 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuan Sun
DHRNet: A Dual-Path Hierarchical Relation Network for Multi-Person Pose Estimation
Apr 27, 2024
Multi-person pose estimation (MPPE) presents a formidable yet crucial challenge in computer vision. Most existing methods predominantly concentrate on isolated interaction either between instances or joints, which is inadequate for scenarios demanding concurrent localization of both instances and joints. This paper introduces a novel CNN-based single-stage method, named Dual-path Hierarchical Relation Network (DHRNet), to extract instance-to-joint and joint-to-instance interactions concurrently. Specifically, we design a dual-path interaction modeling module (DIM) that strategically organizes cross-instance and cross-joint interaction modeling modules in two complementary orders, enriching interaction information by integrating merits from different correlation modeling branches. Notably, DHRNet excels in joint localization by leveraging information from other instances and joints. Extensive evaluations on challenging datasets, including COCO, CrowdPose, and OCHuman datasets, showcase DHRNet's state-of-the-art performance. The code will be released at https://github.com/YHDang/dhrnet-multi-pose-estimation.
Evolutionary Multi-Objective Optimisation for Fairness-Aware Self Adjusting Memory Classifiers in Data Streams
Apr 18, 2024This paper introduces a novel approach, evolutionary multi-objective optimisation for fairness-aware self-adjusting memory classifiers, designed to enhance fairness in machine learning algorithms applied to data stream classification. With the growing concern over discrimination in algorithmic decision-making, particularly in dynamic data stream environments, there is a need for methods that ensure fair treatment of individuals across sensitive attributes like race or gender. The proposed approach addresses this challenge by integrating the strengths of the self-adjusting memory K-Nearest-Neighbour algorithm with evolutionary multi-objective optimisation. This combination allows the new approach to efficiently manage concept drift in streaming data and leverage the flexibility of evolutionary multi-objective optimisation to maximise accuracy and minimise discrimination simultaneously. We demonstrate the effectiveness of the proposed approach through extensive experiments on various datasets, comparing its performance against several baseline methods in terms of accuracy and fairness metrics. Our results show that the proposed approach maintains competitive accuracy and significantly reduces discrimination, highlighting its potential as a robust solution for fairness-aware data stream classification. Further analyses also confirm the effectiveness of the strategies to trigger evolutionary multi-objective optimisation and adapt classifiers in the proposed approach.
Genetic-based Constraint Programming for Resource Constrained Job Scheduling
Feb 01, 2024Resource constrained job scheduling is a hard combinatorial optimisation problem that originates in the mining industry. Off-the-shelf solvers cannot solve this problem satisfactorily in reasonable timeframes, while other solution methods such as many evolutionary computation methods and matheuristics cannot guarantee optimality and require low-level customisation and specialised heuristics to be effective. This paper addresses this gap by proposing a genetic programming algorithm to discover efficient search strategies of constraint programming for resource-constrained job scheduling. In the proposed algorithm, evolved programs represent variable selectors to be used in the search process of constraint programming, and their fitness is determined by the quality of solutions obtained for training instances. The novelties of this algorithm are (1) a new representation of variable selectors, (2) a new fitness evaluation scheme, and (3) a pre-selection mechanism. Tests with a large set of random and benchmark instances, the evolved variable selectors can significantly improve the efficiency of constraining programming. Compared to highly customised metaheuristics and hybrid algorithms, evolved variable selectors can help constraint programming identify quality solutions faster and proving optimality is possible if sufficiently large run-times are allowed. The evolved variable selectors are especially helpful when solving instances with large numbers of machines.
CamPro: Camera-based Anti-Facial Recognition
Dec 30, 2023The proliferation of images captured from millions of cameras and the advancement of facial recognition (FR) technology have made the abuse of FR a severe privacy threat. Existing works typically rely on obfuscation, synthesis, or adversarial examples to modify faces in images to achieve anti-facial recognition (AFR). However, the unmodified images captured by camera modules that contain sensitive personally identifiable information (PII) could still be leaked. In this paper, we propose a novel approach, CamPro, to capture inborn AFR images. CamPro enables well-packed commodity camera modules to produce images that contain little PII and yet still contain enough information to support other non-sensitive vision applications, such as person detection. Specifically, CamPro tunes the configuration setup inside the camera image signal processor (ISP), i.e., color correction matrix and gamma correction, to achieve AFR, and designs an image enhancer to keep the image quality for possible human viewers. We implemented and validated CamPro on a proof-of-concept camera, and our experiments demonstrate its effectiveness on ten state-of-the-art black-box FR models. The results show that CamPro images can significantly reduce face identification accuracy to 0.3\% while having little impact on the targeted non-sensitive vision application. Furthermore, we find that CamPro is resilient to adaptive attackers who have re-trained their FR models using images generated by CamPro, even with full knowledge of privacy-preserving ISP parameters.
iComMa: Inverting 3D Gaussians Splatting for Camera Pose Estimation via Comparing and Matching
Dec 14, 2023
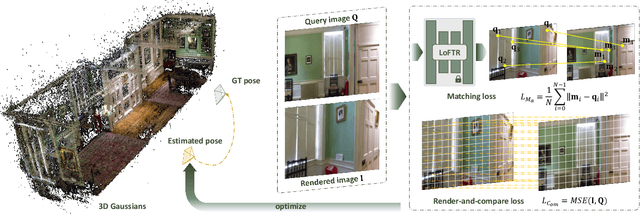


We present a method named iComMa to address the 6D pose estimation problem in computer vision. The conventional pose estimation methods typically rely on the target's CAD model or necessitate specific network training tailored to particular object classes. Some existing methods address mesh-free 6D pose estimation by employing the inversion of a Neural Radiance Field (NeRF), aiming to overcome the aforementioned constraints. However, it still suffers from adverse initializations. By contrast, we model the pose estimation as the problem of inverting the 3D Gaussian Splatting (3DGS) with both the comparing and matching loss. In detail, a render-and-compare strategy is adopted for the precise estimation of poses. Additionally, a matching module is designed to enhance the model's robustness against adverse initializations by minimizing the distances between 2D keypoints. This framework systematically incorporates the distinctive characteristics and inherent rationale of render-and-compare and matching-based approaches. This comprehensive consideration equips the framework to effectively address a broader range of intricate and challenging scenarios, including instances with substantial angular deviations, all while maintaining a high level of prediction accuracy. Experimental results demonstrate the superior precision and robustness of our proposed jointly optimized framework when evaluated on synthetic and complex real-world data in challenging scenarios.
Personalized Federated Learning via ADMM with Moreau Envelope
Nov 12, 2023Personalized federated learning (PFL) is an approach proposed to address the issue of poor convergence on heterogeneous data. However, most existing PFL frameworks require strong assumptions for convergence. In this paper, we propose an alternating direction method of multipliers (ADMM) for training PFL models with Moreau envelope (FLAME), which achieves a sublinear convergence rate, relying on the relatively weak assumption of gradient Lipschitz continuity. Moreover, due to the gradient-free nature of ADMM, FLAME alleviates the need for hyperparameter tuning, particularly in avoiding the adjustment of the learning rate when training the global model. In addition, we propose a biased client selection strategy to expedite the convergence of training of PFL models. Our theoretical analysis establishes the global convergence under both unbiased and biased client selection strategies. Our experiments validate that FLAME, when trained on heterogeneous data, outperforms state-of-the-art methods in terms of model performance. Regarding communication efficiency, it exhibits an average speedup of 3.75x compared to the baselines. Furthermore, experimental results validate that the biased client selection strategy speeds up the convergence of both personalized and global models.
Towards High-quality HDR Deghosting with Conditional Diffusion Models
Nov 02, 2023High Dynamic Range (HDR) images can be recovered from several Low Dynamic Range (LDR) images by existing Deep Neural Networks (DNNs) techniques. Despite the remarkable progress, DNN-based methods still generate ghosting artifacts when LDR images have saturation and large motion, which hinders potential applications in real-world scenarios. To address this challenge, we formulate the HDR deghosting problem as an image generation that leverages LDR features as the diffusion model's condition, consisting of the feature condition generator and the noise predictor. Feature condition generator employs attention and Domain Feature Alignment (DFA) layer to transform the intermediate features to avoid ghosting artifacts. With the learned features as conditions, the noise predictor leverages a stochastic iterative denoising process for diffusion models to generate an HDR image by steering the sampling process. Furthermore, to mitigate semantic confusion caused by the saturation problem of LDR images, we design a sliding window noise estimator to sample smooth noise in a patch-based manner. In addition, an image space loss is proposed to avoid the color distortion of the estimated HDR results. We empirically evaluate our model on benchmark datasets for HDR imaging. The results demonstrate that our approach achieves state-of-the-art performances and well generalization to real-world images.
Cross-modal Active Complementary Learning with Self-refining Correspondence
Oct 26, 2023Recently, image-text matching has attracted more and more attention from academia and industry, which is fundamental to understanding the latent correspondence across visual and textual modalities. However, most existing methods implicitly assume the training pairs are well-aligned while ignoring the ubiquitous annotation noise, a.k.a noisy correspondence (NC), thereby inevitably leading to a performance drop. Although some methods attempt to address such noise, they still face two challenging problems: excessive memorizing/overfitting and unreliable correction for NC, especially under high noise. To address the two problems, we propose a generalized Cross-modal Robust Complementary Learning framework (CRCL), which benefits from a novel Active Complementary Loss (ACL) and an efficient Self-refining Correspondence Correction (SCC) to improve the robustness of existing methods. Specifically, ACL exploits active and complementary learning losses to reduce the risk of providing erroneous supervision, leading to theoretically and experimentally demonstrated robustness against NC. SCC utilizes multiple self-refining processes with momentum correction to enlarge the receptive field for correcting correspondences, thereby alleviating error accumulation and achieving accurate and stable corrections. We carry out extensive experiments on three image-text benchmarks, i.e., Flickr30K, MS-COCO, and CC152K, to verify the superior robustness of our CRCL against synthetic and real-world noisy correspondences.
AI-Copilot for Business Optimisation: A Framework and A Case Study in Production Scheduling
Sep 29, 2023Business optimisation is the process of finding and implementing efficient and cost-effective means of operation to bring a competitive advantage for businesses. Synthesizing problem formulations is an integral part of business optimisation which is centred around human expertise, thus with a high potential of becoming a bottleneck. With the recent advancements in Large Language Models (LLMs), human expertise needed in problem formulation can potentially be minimized using Artificial Intelligence (AI). However, developing a LLM for problem formulation is challenging, due to training data requirements, token limitations, and the lack of appropriate performance metrics in LLMs. To minimize the requirement of large training data, considerable attention has recently been directed towards fine-tuning pre-trained LLMs for downstream tasks, rather than training a LLM from scratch for a specific task. In this paper, we adopt this approach and propose an AI-Copilot for business optimisation by fine-tuning a pre-trained LLM for problem formulation. To address token limitations, we introduce modularization and prompt engineering techniques to synthesize complex problem formulations as modules that fit into the token limits of LLMs. In addition, we design performance evaluation metrics that are more suitable for assessing the accuracy and quality of problem formulations compared to existing evaluation metrics. Experiment results demonstrate that our AI-Copilot can synthesize complex and large problem formulations for a typical business optimisation problem in production scheduling.
Rethinking superpixel segmentation from biologically inspired mechanisms
Sep 23, 2023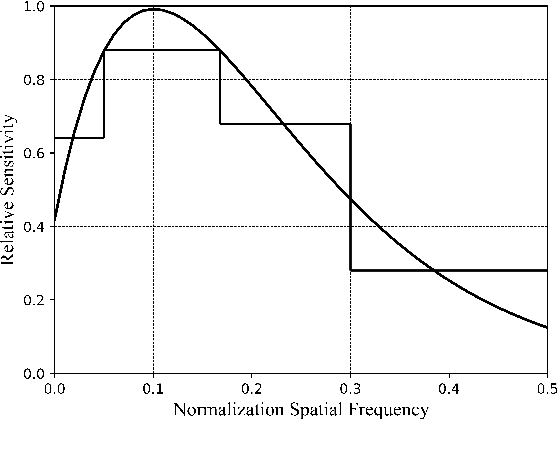
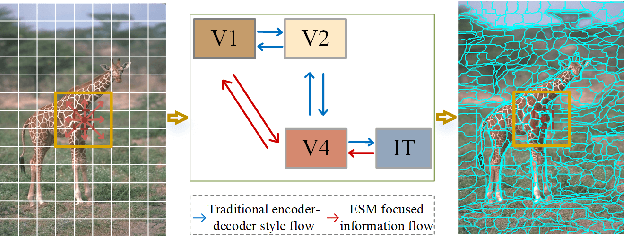

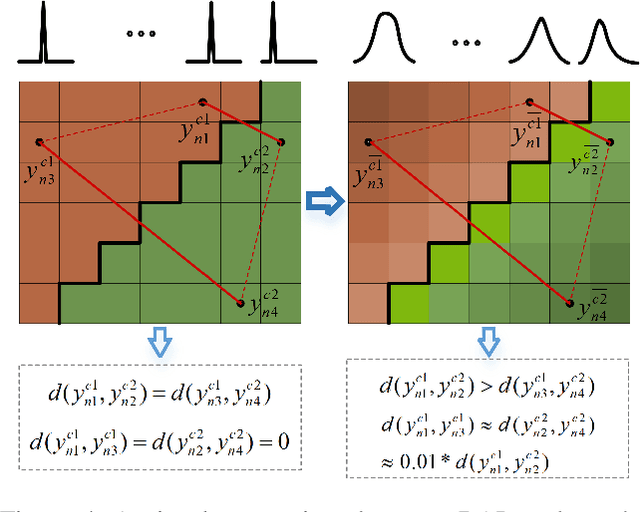
Recently, advancements in deep learning-based superpixel segmentation methods have brought about improvements in both the efficiency and the performance of segmentation. However, a significant challenge remains in generating superpixels that strictly adhere to object boundaries while conveying rich visual significance, especially when cross-surface color correlations may interfere with objects. Drawing inspiration from neural structure and visual mechanisms, we propose a biological network architecture comprising an Enhanced Screening Module (ESM) and a novel Boundary-Aware Label (BAL) for superpixel segmentation. The ESM enhances semantic information by simulating the interactive projection mechanisms of the visual cortex. Additionally, the BAL emulates the spatial frequency characteristics of visual cortical cells to facilitate the generation of superpixels with strong boundary adherence. We demonstrate the effectiveness of our approach through evaluations on both the BSDS500 dataset and the NYUv2 dataset.