 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChenchen Jing
CoLeCLIP: Open-Domain Continual Learning via Joint Task Prompt and Vocabulary Learning
Mar 15, 2024
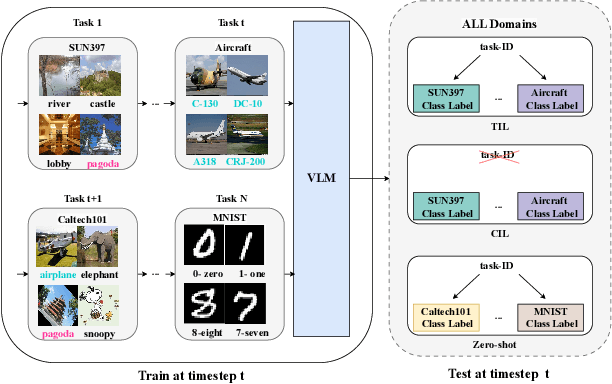
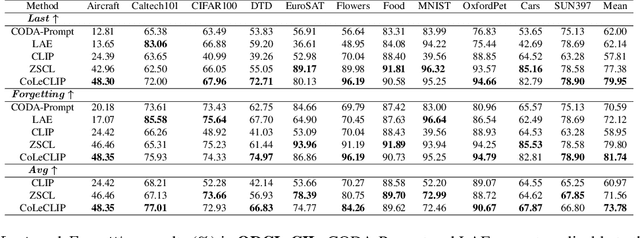
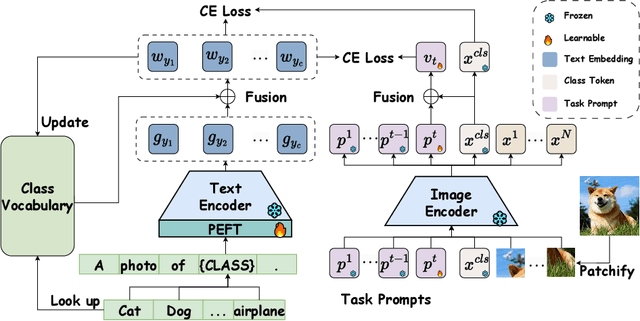
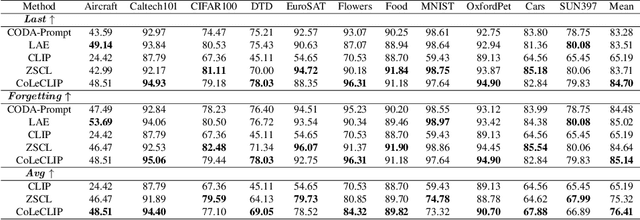
This paper explores the problem of continual learning (CL) of vision-language models (VLMs) in open domains, where the models need to perform continual updating and inference on a streaming of datasets from diverse seen and unseen domains with novel classes. Such a capability is crucial for various applications in open environments, e.g., AI assistants, autonomous driving systems, and robotics. Current CL studies mostly focus on closed-set scenarios in a single domain with known classes. Large pre-trained VLMs like CLIP have demonstrated superior zero-shot recognition ability, and a number of recent studies leverage this ability to mitigate catastrophic forgetting in CL, but they focus on closed-set CL in a single domain dataset. Open-domain CL of large VLMs is significantly more challenging due to 1) large class correlations and domain gaps across the datasets and 2) the forgetting of zero-shot knowledge in the pre-trained VLMs in addition to the knowledge learned from the newly adapted datasets. In this work we introduce a novel approach, termed CoLeCLIP, that learns an open-domain CL model based on CLIP. It addresses these challenges by a joint learning of a set of task prompts and a cross-domain class vocabulary. Extensive experiments on 11 domain datasets show that CoLeCLIP outperforms state-of-the-art methods for open-domain CL under both task- and class-incremental learning settings.
SegPrompt: Boosting Open-world Segmentation via Category-level Prompt Learning
Aug 12, 2023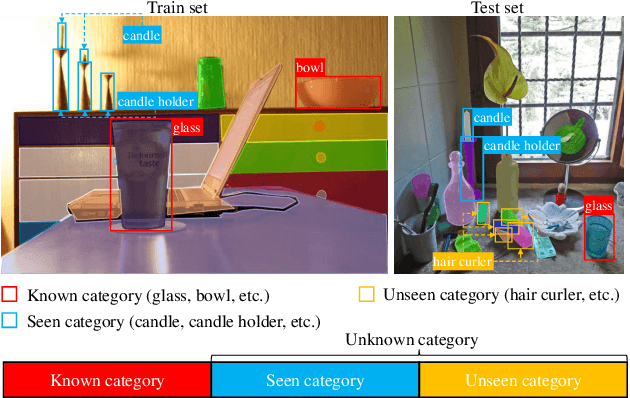
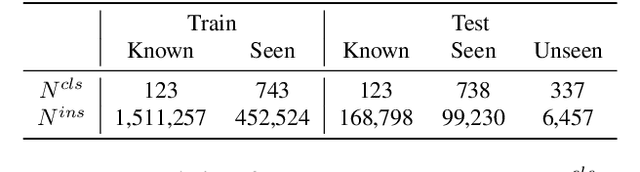
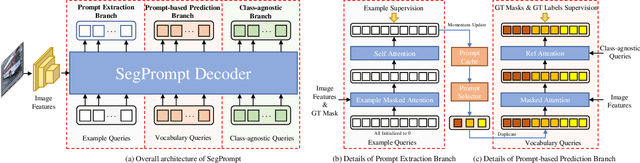
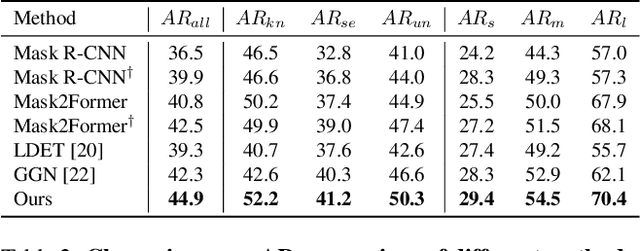
Current closed-set instance segmentation models rely on pre-defined class labels for each mask during training and evaluation, largely limiting their ability to detect novel objects. Open-world instance segmentation (OWIS) models address this challenge by detecting unknown objects in a class-agnostic manner. However, previous OWIS approaches completely erase category information during training to keep the model's ability to generalize to unknown objects. In this work, we propose a novel training mechanism termed SegPrompt that uses category information to improve the model's class-agnostic segmentation ability for both known and unknown categories. In addition, the previous OWIS training setting exposes the unknown classes to the training set and brings information leakage, which is unreasonable in the real world. Therefore, we provide a new open-world benchmark closer to a real-world scenario by dividing the dataset classes into known-seen-unseen parts. For the first time, we focus on the model's ability to discover objects that never appear in the training set images. Experiments show that SegPrompt can improve the overall and unseen detection performance by 5.6% and 6.1% in AR on our new benchmark without affecting the inference efficiency. We further demonstrate the effectiveness of our method on existing cross-dataset transfer and strongly supervised settings, leading to 5.5% and 12.3% relative improvement.
Learning Conditional Attributes for Compositional Zero-Shot Learning
Jun 14, 2023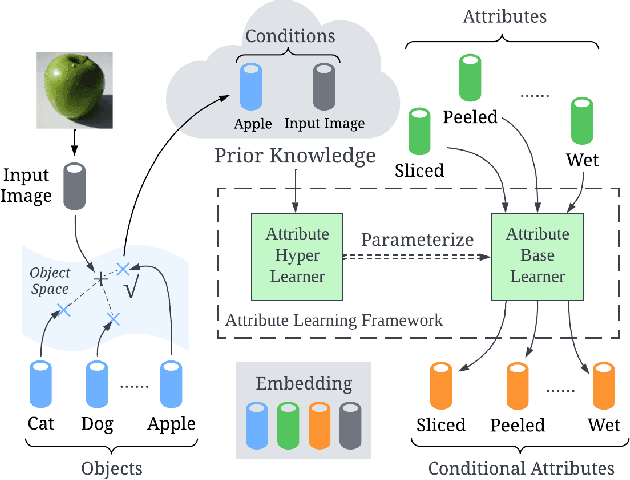

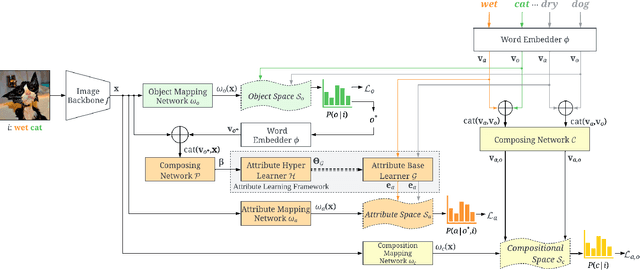
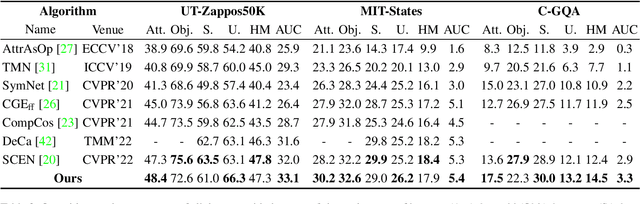
Compositional Zero-Shot Learning (CZSL) aims to train models to recognize novel compositional concepts based on learned concepts such as attribute-object combinations. One of the challenges is to model attributes interacted with different objects, e.g., the attribute ``wet" in ``wet apple" and ``wet cat" is different. As a solution, we provide analysis and argue that attributes are conditioned on the recognized object and input image and explore learning conditional attribute embeddings by a proposed attribute learning framework containing an attribute hyper learner and an attribute base learner. By encoding conditional attributes, our model enables to generate flexible attribute embeddings for generalization from seen to unseen compositions. Experiments on CZSL benchmarks, including the more challenging C-GQA dataset, demonstrate better performances compared with other state-of-the-art approaches and validate the importance of learning conditional attributes. Code is available at https://github.com/wqshmzh/CANet-CZSL