 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePengxiang Ding
DHRNet: A Dual-Path Hierarchical Relation Network for Multi-Person Pose Estimation
Apr 27, 2024
Multi-person pose estimation (MPPE) presents a formidable yet crucial challenge in computer vision. Most existing methods predominantly concentrate on isolated interaction either between instances or joints, which is inadequate for scenarios demanding concurrent localization of both instances and joints. This paper introduces a novel CNN-based single-stage method, named Dual-path Hierarchical Relation Network (DHRNet), to extract instance-to-joint and joint-to-instance interactions concurrently. Specifically, we design a dual-path interaction modeling module (DIM) that strategically organizes cross-instance and cross-joint interaction modeling modules in two complementary orders, enriching interaction information by integrating merits from different correlation modeling branches. Notably, DHRNet excels in joint localization by leveraging information from other instances and joints. Extensive evaluations on challenging datasets, including COCO, CrowdPose, and OCHuman datasets, showcase DHRNet's state-of-the-art performance. The code will be released at https://github.com/YHDang/dhrnet-multi-pose-estimation.
Towards more realistic human motion prediction with attention to motion coordination
Apr 04, 2024Joint relation modeling is a curial component in human motion prediction. Most existing methods rely on skeletal-based graphs to build the joint relations, where local interactive relations between joint pairs are well learned. However, the motion coordination, a global joint relation reflecting the simultaneous cooperation of all joints, is usually weakened because it is learned from part to whole progressively and asynchronously. Thus, the final predicted motions usually appear unrealistic. To tackle this issue, we learn a medium, called coordination attractor (CA), from the spatiotemporal features of motion to characterize the global motion features, which is subsequently used to build new relative joint relations. Through the CA, all joints are related simultaneously, and thus the motion coordination of all joints can be better learned. Based on this, we further propose a novel joint relation modeling module, Comprehensive Joint Relation Extractor (CJRE), to combine this motion coordination with the local interactions between joint pairs in a unified manner. Additionally, we also present a Multi-timescale Dynamics Extractor (MTDE) to extract enriched dynamics from the raw position information for effective prediction. Extensive experiments show that the proposed framework outperforms state-of-the-art methods in both short- and long-term predictions on H3.6M, CMU-Mocap, and 3DPW.
Cobra: Extending Mamba to Multi-Modal Large Language Model for Efficient Inference
Mar 22, 2024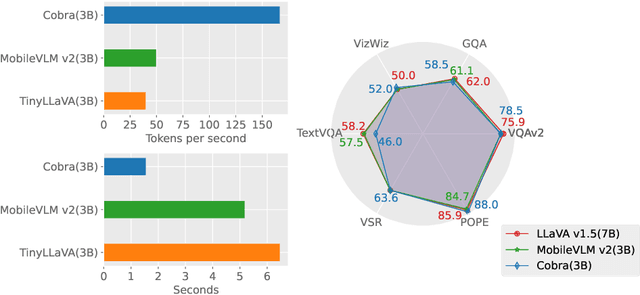
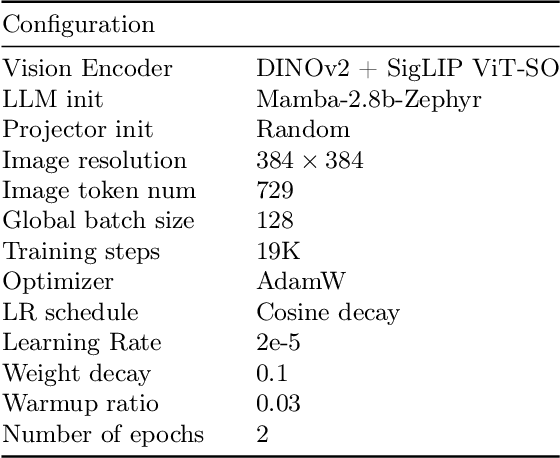
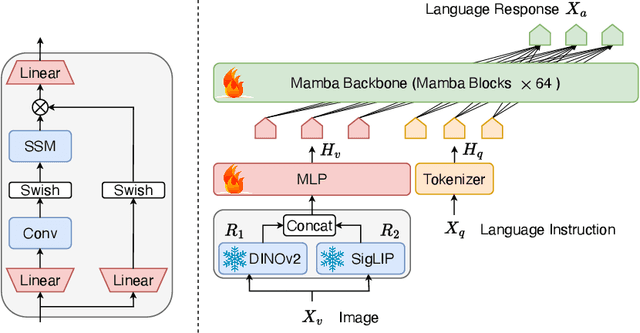
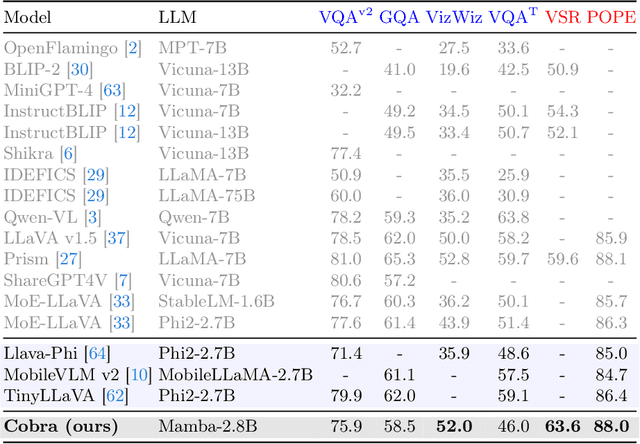
In recent years, the application of multimodal large language models (MLLM) in various fields has achieved remarkable success. However, as the foundation model for many downstream tasks, current MLLMs are composed of the well-known Transformer network, which has a less efficient quadratic computation complexity. To improve the efficiency of such basic models, we propose Cobra, a linear computational complexity MLLM. Specifically, Cobra integrates the efficient Mamba language model into the visual modality. Moreover, we explore and study various modal fusion schemes to create an effective multi-modal Mamba. Extensive experiments demonstrate that (1) Cobra achieves extremely competitive performance with current computationally efficient state-of-the-art methods, e.g., LLaVA-Phi, TinyLLaVA, and MobileVLM v2, and has faster speed due to Cobra's linear sequential modeling. (2) Interestingly, the results of closed-set challenging prediction benchmarks show that Cobra performs well in overcoming visual illusions and spatial relationship judgments. (3) Notably, Cobra even achieves comparable performance to LLaVA with about 43% of the number of parameters. We will make all codes of Cobra open-source and hope that the proposed method can facilitate future research on complexity problems in MLLM. Our project page is available at: https://sites.google.com/view/cobravlm.
GeRM: A Generalist Robotic Model with Mixture-of-experts for Quadruped Robot
Mar 20, 2024

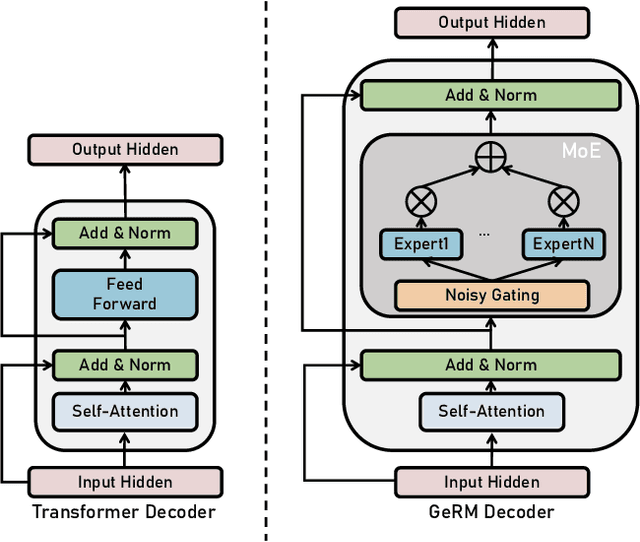
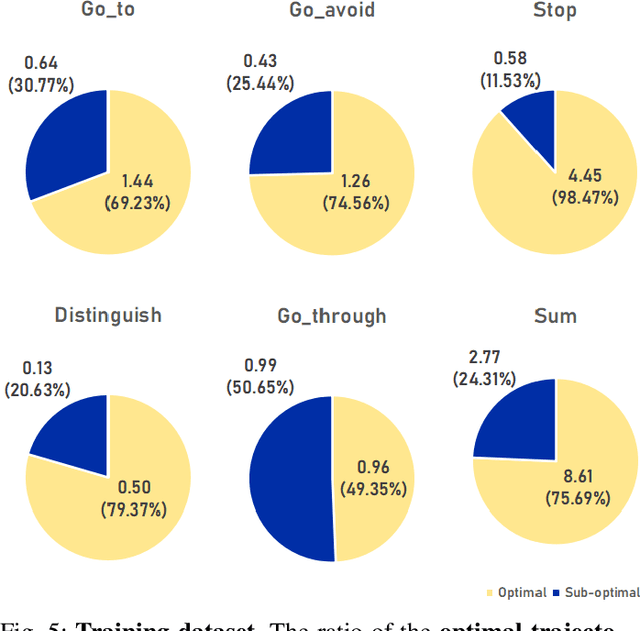
Multi-task robot learning holds significant importance in tackling diverse and complex scenarios. However, current approaches are hindered by performance issues and difficulties in collecting training datasets. In this paper, we propose GeRM (Generalist Robotic Model). We utilize offline reinforcement learning to optimize data utilization strategies to learn from both demonstrations and sub-optimal data, thus surpassing the limitations of human demonstrations. Thereafter, we employ a transformer-based VLA network to process multi-modal inputs and output actions. By introducing the Mixture-of-Experts structure, GeRM allows faster inference speed with higher whole model capacity, and thus resolves the issue of limited RL parameters, enhancing model performance in multi-task learning while controlling computational costs. Through a series of experiments, we demonstrate that GeRM outperforms other methods across all tasks, while also validating its efficiency in both training and inference processes. Additionally, we uncover its potential to acquire emergent skills. Additionally, we contribute the QUARD-Auto dataset, collected automatically to support our training approach and foster advancements in multi-task quadruped robot learning. This work presents a new paradigm for reducing the cost of collecting robot data and driving progress in the multi-task learning community.
QUAR-VLA: Vision-Language-Action Model for Quadruped Robots
Dec 22, 2023



The important manifestation of robot intelligence is the ability to naturally interact and autonomously make decisions. Traditional approaches to robot control often compartmentalize perception, planning, and decision-making, simplifying system design but limiting the synergy between different information streams. This compartmentalization poses challenges in achieving seamless autonomous reasoning, decision-making, and action execution. To address these limitations, a novel paradigm, named Vision-Language-Action tasks for QUAdruped Robots (QUAR-VLA), has been introduced in this paper. This approach tightly integrates visual information and instructions to generate executable actions, effectively merging perception, planning, and decision-making. The central idea is to elevate the overall intelligence of the robot. Within this framework, a notable challenge lies in aligning fine-grained instructions with visual perception information. This emphasizes the complexity involved in ensuring that the robot accurately interprets and acts upon detailed instructions in harmony with its visual observations. Consequently, we propose QUAdruped Robotic Transformer (QUART), a family of VLA models to integrate visual information and instructions from diverse modalities as input and generates executable actions for real-world robots and present QUAdruped Robot Dataset (QUARD), a large-scale multi-task dataset including navigation, complex terrain locomotion, and whole-body manipulation tasks for training QUART models. Our extensive evaluation (4000 evaluation trials) shows that our approach leads to performant robotic policies and enables QUART to obtain a range of emergent capabilities.
Expressive Forecasting of 3D Whole-body Human Motions
Dec 19, 2023Human motion forecasting, with the goal of estimating future human behavior over a period of time, is a fundamental task in many real-world applications. However, existing works typically concentrate on predicting the major joints of the human body without considering the delicate movements of the human hands. In practical applications, hand gesture plays an important role in human communication with the real world, and expresses the primary intention of human beings. In this work, we are the first to formulate a whole-body human pose forecasting task, which jointly predicts the future body and hand activities. Correspondingly, we propose a novel Encoding-Alignment-Interaction (EAI) framework that aims to predict both coarse (body joints) and fine-grained (gestures) activities collaboratively, enabling expressive and cross-facilitated forecasting of 3D whole-body human motions. Specifically, our model involves two key constituents: cross-context alignment (XCA) and cross-context interaction (XCI). Considering the heterogeneous information within the whole-body, XCA aims to align the latent features of various human components, while XCI focuses on effectively capturing the context interaction among the human components. We conduct extensive experiments on a newly-introduced large-scale benchmark and achieve state-of-the-art performance. The code is public for research purposes at https://github.com/Dingpx/EAI.
Instance-incremental Scene Graph Generation from Real-world Point Clouds via Normalizing Flows
Feb 21, 2023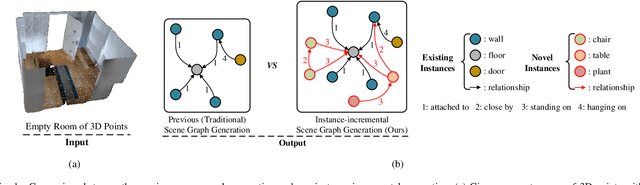
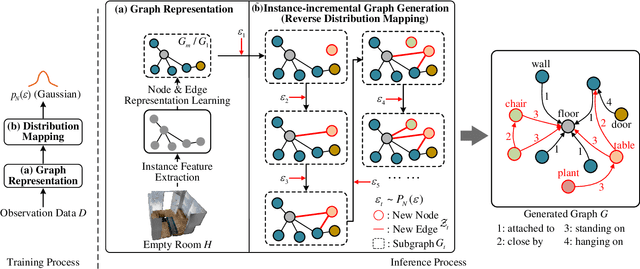
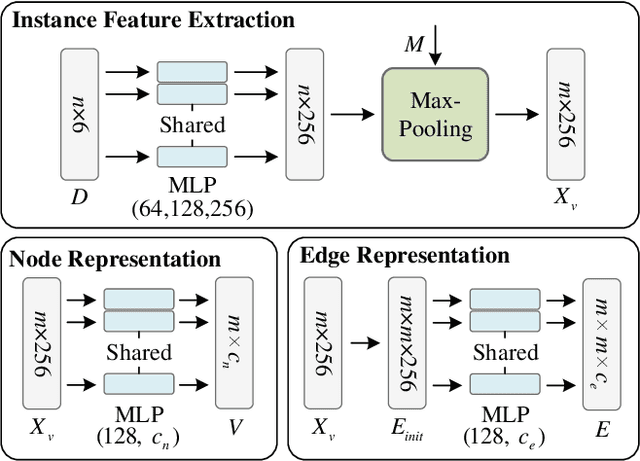
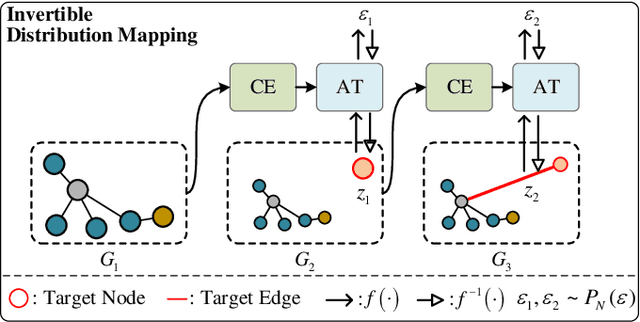
This work introduces a new task of instance-incremental scene graph generation: Given an empty room of the point cloud, representing it as a graph and automatically increasing novel instances. A graph denoting the object layout of the scene is finally generated. It is an important task since it helps to guide the insertion of novel 3D objects into a real-world scene in vision-based applications like augmented reality. It is also challenging because the complexity of the real-world point cloud brings difficulties in learning object layout experiences from the observation data (non-empty rooms with labeled semantics). We model this task as a conditional generation problem and propose a 3D autoregressive framework based on normalizing flows (3D-ANF) to address it. We first represent the point cloud as a graph by extracting the containing label semantics and contextual relationships. Next, a model based on normalizing flows is introduced to map the conditional generation of graphic elements into the Gaussian process. The mapping is invertible. Thus, the real-world experiences represented in the observation data can be modeled in the training phase, and novel instances can be sequentially generated based on the Gaussian process in the testing phase. We implement this new task on the dataset of 3D point-based scenes (3DSSG and 3RScan) and evaluate the performance of our method. Experiments show that our method generates reliable novel graphs from the real-world point cloud and achieves state-of-the-art performance on the benchmark dataset.
Uncertainty-aware Human Motion Prediction
Jul 08, 2021



Human motion prediction is essential for tasks such as human motion analysis and human-robot interactions. Most existing approaches have been proposed to realize motion prediction. However, they ignore an important task, the evaluation of the quality of the predicted result. It is far more enough for current approaches in actual scenarios because people can't know how to interact with the machine without the evaluation of prediction, and unreliable predictions may mislead the machine to harm the human. Hence, we propose an uncertainty-aware framework for human motion prediction (UA-HMP). Concretely, we first design an uncertainty-aware predictor through Gaussian modeling to achieve the value and the uncertainty of predicted motion. Then, an uncertainty-guided learning scheme is proposed to quantitate the uncertainty and reduce the negative effect of the noisy samples during optimization for better performance. Our proposed framework is easily combined with current SOTA baselines to overcome their weakness in uncertainty modeling with slight parameters increment. Extensive experiments also show that they can achieve better performance in both short and long-term predictions in H3.6M, CMU-Mocap.
An Attractor-Guided Neural Networks for Skeleton-Based Human Motion Prediction
May 20, 2021



Joint relation modeling is a curial component in human motion prediction. Most existing methods tend to design skeletal-based graphs to build the relations among joints, where local interactions between joint pairs are well learned. However, the global coordination of all joints, which reflects human motion's balance property, is usually weakened because it is learned from part to whole progressively and asynchronously. Thus, the final predicted motions are sometimes unnatural. To tackle this issue, we learn a medium, called balance attractor (BA), from the spatiotemporal features of motion to characterize the global motion features, which is subsequently used to build new joint relations. Through the BA, all joints are related synchronously, and thus the global coordination of all joints can be better learned. Based on the BA, we propose our framework, referred to Attractor-Guided Neural Network, mainly including Attractor-Based Joint Relation Extractor (AJRE) and Multi-timescale Dynamics Extractor (MTDE). The AJRE mainly includes Global Coordination Extractor (GCE) and Local Interaction Extractor (LIE). The former presents the global coordination of all joints, and the latter encodes local interactions between joint pairs. The MTDE is designed to extract dynamic information from raw position information for effective prediction. Extensive experiments show that the proposed framework outperforms state-of-the-art methods in both short and long-term predictions in H3.6M, CMU-Mocap, and 3DPW.