 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeng Wang
Enhancing 3D Fidelity of Text-to-3D using Cross-View Correspondences
Apr 16, 2024
Leveraging multi-view diffusion models as priors for 3D optimization have alleviated the problem of 3D consistency, e.g., the Janus face problem or the content drift problem, in zero-shot text-to-3D models. However, the 3D geometric fidelity of the output remains an unresolved issue; albeit the rendered 2D views are realistic, the underlying geometry may contain errors such as unreasonable concavities. In this work, we propose CorrespondentDream, an effective method to leverage annotation-free, cross-view correspondences yielded from the diffusion U-Net to provide additional 3D prior to the NeRF optimization process. We find that these correspondences are strongly consistent with human perception, and by adopting it in our loss design, we are able to produce NeRF models with geometries that are more coherent with common sense, e.g., more smoothed object surface, yielding higher 3D fidelity. We demonstrate the efficacy of our approach through various comparative qualitative results and a solid user study.
HQ-Edit: A High-Quality Dataset for Instruction-based Image Editing
Apr 15, 2024This study introduces HQ-Edit, a high-quality instruction-based image editing dataset with around 200,000 edits. Unlike prior approaches relying on attribute guidance or human feedback on building datasets, we devise a scalable data collection pipeline leveraging advanced foundation models, namely GPT-4V and DALL-E 3. To ensure its high quality, diverse examples are first collected online, expanded, and then used to create high-quality diptychs featuring input and output images with detailed text prompts, followed by precise alignment ensured through post-processing. In addition, we propose two evaluation metrics, Alignment and Coherence, to quantitatively assess the quality of image edit pairs using GPT-4V. HQ-Edits high-resolution images, rich in detail and accompanied by comprehensive editing prompts, substantially enhance the capabilities of existing image editing models. For example, an HQ-Edit finetuned InstructPix2Pix can attain state-of-the-art image editing performance, even surpassing those models fine-tuned with human-annotated data. The project page is https://thefllood.github.io/HQEdit_web.
COCONut: Modernizing COCO Segmentation
Apr 12, 2024In recent decades, the vision community has witnessed remarkable progress in visual recognition, partially owing to advancements in dataset benchmarks. Notably, the established COCO benchmark has propelled the development of modern detection and segmentation systems. However, the COCO segmentation benchmark has seen comparatively slow improvement over the last decade. Originally equipped with coarse polygon annotations for thing instances, it gradually incorporated coarse superpixel annotations for stuff regions, which were subsequently heuristically amalgamated to yield panoptic segmentation annotations. These annotations, executed by different groups of raters, have resulted not only in coarse segmentation masks but also in inconsistencies between segmentation types. In this study, we undertake a comprehensive reevaluation of the COCO segmentation annotations. By enhancing the annotation quality and expanding the dataset to encompass 383K images with more than 5.18M panoptic masks, we introduce COCONut, the COCO Next Universal segmenTation dataset. COCONut harmonizes segmentation annotations across semantic, instance, and panoptic segmentation with meticulously crafted high-quality masks, and establishes a robust benchmark for all segmentation tasks. To our knowledge, COCONut stands as the inaugural large-scale universal segmentation dataset, verified by human raters. We anticipate that the release of COCONut will significantly contribute to the community's ability to assess the progress of novel neural networks.
Self-Explainable Affordance Learning with Embodied Caption
Apr 08, 2024In the field of visual affordance learning, previous methods mainly used abundant images or videos that delineate human behavior patterns to identify action possibility regions for object manipulation, with a variety of applications in robotic tasks. However, they encounter a main challenge of action ambiguity, illustrated by the vagueness like whether to beat or carry a drum, and the complexities involved in processing intricate scenes. Moreover, it is important for human intervention to rectify robot errors in time. To address these issues, we introduce Self-Explainable Affordance learning (SEA) with embodied caption. This innovation enables robots to articulate their intentions and bridge the gap between explainable vision-language caption and visual affordance learning. Due to a lack of appropriate dataset, we unveil a pioneering dataset and metrics tailored for this task, which integrates images, heatmaps, and embodied captions. Furthermore, we propose a novel model to effectively combine affordance grounding with self-explanation in a simple but efficient manner. Extensive quantitative and qualitative experiments demonstrate our method's effectiveness.
Low-Rank Rescaled Vision Transformer Fine-Tuning: A Residual Design Approach
Mar 28, 2024Parameter-efficient fine-tuning for pre-trained Vision Transformers aims to adeptly tailor a model to downstream tasks by learning a minimal set of new adaptation parameters while preserving the frozen majority of pre-trained parameters. Striking a balance between retaining the generalizable representation capacity of the pre-trained model and acquiring task-specific features poses a key challenge. Currently, there is a lack of focus on guiding this delicate trade-off. In this study, we approach the problem from the perspective of Singular Value Decomposition (SVD) of pre-trained parameter matrices, providing insights into the tuning dynamics of existing methods. Building upon this understanding, we propose a Residual-based Low-Rank Rescaling (RLRR) fine-tuning strategy. This strategy not only enhances flexibility in parameter tuning but also ensures that new parameters do not deviate excessively from the pre-trained model through a residual design. Extensive experiments demonstrate that our method achieves competitive performance across various downstream image classification tasks, all while maintaining comparable new parameters. We believe this work takes a step forward in offering a unified perspective for interpreting existing methods and serves as motivation for the development of new approaches that move closer to effectively considering the crucial trade-off mentioned above. Our code is available at \href{https://github.com/zstarN70/RLRR.git}{https://github.com/zstarN70/RLRR.git}.
BAD-Gaussians: Bundle Adjusted Deblur Gaussian Splatting
Mar 19, 2024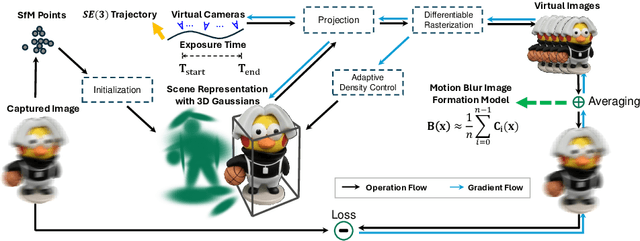
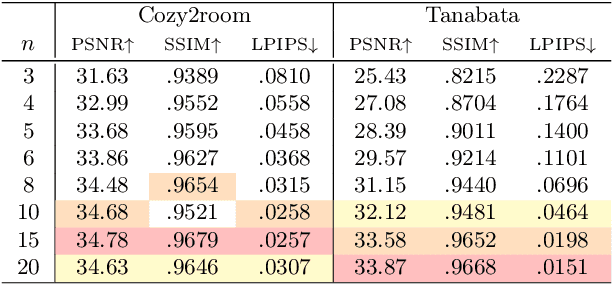


While neural rendering has demonstrated impressive capabilities in 3D scene reconstruction and novel view synthesis, it heavily relies on high-quality sharp images and accurate camera poses. Numerous approaches have been proposed to train Neural Radiance Fields (NeRF) with motion-blurred images, commonly encountered in real-world scenarios such as low-light or long-exposure conditions. However, the implicit representation of NeRF struggles to accurately recover intricate details from severely motion-blurred images and cannot achieve real-time rendering. In contrast, recent advancements in 3D Gaussian Splatting achieve high-quality 3D scene reconstruction and real-time rendering by explicitly optimizing point clouds as Gaussian spheres. In this paper, we introduce a novel approach, named BAD-Gaussians (Bundle Adjusted Deblur Gaussian Splatting), which leverages explicit Gaussian representation and handles severe motion-blurred images with inaccurate camera poses to achieve high-quality scene reconstruction. Our method models the physical image formation process of motion-blurred images and jointly learns the parameters of Gaussians while recovering camera motion trajectories during exposure time. In our experiments, we demonstrate that BAD-Gaussians not only achieves superior rendering quality compared to previous state-of-the-art deblur neural rendering methods on both synthetic and real datasets but also enables real-time rendering capabilities. Our project page and source code is available at https://lingzhezhao.github.io/BAD-Gaussians/
SAM-Lightening: A Lightweight Segment Anything Model with Dilated Flash Attention to Achieve 30 times Acceleration
Mar 18, 2024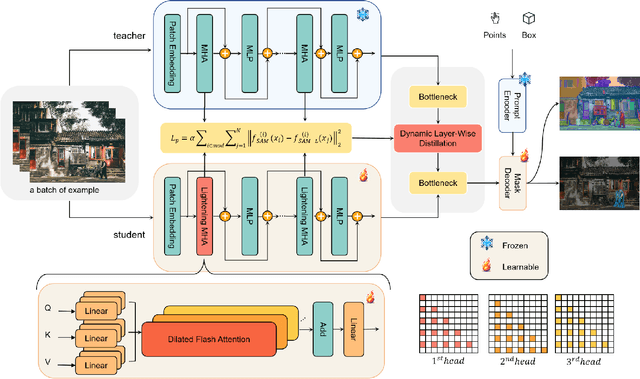
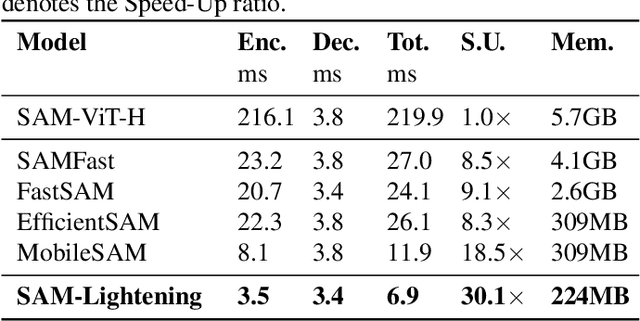

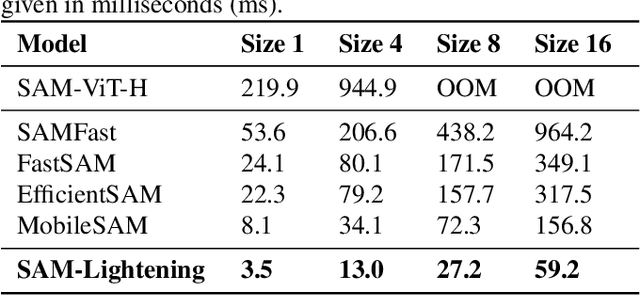
Segment Anything Model (SAM) has garnered significant attention in segmentation tasks due to their zero-shot generalization ability. However, a broader application of SAMs to real-world practice has been restricted by their low inference speed and high computational memory demands, which mainly stem from the attention mechanism. Existing work concentrated on optimizing the encoder, yet has not adequately addressed the inefficiency of the attention mechanism itself, even when distilled to a smaller model, which thus leaves space for further improvement. In response, we introduce SAM-Lightening, a variant of SAM, that features a re-engineered attention mechanism, termed Dilated Flash Attention. It not only facilitates higher parallelism, enhancing processing efficiency but also retains compatibility with the existing FlashAttention. Correspondingly, we propose a progressive distillation to enable an efficient knowledge transfer from the vanilla SAM without costly training from scratch. Experiments on COCO and LVIS reveal that SAM-Lightening significantly outperforms the state-of-the-art methods in both run-time efficiency and segmentation accuracy. Specifically, it can achieve an inference speed of 7 milliseconds (ms) per image, for images of size 1024*1024 pixels, which is 30.1 times faster than the vanilla SAM and 2.1 times than the state-of-the-art. Moreover, it takes only 244MB memory, which is 3.5\% of the vanilla SAM. The code and weights are available at https://anonymous.4open.science/r/SAM-LIGHTENING-BC25/.
Region-aware Distribution Contrast: A Novel Approach to Multi-Task Partially Supervised Learning
Mar 15, 2024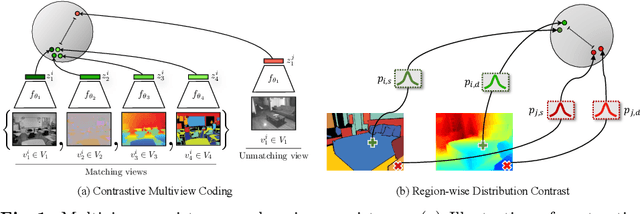
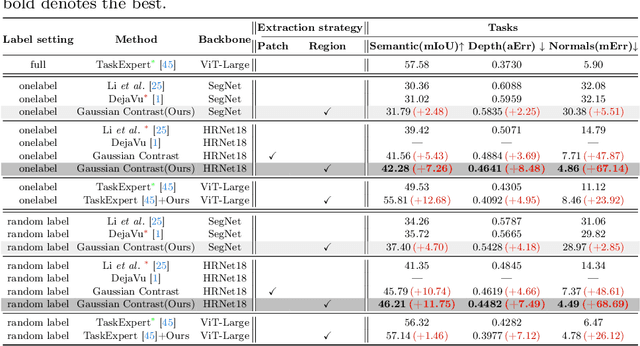
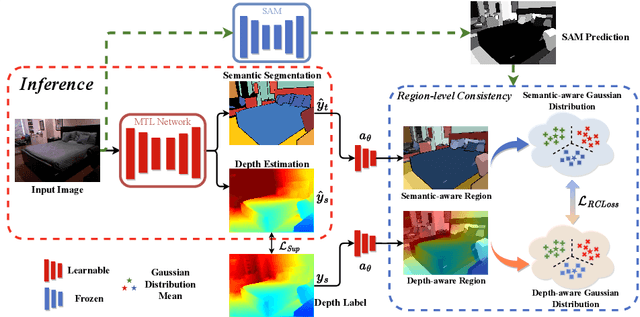

In this study, we address the intricate challenge of multi-task dense prediction, encompassing tasks such as semantic segmentation, depth estimation, and surface normal estimation, particularly when dealing with partially annotated data (MTPSL). The complexity arises from the absence of complete task labels for each training image. Given the inter-related nature of these pixel-wise dense tasks, our focus is on mining and capturing cross-task relationships. Existing solutions typically rely on learning global image representations for global cross-task image matching, imposing constraints that, unfortunately, sacrifice the finer structures within the images. Attempting local matching as a remedy faces hurdles due to the lack of precise region supervision, making local alignment a challenging endeavor. The introduction of Segment Anything Model (SAM) sheds light on addressing local alignment challenges by providing free and high-quality solutions for region detection. Leveraging SAM-detected regions, the subsequent challenge lies in aligning the representations within these regions. Diverging from conventional methods that directly learn a monolithic image representation, our proposal involves modeling region-wise representations using Gaussian Distributions. Aligning these distributions between corresponding regions from different tasks imparts higher flexibility and capacity to capture intra-region structures, accommodating a broader range of tasks. This innovative approach significantly enhances our ability to effectively capture cross-task relationships, resulting in improved overall performance in partially supervised multi-task dense prediction scenarios. Extensive experiments conducted on two widely used benchmarks underscore the superior effectiveness of our proposed method, showcasing state-of-the-art performance even when compared to fully supervised methods.
CoLeCLIP: Open-Domain Continual Learning via Joint Task Prompt and Vocabulary Learning
Mar 15, 2024
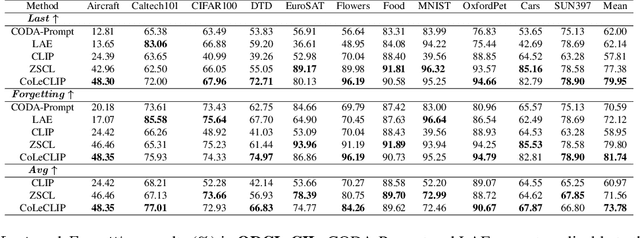
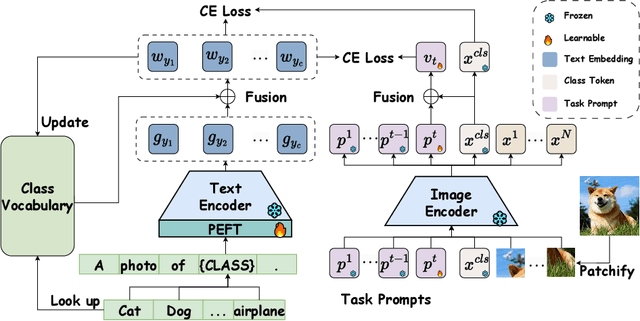
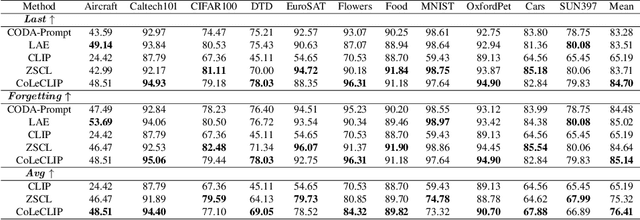
This paper explores the problem of continual learning (CL) of vision-language models (VLMs) in open domains, where the models need to perform continual updating and inference on a streaming of datasets from diverse seen and unseen domains with novel classes. Such a capability is crucial for various applications in open environments, e.g., AI assistants, autonomous driving systems, and robotics. Current CL studies mostly focus on closed-set scenarios in a single domain with known classes. Large pre-trained VLMs like CLIP have demonstrated superior zero-shot recognition ability, and a number of recent studies leverage this ability to mitigate catastrophic forgetting in CL, but they focus on closed-set CL in a single domain dataset. Open-domain CL of large VLMs is significantly more challenging due to 1) large class correlations and domain gaps across the datasets and 2) the forgetting of zero-shot knowledge in the pre-trained VLMs in addition to the knowledge learned from the newly adapted datasets. In this work we introduce a novel approach, termed CoLeCLIP, that learns an open-domain CL model based on CLIP. It addresses these challenges by a joint learning of a set of task prompts and a cross-domain class vocabulary. Extensive experiments on 11 domain datasets show that CoLeCLIP outperforms state-of-the-art methods for open-domain CL under both task- and class-incremental learning settings.
Dcl-Net: Dual Contrastive Learning Network for Semi-Supervised Multi-Organ Segmentation
Mar 06, 2024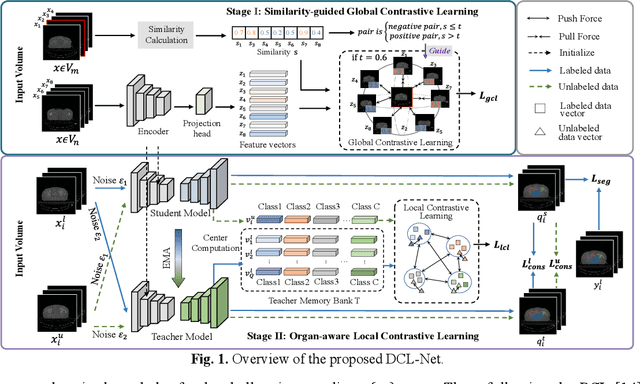
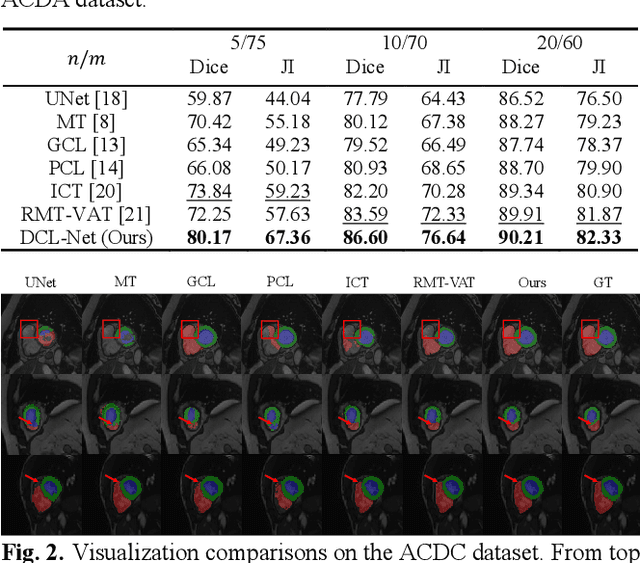
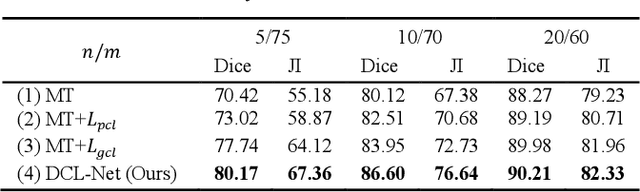
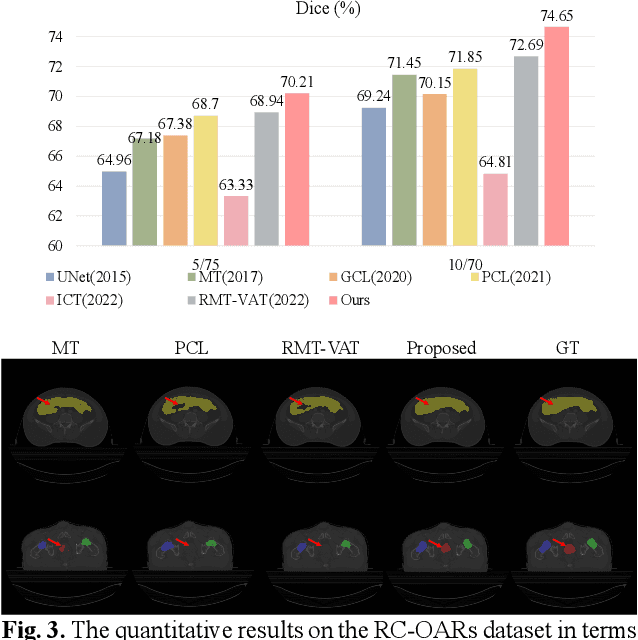
Semi-supervised learning is a sound measure to relieve the strict demand of abundant annotated datasets, especially for challenging multi-organ segmentation . However, most existing SSL methods predict pixels in a single image independently, ignoring the relations among images and categories. In this paper, we propose a two-stage Dual Contrastive Learning Network for semi-supervised MoS, which utilizes global and local contrastive learning to strengthen the relations among images and classes. Concretely, in Stage 1, we develop a similarity-guided global contrastive learning to explore the implicit continuity and similarity among images and learn global context. Then, in Stage 2, we present an organ-aware local contrastive learning to further attract the class representations. To ease the computation burden, we introduce a mask center computation algorithm to compress the category representations for local contrastive learning. Experiments conducted on the public 2017 ACDC dataset and an in-house RC-OARs dataset has demonstrated the superior performance of our method.