer states, and intermediate activations. However, existing works still require considerable memory and none can simultaneously mitigate memory footprint for all three sources. In this paper, we present Quantized Side Tuing (QST), which enables memory-efficient and fast finetuning of LLMs by operating through a dual-stage process. First, QST quantizes an LLM's model weights into 4-bit to reduce the memory footprint of the LLM's original weights; QST also introduces a side network separated from the LLM, which utilizes the hidden states of the LLM to make task-specific predictions. Using a separate side network avoids performing backpropagation through the LLM, thus reducing the memory requirement of the intermediate activations. Furthermore, QST leverages several low-rank adaptors and gradient-free downsample modules to significantly reduce the trainable parameters, so as to save the memory footprint of the optimizer states. Experiments show that QST can reduce the total memory footprint by up to 2.3 $\times$ and speed up the finetuning process by up to 3 $\times$ while achieving competent performance compared with the state-of-the-art. When it comes to full finetuning, QST can reduce the total memory footprint up to 7 $\times$.
A Comprehensive Study of Knowledge Editing for Large Language Models
Jan 09, 2024Large Language Models (LLMs) have shown extraordinary capabilities in understanding and generating text that closely mirrors human communication. However, a primary limitation lies in the significant computational demands during training, arising from their extensive parameterization. This challenge is further intensified by the dynamic nature of the world, necessitating frequent updates to LLMs to correct outdated information or integrate new knowledge, thereby ensuring their continued relevance. Note that many applications demand continual model adjustments post-training to address deficiencies or undesirable behaviors. There is an increasing interest in efficient, lightweight methods for on-the-fly model modifications. To this end, recent years have seen a burgeoning in the techniques of knowledge editing for LLMs, which aim to efficiently modify LLMs' behaviors within specific domains while preserving overall performance across various inputs. In this paper, we first define the knowledge editing problem and then provide a comprehensive review of cutting-edge approaches. Drawing inspiration from educational and cognitive research theories, we propose a unified categorization criterion that classifies knowledge editing methods into three groups: resorting to external knowledge, merging knowledge into the model, and editing intrinsic knowledge. Furthermore, we introduce a new benchmark, KnowEdit, for a comprehensive empirical evaluation of representative knowledge editing approaches. Additionally, we provide an in-depth analysis of knowledge location, which can give a deeper understanding of the knowledge structures inherent within LLMs. Finally, we discuss several potential applications of knowledge editing, outlining its broad and impactful implications.
EcomGPT-CT: Continual Pre-training of E-commerce Large Language Models with Semi-structured Data
Dec 25, 2023Large Language Models (LLMs) pre-trained on massive corpora have exhibited remarkable performance on various NLP tasks. However, applying these models to specific domains still poses significant challenges, such as lack of domain knowledge, limited capacity to leverage domain knowledge and inadequate adaptation to domain-specific data formats. Considering the exorbitant cost of training LLMs from scratch and the scarcity of annotated data within particular domains, in this work, we focus on domain-specific continual pre-training of LLMs using E-commerce domain as an exemplar. Specifically, we explore the impact of continual pre-training on LLMs employing unlabeled general and E-commercial corpora. Furthermore, we design a mixing strategy among different data sources to better leverage E-commercial semi-structured data. We construct multiple tasks to assess LLMs' few-shot In-context Learning ability and their zero-shot performance after instruction tuning in E-commerce domain. Experimental results demonstrate the effectiveness of continual pre-training of E-commerce LLMs and the efficacy of our devised data mixing strategy.