 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChengxiang Fan
Diffusion Models Trained with Large Data Are Transferable Visual Models
Mar 15, 2024
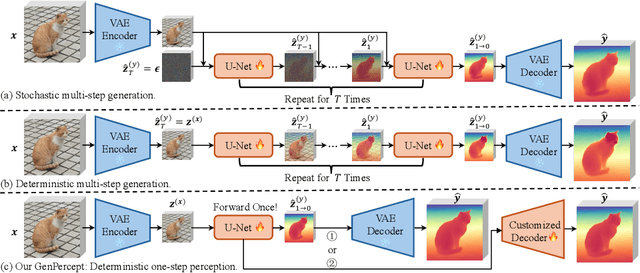
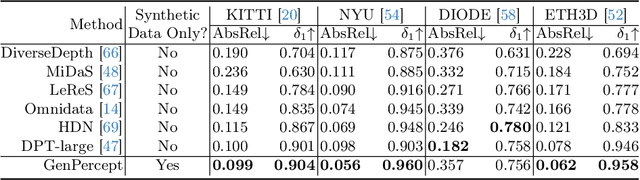

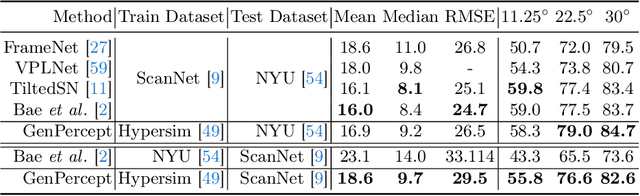
We show that, simply initializing image understanding models using a pre-trained UNet (or transformer) of diffusion models, it is possible to achieve remarkable transferable performance on fundamental vision perception tasks using a moderate amount of target data (even synthetic data only), including monocular depth, surface normal, image segmentation, matting, human pose estimation, among virtually many others. Previous works have adapted diffusion models for various perception tasks, often reformulating these tasks as generation processes to align with the diffusion process. In sharp contrast, we demonstrate that fine-tuning these models with minimal adjustments can be a more effective alternative, offering the advantages of being embarrassingly simple and significantly faster. As the backbone network of Stable Diffusion models is trained on giant datasets comprising billions of images, we observe very robust generalization capabilities of the diffusion backbone. Experimental results showcase the remarkable transferability of the backbone of diffusion models across diverse tasks and real-world datasets.
SegPrompt: Boosting Open-world Segmentation via Category-level Prompt Learning
Aug 12, 2023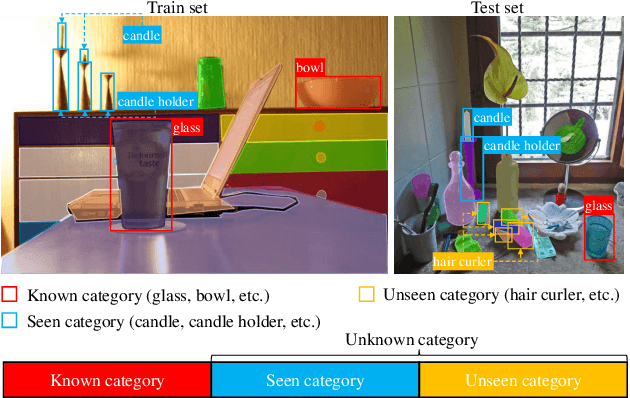
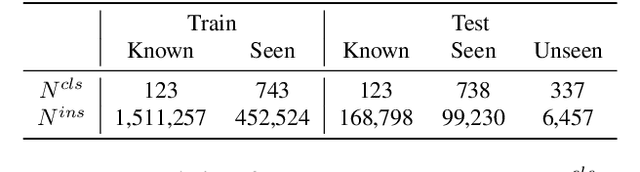
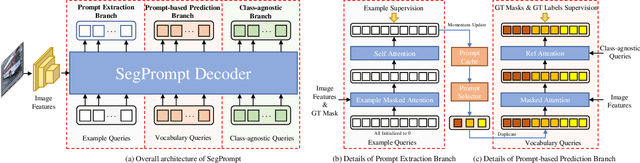
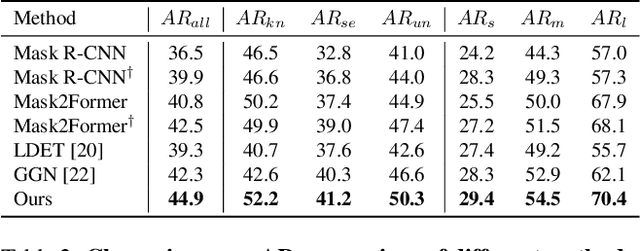
Current closed-set instance segmentation models rely on pre-defined class labels for each mask during training and evaluation, largely limiting their ability to detect novel objects. Open-world instance segmentation (OWIS) models address this challenge by detecting unknown objects in a class-agnostic manner. However, previous OWIS approaches completely erase category information during training to keep the model's ability to generalize to unknown objects. In this work, we propose a novel training mechanism termed SegPrompt that uses category information to improve the model's class-agnostic segmentation ability for both known and unknown categories. In addition, the previous OWIS training setting exposes the unknown classes to the training set and brings information leakage, which is unreasonable in the real world. Therefore, we provide a new open-world benchmark closer to a real-world scenario by dividing the dataset classes into known-seen-unseen parts. For the first time, we focus on the model's ability to discover objects that never appear in the training set images. Experiments show that SegPrompt can improve the overall and unseen detection performance by 5.6% and 6.1% in AR on our new benchmark without affecting the inference efficiency. We further demonstrate the effectiveness of our method on existing cross-dataset transfer and strongly supervised settings, leading to 5.5% and 12.3% relative improvement.
CTVIS: Consistent Training for Online Video Instance Segmentation
Jul 24, 2023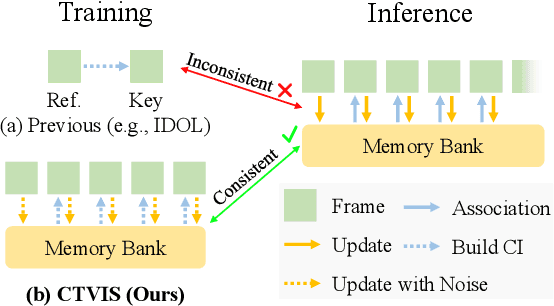
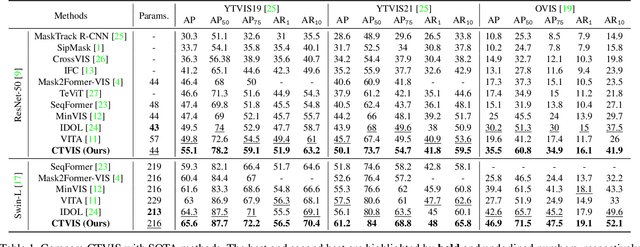
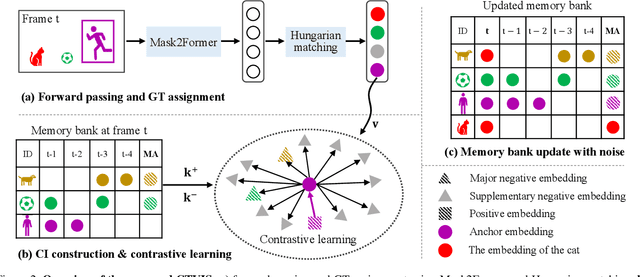
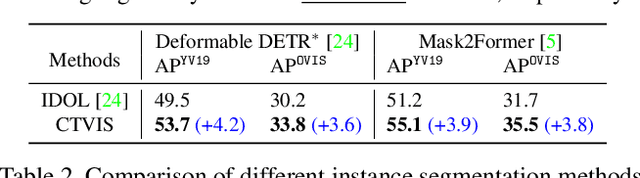
The discrimination of instance embeddings plays a vital role in associating instances across time for online video instance segmentation (VIS). Instance embedding learning is directly supervised by the contrastive loss computed upon the contrastive items (CIs), which are sets of anchor/positive/negative embeddings. Recent online VIS methods leverage CIs sourced from one reference frame only, which we argue is insufficient for learning highly discriminative embeddings. Intuitively, a possible strategy to enhance CIs is replicating the inference phase during training. To this end, we propose a simple yet effective training strategy, called Consistent Training for Online VIS (CTVIS), which devotes to aligning the training and inference pipelines in terms of building CIs. Specifically, CTVIS constructs CIs by referring inference the momentum-averaged embedding and the memory bank storage mechanisms, and adding noise to the relevant embeddings. Such an extension allows a reliable comparison between embeddings of current instances and the stable representations of historical instances, thereby conferring an advantage in modeling VIS challenges such as occlusion, re-identification, and deformation. Empirically, CTVIS outstrips the SOTA VIS models by up to +5.0 points on three VIS benchmarks, including YTVIS19 (55.1% AP), YTVIS21 (50.1% AP) and OVIS (35.5% AP). Furthermore, we find that pseudo-videos transformed from images can train robust models surpassing fully-supervised ones.