 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWei Dong
Bracketing Image Restoration and Enhancement with High-Low Frequency Decomposition
Apr 24, 2024
In real-world scenarios, due to a series of image degradations, obtaining high-quality, clear content photos is challenging. While significant progress has been made in synthesizing high-quality images, previous methods for image restoration and enhancement often overlooked the characteristics of different degradations. They applied the same structure to address various types of degradation, resulting in less-than-ideal restoration outcomes. Inspired by the notion that high/low frequency information is applicable to different degradations, we introduce HLNet, a Bracketing Image Restoration and Enhancement method based on high-low frequency decomposition. Specifically, we employ two modules for feature extraction: shared weight modules and non-shared weight modules. In the shared weight modules, we use SCConv to extract common features from different degradations. In the non-shared weight modules, we introduce the High-Low Frequency Decomposition Block (HLFDB), which employs different methods to handle high-low frequency information, enabling the model to address different degradations more effectively. Compared to other networks, our method takes into account the characteristics of different degradations, thus achieving higher-quality image restoration.
NTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results
Apr 22, 2024This paper reviews the NTIRE 2024 low light image enhancement challenge, highlighting the proposed solutions and results. The aim of this challenge is to discover an effective network design or solution capable of generating brighter, clearer, and visually appealing results when dealing with a variety of conditions, including ultra-high resolution (4K and beyond), non-uniform illumination, backlighting, extreme darkness, and night scenes. A notable total of 428 participants registered for the challenge, with 22 teams ultimately making valid submissions. This paper meticulously evaluates the state-of-the-art advancements in enhancing low-light images, reflecting the significant progress and creativity in this field.
CRNet: A Detail-Preserving Network for Unified Image Restoration and Enhancement Task
Apr 22, 2024In real-world scenarios, images captured often suffer from blurring, noise, and other forms of image degradation, and due to sensor limitations, people usually can only obtain low dynamic range images. To achieve high-quality images, researchers have attempted various image restoration and enhancement operations on photographs, including denoising, deblurring, and high dynamic range imaging. However, merely performing a single type of image enhancement still cannot yield satisfactory images. In this paper, to deal with the challenge above, we propose the Composite Refinement Network (CRNet) to address this issue using multiple exposure images. By fully integrating information-rich multiple exposure inputs, CRNet can perform unified image restoration and enhancement. To improve the quality of image details, CRNet explicitly separates and strengthens high and low-frequency information through pooling layers, using specially designed Multi-Branch Blocks for effective fusion of these frequencies. To increase the receptive field and fully integrate input features, CRNet employs the High-Frequency Enhancement Module, which includes large kernel convolutions and an inverted bottleneck ConvFFN. Our model secured third place in the first track of the Bracketing Image Restoration and Enhancement Challenge, surpassing previous SOTA models in both testing metrics and visual quality.
Low-Rank Rescaled Vision Transformer Fine-Tuning: A Residual Design Approach
Mar 28, 2024
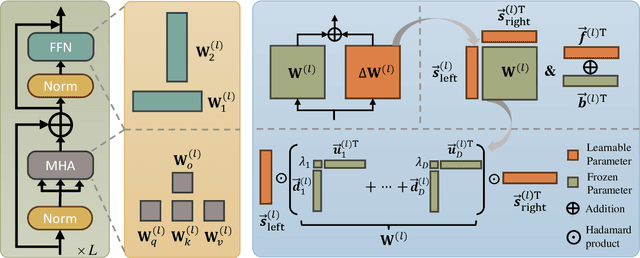

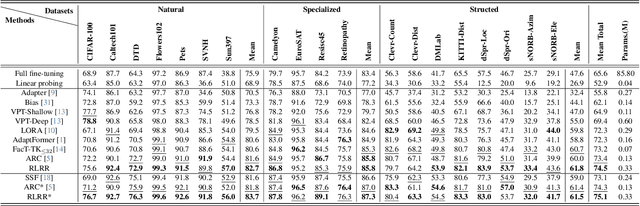
Parameter-efficient fine-tuning for pre-trained Vision Transformers aims to adeptly tailor a model to downstream tasks by learning a minimal set of new adaptation parameters while preserving the frozen majority of pre-trained parameters. Striking a balance between retaining the generalizable representation capacity of the pre-trained model and acquiring task-specific features poses a key challenge. Currently, there is a lack of focus on guiding this delicate trade-off. In this study, we approach the problem from the perspective of Singular Value Decomposition (SVD) of pre-trained parameter matrices, providing insights into the tuning dynamics of existing methods. Building upon this understanding, we propose a Residual-based Low-Rank Rescaling (RLRR) fine-tuning strategy. This strategy not only enhances flexibility in parameter tuning but also ensures that new parameters do not deviate excessively from the pre-trained model through a residual design. Extensive experiments demonstrate that our method achieves competitive performance across various downstream image classification tasks, all while maintaining comparable new parameters. We believe this work takes a step forward in offering a unified perspective for interpreting existing methods and serves as motivation for the development of new approaches that move closer to effectively considering the crucial trade-off mentioned above. Our code is available at \href{https://github.com/zstarN70/RLRR.git}{https://github.com/zstarN70/RLRR.git}.
Multi-View Active Sensing for Human-Robot Interaction via Hierarchically Connected Tree
Mar 19, 2024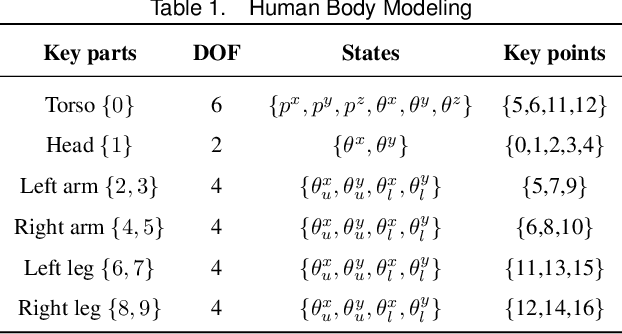
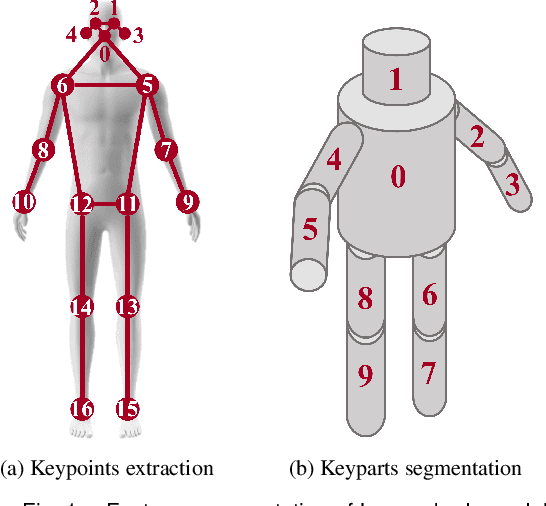
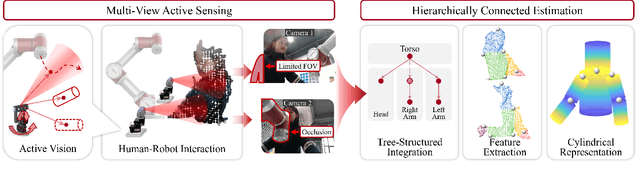
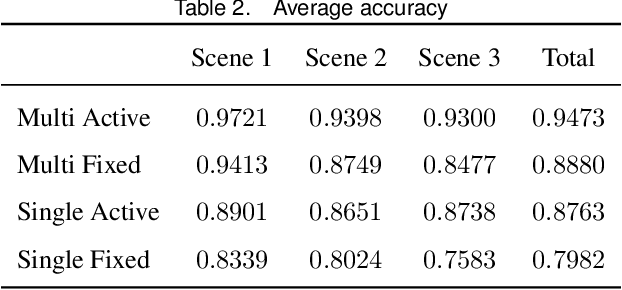
Comprehensive perception of human beings is the prerequisite to ensure the safety of human-robot interaction. Currently, prevailing visual sensing approach typically involves a single static camera, resulting in a restricted and occluded field of view. In our work, we develop an active vision system using multiple cameras to dynamically capture multi-source RGB-D data. An integrated human sensing strategy based on a hierarchically connected tree structure is proposed to fuse localized visual information. Constituting the tree model are the nodes representing keypoints and the edges representing keyparts, which are consistently interconnected to preserve the structural constraints during multi-source fusion. Utilizing RGB-D data and HRNet, the 3D positions of keypoints are analytically estimated, and their presence is inferred through a sliding widow of confidence scores. Subsequently, the point clouds of reliable keyparts are extracted by drawing occlusion-resistant masks, enabling fine registration between data clouds and cylindrical model following the hierarchical order. Experimental results demonstrate that our method enhances keypart recognition recall from 69.20% to 90.10%, compared to employing a single static camera. Furthermore, in overcoming challenges related to localized and occluded perception, the robotic arm's obstacle avoidance capabilities are effectively improved.
CEASE: Collision-Evaluation-based Active Sense System for Collaborative Robotic Arms
Mar 09, 2024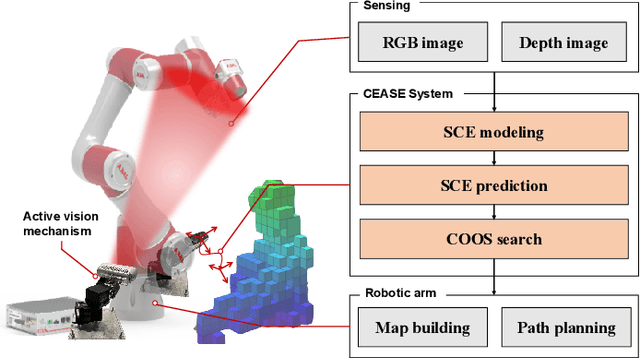
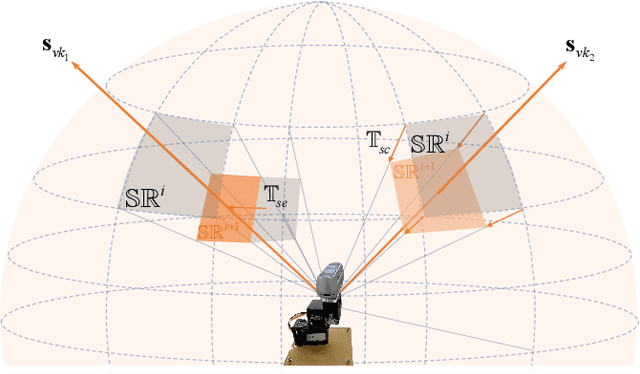
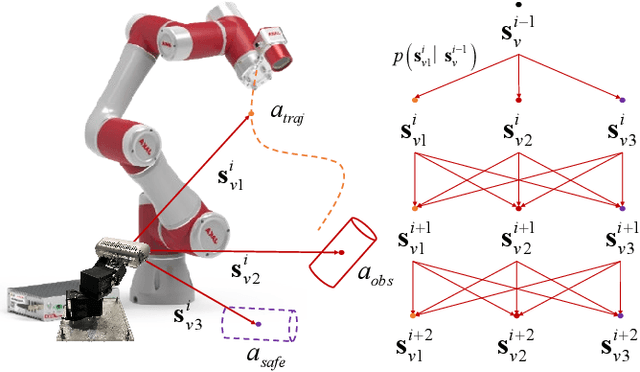

Collision detection via visual fences can significantly enhance the safety of collaborative robotic arms. Existing work typically performs such detection based on pre-deployed stationary cameras outside the robotic arm's workspace. These stationary cameras can only provide a restricted detection range and constrain the mobility of the robotic system. To cope with this issue, we propose an active sense method enabling a wide range of collision risk evaluation in dynamic scenarios. First, an active vision mechanism is implemented by equipping cameras with additional degrees of rotation. Considering the uncertainty in the active sense, we design a state confidence envelope to uniformly characterize both known and potential dynamic obstacles. Subsequently, using the observation-based uncertainty evolution, collision risk is evaluated by the prediction of obstacle envelopes. On this basis, a Markov decision process was employed to search for an optimal observation sequence of the active sense system, which enlarges the field of observation and reduces uncertainties in the state estimation of surrounding obstacles. Simulation and real-world experiments consistently demonstrate a 168% increase in the observation time coverage of typical dynamic humanoid obstacles compared to the method using stationary cameras, which underscores our system's effectiveness in collision risk tracking and enhancing the safety of robotic arms.
Real-Time Estimation of Relative Pose for UAVs Using a Dual-Channel Feature Association
Feb 27, 2024Leveraging multiple cameras on Unmanned Aerial Vehicles (UAVs) to form a variable-baseline stereo camera for collaborative perception is highly promising. The critical steps include high-rate cross-camera feature association and frame-rate relative pose estimation of multiple UAVs. To accelerate the feature association rate to match the frame rate, we propose a dual-channel structure to decouple the time-consuming feature detection and match from the high-rate image stream. The novel design of periodic guidance and fast prediction effectively utilizes each image frame to achieve a frame-rate feature association. Real-world experiments are executed using SuperPoint and SuperGlue on the NVIDIA NX 8G platform with a 30 Hz image stream. Using single-channel SuperPoint and SuperGlue can only achieve 13 Hz feature association. The proposed dual-channel method can improve the rate of feature association from 13 Hz to 30 Hz, supporting the frame-rate requirement. To accommodate the proposed feature association, we develop a Multi-State Constrained Kalman Filter (MSCKF)-based relative pose estimator in the back-end by fusing the local odometry from two UAVs together with the measurements of common features. Experiments show that the dual-channel feature association improves the rate of visual observation and enhances the real-time performance of back-end estimator compared to the existing methods. Video - https://youtu.be/UBAR1iP0GPk Supplementary video - https://youtu.be/nPq8EpVzJZM
Data-Centric Evolution in Autonomous Driving: A Comprehensive Survey of Big Data System, Data Mining, and Closed-Loop Technologies
Jan 26, 2024The aspiration of the next generation's autonomous driving (AD) technology relies on the dedicated integration and interaction among intelligent perception, prediction, planning, and low-level control. There has been a huge bottleneck regarding the upper bound of autonomous driving algorithm performance, a consensus from academia and industry believes that the key to surmount the bottleneck lies in data-centric autonomous driving technology. Recent advancement in AD simulation, closed-loop model training, and AD big data engine have gained some valuable experience. However, there is a lack of systematic knowledge and deep understanding regarding how to build efficient data-centric AD technology for AD algorithm self-evolution and better AD big data accumulation. To fill in the identified research gaps, this article will closely focus on reviewing the state-of-the-art data-driven autonomous driving technologies, with an emphasis on the comprehensive taxonomy of autonomous driving datasets characterized by milestone generations, key features, data acquisition settings, etc. Furthermore, we provide a systematic review of the existing benchmark closed-loop AD big data pipelines from the industrial frontier, including the procedure of closed-loop frameworks, key technologies, and empirical studies. Finally, the future directions, potential applications, limitations and concerns are discussed to arouse efforts from both academia and industry for promoting the further development of autonomous driving. The project repository is available at: https://github.com/LincanLi98/Awesome-Data-Centric-Autonomous-Driving.
Towards High-quality HDR Deghosting with Conditional Diffusion Models
Nov 02, 2023High Dynamic Range (HDR) images can be recovered from several Low Dynamic Range (LDR) images by existing Deep Neural Networks (DNNs) techniques. Despite the remarkable progress, DNN-based methods still generate ghosting artifacts when LDR images have saturation and large motion, which hinders potential applications in real-world scenarios. To address this challenge, we formulate the HDR deghosting problem as an image generation that leverages LDR features as the diffusion model's condition, consisting of the feature condition generator and the noise predictor. Feature condition generator employs attention and Domain Feature Alignment (DFA) layer to transform the intermediate features to avoid ghosting artifacts. With the learned features as conditions, the noise predictor leverages a stochastic iterative denoising process for diffusion models to generate an HDR image by steering the sampling process. Furthermore, to mitigate semantic confusion caused by the saturation problem of LDR images, we design a sliding window noise estimator to sample smooth noise in a patch-based manner. In addition, an image space loss is proposed to avoid the color distortion of the estimated HDR results. We empirically evaluate our model on benchmark datasets for HDR imaging. The results demonstrate that our approach achieves state-of-the-art performances and well generalization to real-world images.
Edge Cloud Collaborative Stream Computing for Real-Time Structural Health Monitoring
Oct 11, 2023Structural Health Monitoring (SHM) is crucial for the safety and maintenance of various infrastructures. Due to the large amount of data generated by numerous sensors and the high real-time requirements of many applications, SHM poses significant challenges. Although the cloud-centric stream computing paradigm opens new opportunities for real-time data processing, it consumes too much network bandwidth. In this paper, we propose ECStream, an Edge Cloud collaborative fine-grained stream operator scheduling framework for SHM. We collectively consider atomic and composite operators together with their iterative computability to model and formalize the problem of minimizing bandwidth usage and end-to-end operator processing latency. Preliminary evaluation results show that ECStream can effectively balance bandwidth usage and end-to-end operator computation latency, reducing bandwidth usage by 73.01% and latency by 34.08% on average compared to the cloud-centric approach.