 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiyuan Liu
DHRNet: A Dual-Path Hierarchical Relation Network for Multi-Person Pose Estimation
Apr 27, 2024
Multi-person pose estimation (MPPE) presents a formidable yet crucial challenge in computer vision. Most existing methods predominantly concentrate on isolated interaction either between instances or joints, which is inadequate for scenarios demanding concurrent localization of both instances and joints. This paper introduces a novel CNN-based single-stage method, named Dual-path Hierarchical Relation Network (DHRNet), to extract instance-to-joint and joint-to-instance interactions concurrently. Specifically, we design a dual-path interaction modeling module (DIM) that strategically organizes cross-instance and cross-joint interaction modeling modules in two complementary orders, enriching interaction information by integrating merits from different correlation modeling branches. Notably, DHRNet excels in joint localization by leveraging information from other instances and joints. Extensive evaluations on challenging datasets, including COCO, CrowdPose, and OCHuman datasets, showcase DHRNet's state-of-the-art performance. The code will be released at https://github.com/YHDang/dhrnet-multi-pose-estimation.
Learning a Decision Tree Algorithm with Transformers
Feb 06, 2024Decision trees are renowned for their interpretability capability to achieve high predictive performance, especially on tabular data. Traditionally, they are constructed through recursive algorithms, where they partition the data at every node in a tree. However, identifying the best partition is challenging, as decision trees optimized for local segments may not bring global generalization. To address this, we introduce MetaTree, which trains a transformer-based model on filtered outputs from classical algorithms to produce strong decision trees for classification. Specifically, we fit both greedy decision trees and optimized decision trees on a large number of datasets. We then train MetaTree to produce the trees that achieve strong generalization performance. This training enables MetaTree to not only emulate these algorithms, but also to intelligently adapt its strategy according to the context, thereby achieving superior generalization performance.
Tell Your Model Where to Attend: Post-hoc Attention Steering for LLMs
Nov 03, 2023In human-written articles, we often leverage the subtleties of text style, such as bold and italics, to guide the attention of readers. These textual emphases are vital for the readers to grasp the conveyed information. When interacting with large language models (LLMs), we have a similar need - steering the model to pay closer attention to user-specified information, e.g., an instruction. Existing methods, however, are constrained to process plain text and do not support such a mechanism. This motivates us to introduce PASTA - Post-hoc Attention STeering Approach, a method that allows LLMs to read text with user-specified emphasis marks. To this end, PASTA identifies a small subset of attention heads and applies precise attention reweighting on them, directing the model attention to user-specified parts. Like prompting, PASTA is applied at inference time and does not require changing any model parameters. Experiments demonstrate that PASTA can substantially enhance an LLM's ability to follow user instructions or integrate new knowledge from user inputs, leading to a significant performance improvement on a variety of tasks, e.g., an average accuracy improvement of 22% for LLAMA-7B. Our code is publicly available at https://github.com/QingruZhang/PASTA .
Fast-ELECTRA for Efficient Pre-training
Oct 11, 2023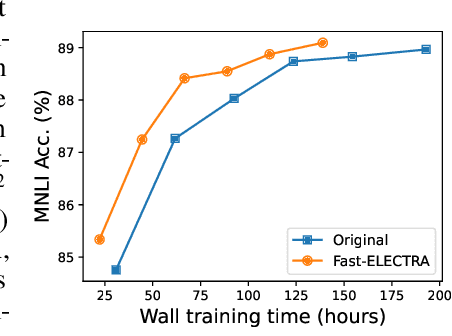
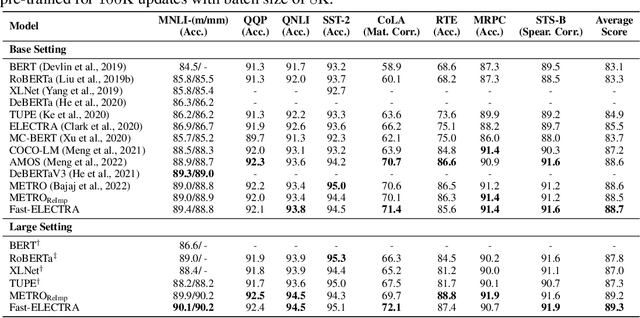
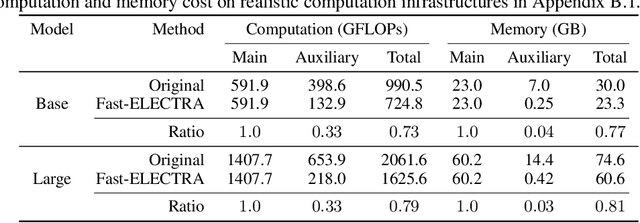
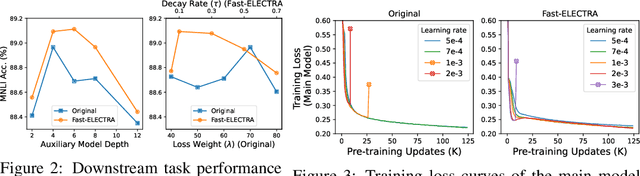
ELECTRA pre-trains language models by detecting tokens in a sequence that have been replaced by an auxiliary model. Although ELECTRA offers a significant boost in efficiency, its potential is constrained by the training cost brought by the auxiliary model. Notably, this model, which is jointly trained with the main model, only serves to assist the training of the main model and is discarded post-training. This results in a substantial amount of training cost being expended in vain. To mitigate this issue, we propose Fast-ELECTRA, which leverages an existing language model as the auxiliary model. To construct a learning curriculum for the main model, we smooth its output distribution via temperature scaling following a descending schedule. Our approach rivals the performance of state-of-the-art ELECTRA-style pre-training methods, while significantly eliminating the computation and memory cost brought by the joint training of the auxiliary model. Our method also reduces the sensitivity to hyper-parameters and enhances the pre-training stability.
Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs
Oct 07, 2023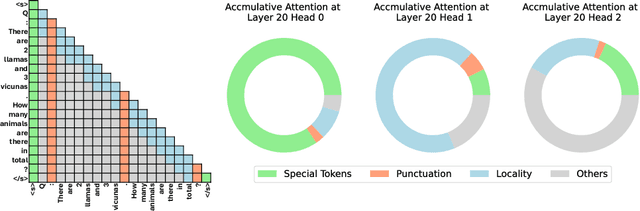
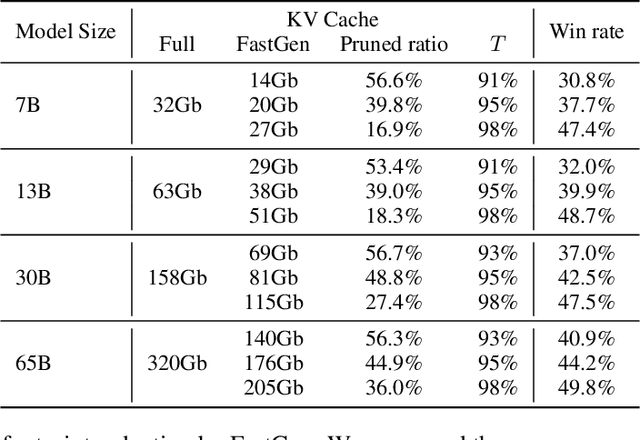
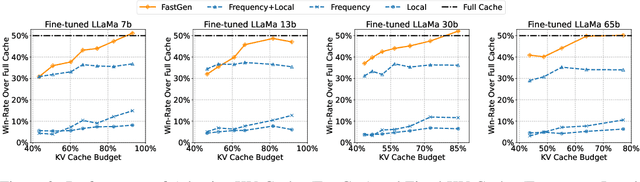

In this study, we introduce adaptive KV cache compression, a plug-and-play method that reduces the memory footprint of generative inference for Large Language Models (LLMs). Different from the conventional KV cache that retains key and value vectors for all context tokens, we conduct targeted profiling to discern the intrinsic structure of attention modules. Based on the recognized structure, we then construct the KV cache in an adaptive manner: evicting long-range contexts on attention heads emphasizing local contexts, discarding non-special tokens on attention heads centered on special tokens, and only employing the standard KV cache for attention heads that broadly attend to all tokens. Moreover, with the lightweight attention profiling used to guide the construction of the adaptive KV cache, FastGen can be deployed without resource-intensive fine-tuning or re-training. In our experiments across various asks, FastGen demonstrates substantial reduction on GPU memory consumption with negligible generation quality loss. We will release our code and the compatible CUDA kernel for reproducibility.
Sparse Backpropagation for MoE Training
Oct 01, 2023One defining characteristic of Mixture-of-Expert (MoE) models is their capacity for conducting sparse computation via expert routing, leading to remarkable scalability. However, backpropagation, the cornerstone of deep learning, requires dense computation, thereby posting challenges in MoE gradient computations. Here, we introduce SparseMixer, a scalable gradient estimator that bridges the gap between backpropagation and sparse expert routing. Unlike typical MoE training which strategically neglects certain gradient terms for the sake of sparse computation and scalability, SparseMixer provides scalable gradient approximations for these terms, enabling reliable gradient estimation in MoE training. Grounded in a numerical ODE framework, SparseMixer harnesses the mid-point method, a second-order ODE solver, to deliver precise gradient approximations with negligible computational overhead. Applying SparseMixer to Switch Transformer on both pre-training and machine translation tasks, SparseMixer showcases considerable performance gain, accelerating training convergence up to 2 times.
Bridging Discrete and Backpropagation: Straight-Through and Beyond
Apr 17, 2023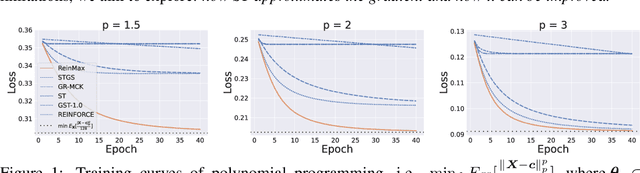

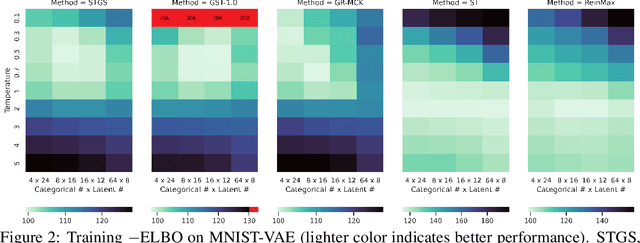

Backpropagation, the cornerstone of deep learning, is limited to computing gradients solely for continuous variables. This limitation hinders various research on problems involving discrete latent variables. To address this issue, we propose a novel approach for approximating the gradient of parameters involved in generating discrete latent variables. First, we examine the widely used Straight-Through (ST) heuristic and demonstrate that it works as a first-order approximation of the gradient. Guided by our findings, we propose a novel method called ReinMax, which integrates Heun's Method, a second-order numerical method for solving ODEs, to approximate the gradient. Our method achieves second-order accuracy without requiring Hessian or other second-order derivatives. We conduct experiments on structured output prediction and unsupervised generative modeling tasks. Our results show that \ours brings consistent improvements over the state of the art, including ST and Straight-Through Gumbel-Softmax. Implementations are released at https://github.com/microsoft/ReinMax.
SoTeacher: A Student-oriented Teacher Network Training Framework for Knowledge Distillation
Jun 14, 2022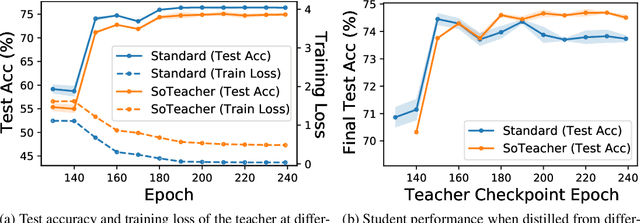
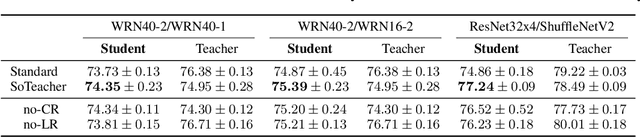
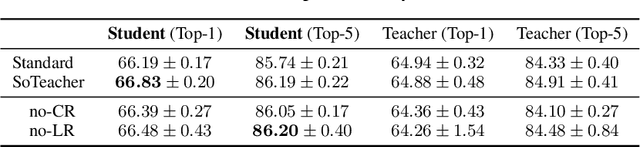
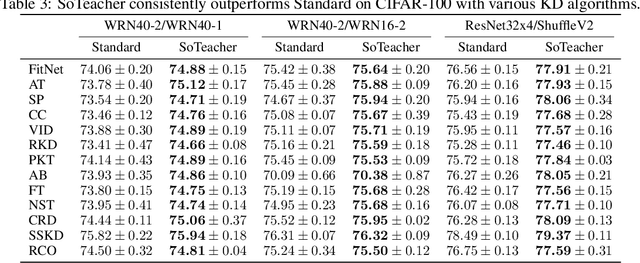
How to train an ideal teacher for knowledge distillation is still an open problem. It has been widely observed that a teacher minimizing the empirical risk not necessarily yields the best performing student, suggesting a fundamental discrepancy between the common practice in teacher network training and the distillation objective. To fill this gap, we propose a novel student-oriented teacher network training framework SoTeacher, inspired by recent findings that student performance hinges on teacher's capability to approximate the true label distribution of training samples. We theoretically established that (1) the empirical risk minimizer with proper scoring rules as loss function can provably approximate the true label distribution of training data if the hypothesis function is locally Lipschitz continuous around training samples; and (2) when data augmentation is employed for training, an additional constraint is required that the minimizer has to produce consistent predictions across augmented views of the same training input. In light of our theory, SoTeacher renovates the empirical risk minimization by incorporating Lipschitz regularization and consistency regularization. It is worth mentioning that SoTeacher is applicable to almost all teacher-student architecture pairs, requires no prior knowledge of the student upon teacher's training, and induces almost no computation overhead. Experiments on two benchmark datasets confirm that SoTeacher can improve student performance significantly and consistently across various knowledge distillation algorithms and teacher-student pairs.
PILED: An Identify-and-Localize Framework for Few-Shot Event Detection
Feb 15, 2022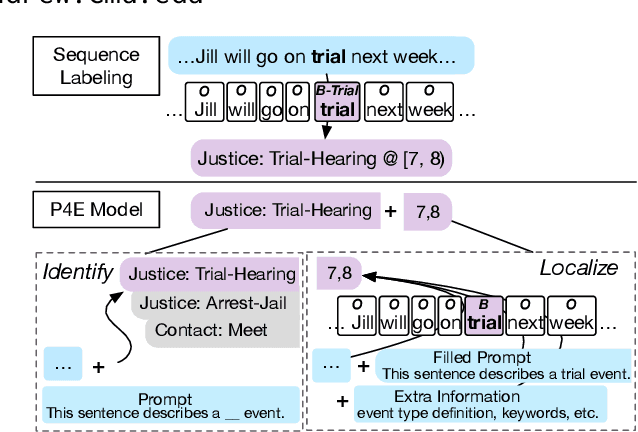
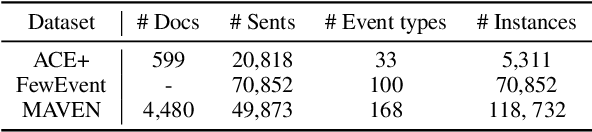
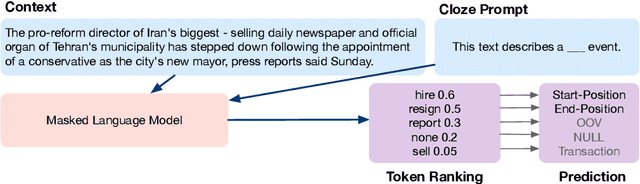
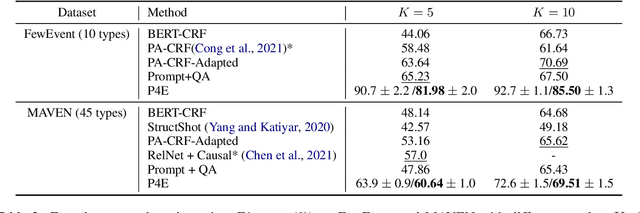
Practical applications of event extraction systems have long been hindered by their need for heavy human annotation. In order to scale up to new domains and event types, models must learn to cope with limited supervision, as in few-shot learning settings. To this end, the major challenge is to let the model master the semantics of event types, without requiring abundant event mention annotations. In our study, we employ cloze prompts to elicit event-related knowledge from pretrained language models and further use event definitions and keywords to pinpoint the trigger word. By formulating the event detection task as an identify-then-localize procedure, we minimize the number of type-specific parameters, enabling our model to quickly adapt to event detection tasks for new types. Experiments on three event detection benchmark datasets (ACE, FewEvent, MAVEN) show that our proposed method performs favorably under fully supervised settings and surpasses existing few-shot methods by 21% F1 on the FewEvent dataset and 20% on the MAVEN dataset when only 5 examples are provided for each event type.
Double Descent in Adversarial Training: An Implicit Label Noise Perspective
Oct 07, 2021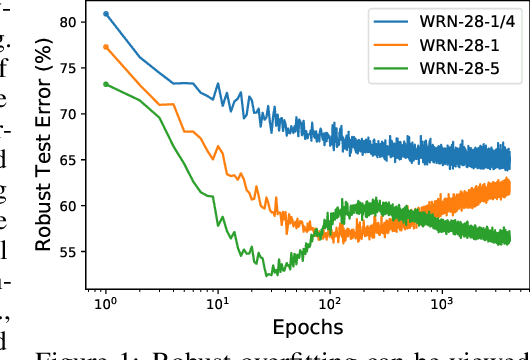
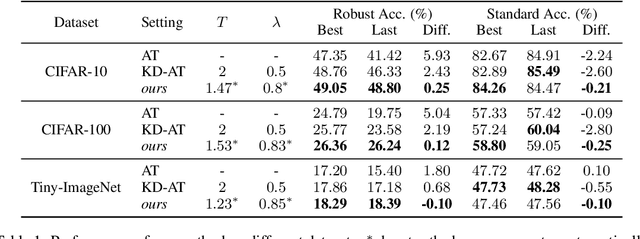
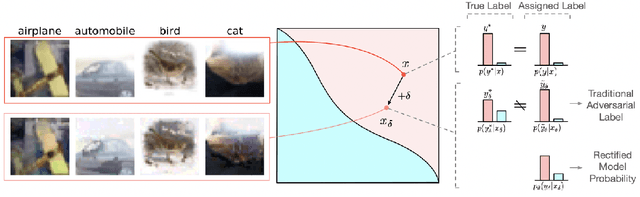

Here, we show that the robust overfitting shall be viewed as the early part of an epoch-wise double descent -- the robust test error will start to decrease again after training the model for a considerable number of epochs. Inspired by our observations, we further advance the analyses of double descent to understand robust overfitting better. In standard training, double descent has been shown to be a result of label flipping noise. However, this reasoning is not applicable in our setting, since adversarial perturbations are believed not to change the label. Going beyond label flipping noise, we propose to measure the mismatch between the assigned and (unknown) true label distributions, denoted as \emph{implicit label noise}. We show that the traditional labeling of adversarial examples inherited from their clean counterparts will lead to implicit label noise. Towards better labeling, we show that predicted distribution from a classifier, after scaling and interpolation, can provably reduce the implicit label noise under mild assumptions. In light of our analyses, we tailored the training objective accordingly to effectively mitigate the double descent and verified its effectiveness on three benchmark datasets.