 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChandan Singh
Attribute Structuring Improves LLM-Based Evaluation of Clinical Text Summaries
Mar 01, 2024
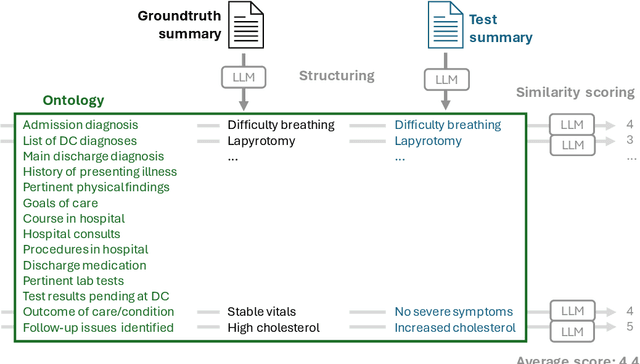
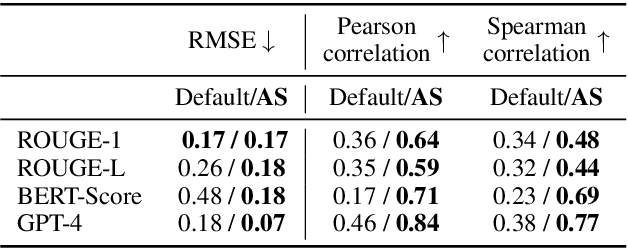
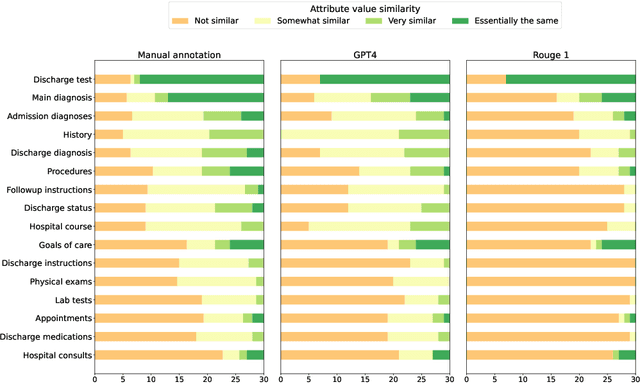
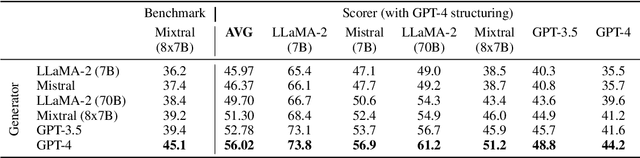
Summarizing clinical text is crucial in health decision-support and clinical research. Large language models (LLMs) have shown the potential to generate accurate clinical text summaries, but still struggle with issues regarding grounding and evaluation, especially in safety-critical domains such as health. Holistically evaluating text summaries is challenging because they may contain unsubstantiated information. Here, we explore a general mitigation framework using Attribute Structuring (AS), which structures the summary evaluation process. It decomposes the evaluation process into a grounded procedure that uses an LLM for relatively simple structuring and scoring tasks, rather than the full task of holistic summary evaluation. Experiments show that AS consistently improves the correspondence between human annotations and automated metrics in clinical text summarization. Additionally, AS yields interpretations in the form of a short text span corresponding to each output, which enables efficient human auditing, paving the way towards trustworthy evaluation of clinical information in resource-constrained scenarios. We release our code, prompts, and an open-source benchmark at https://github.com/microsoft/attribute-structuring.
Learning a Decision Tree Algorithm with Transformers
Feb 06, 2024Decision trees are renowned for their interpretability capability to achieve high predictive performance, especially on tabular data. Traditionally, they are constructed through recursive algorithms, where they partition the data at every node in a tree. However, identifying the best partition is challenging, as decision trees optimized for local segments may not bring global generalization. To address this, we introduce MetaTree, which trains a transformer-based model on filtered outputs from classical algorithms to produce strong decision trees for classification. Specifically, we fit both greedy decision trees and optimized decision trees on a large number of datasets. We then train MetaTree to produce the trees that achieve strong generalization performance. This training enables MetaTree to not only emulate these algorithms, but also to intelligently adapt its strategy according to the context, thereby achieving superior generalization performance.
Rethinking Interpretability in the Era of Large Language Models
Jan 30, 2024Interpretable machine learning has exploded as an area of interest over the last decade, sparked by the rise of increasingly large datasets and deep neural networks. Simultaneously, large language models (LLMs) have demonstrated remarkable capabilities across a wide array of tasks, offering a chance to rethink opportunities in interpretable machine learning. Notably, the capability to explain in natural language allows LLMs to expand the scale and complexity of patterns that can be given to a human. However, these new capabilities raise new challenges, such as hallucinated explanations and immense computational costs. In this position paper, we start by reviewing existing methods to evaluate the emerging field of LLM interpretation (both interpreting LLMs and using LLMs for explanation). We contend that, despite their limitations, LLMs hold the opportunity to redefine interpretability with a more ambitious scope across many applications, including in auditing LLMs themselves. We highlight two emerging research priorities for LLM interpretation: using LLMs to directly analyze new datasets and to generate interactive explanations.
Towards Consistent Natural-Language Explanations via Explanation-Consistency Finetuning
Jan 25, 2024Large language models (LLMs) often generate convincing, fluent explanations. However, different from humans, they often generate inconsistent explanations on different inputs. For example, an LLM may generate the explanation "all birds can fly" when answering the question "Can sparrows fly?" but meanwhile answer "no" to the related question "Can penguins fly?". Explanations should be consistent across related examples so that they allow a human to simulate the LLM's decision process on multiple examples. We propose explanation-consistency finetuning (EC-finetuning), a method that adapts LLMs to generate more consistent natural-language explanations on related examples. EC-finetuning involves finetuning LLMs on synthetic data that is carefully constructed to contain consistent explanations. Across a variety of question-answering datasets in various domains, EC-finetuning yields a 10.0% relative explanation consistency improvement on four finetuning datasets, and generalizes to seven out-of-distribution datasets not seen during finetuning (+4.5% relative). Code is available at https://github.com/yandachen/explanation-consistency-finetuning .
Tell Your Model Where to Attend: Post-hoc Attention Steering for LLMs
Nov 03, 2023In human-written articles, we often leverage the subtleties of text style, such as bold and italics, to guide the attention of readers. These textual emphases are vital for the readers to grasp the conveyed information. When interacting with large language models (LLMs), we have a similar need - steering the model to pay closer attention to user-specified information, e.g., an instruction. Existing methods, however, are constrained to process plain text and do not support such a mechanism. This motivates us to introduce PASTA - Post-hoc Attention STeering Approach, a method that allows LLMs to read text with user-specified emphasis marks. To this end, PASTA identifies a small subset of attention heads and applies precise attention reweighting on them, directing the model attention to user-specified parts. Like prompting, PASTA is applied at inference time and does not require changing any model parameters. Experiments demonstrate that PASTA can substantially enhance an LLM's ability to follow user instructions or integrate new knowledge from user inputs, leading to a significant performance improvement on a variety of tasks, e.g., an average accuracy improvement of 22% for LLAMA-7B. Our code is publicly available at https://github.com/QingruZhang/PASTA .
Tree Prompting: Efficient Task Adaptation without Fine-Tuning
Oct 21, 2023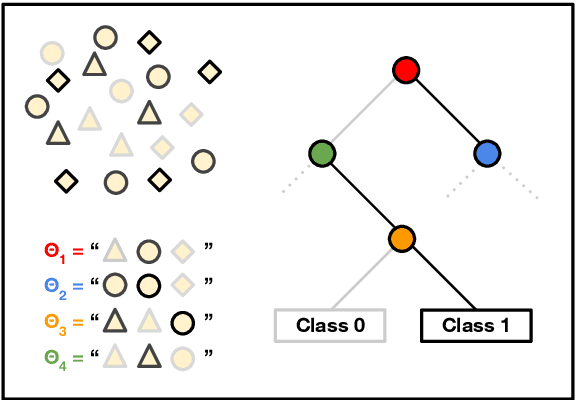
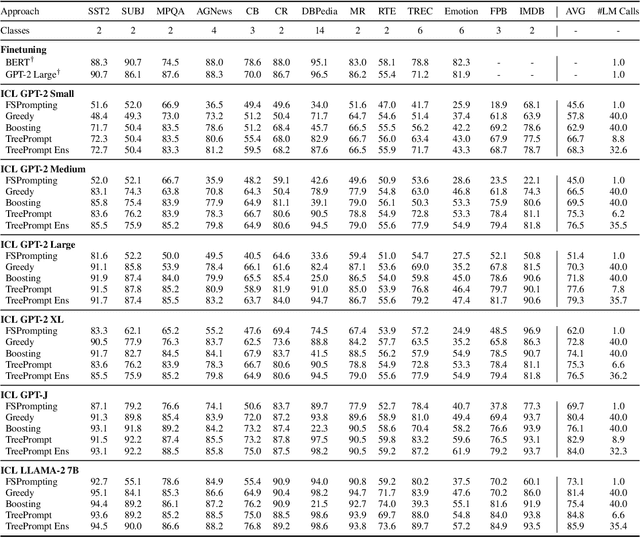


Prompting language models (LMs) is the main interface for applying them to new tasks. However, for smaller LMs, prompting provides low accuracy compared to gradient-based finetuning. Tree Prompting is an approach to prompting which builds a decision tree of prompts, linking multiple LM calls together to solve a task. At inference time, each call to the LM is determined by efficiently routing the outcome of the previous call using the tree. Experiments on classification datasets show that Tree Prompting improves accuracy over competing methods and is competitive with fine-tuning. We also show that variants of Tree Prompting allow inspection of a model's decision-making process.
Self-Verification Improves Few-Shot Clinical Information Extraction
May 30, 2023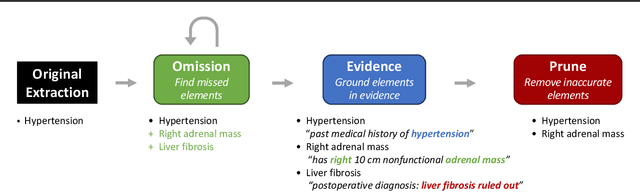



Extracting patient information from unstructured text is a critical task in health decision-support and clinical research. Large language models (LLMs) have shown the potential to accelerate clinical curation via few-shot in-context learning, in contrast to supervised learning which requires much more costly human annotations. However, despite drastic advances in modern LLMs such as GPT-4, they still struggle with issues regarding accuracy and interpretability, especially in mission-critical domains such as health. Here, we explore a general mitigation framework using self-verification, which leverages the LLM to provide provenance for its own extraction and check its own outputs. This is made possible by the asymmetry between verification and generation, where the latter is often much easier than the former. Experimental results show that our method consistently improves accuracy for various LLMs in standard clinical information extraction tasks. Additionally, self-verification yields interpretations in the form of a short text span corresponding to each output, which makes it very efficient for human experts to audit the results, paving the way towards trustworthy extraction of clinical information in resource-constrained scenarios. To facilitate future research in this direction, we release our code and prompts.
Explaining black box text modules in natural language with language models
May 17, 2023


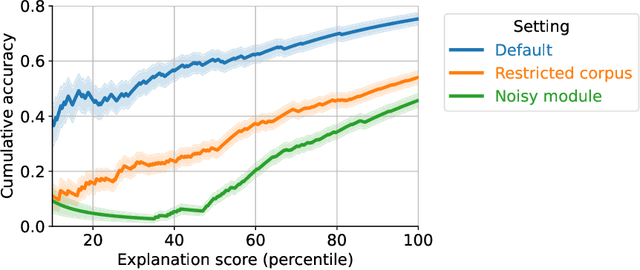
Large language models (LLMs) have demonstrated remarkable prediction performance for a growing array of tasks. However, their rapid proliferation and increasing opaqueness have created a growing need for interpretability. Here, we ask whether we can automatically obtain natural language explanations for black box text modules. A "text module" is any function that maps text to a scalar continuous value, such as a submodule within an LLM or a fitted model of a brain region. "Black box" indicates that we only have access to the module's inputs/outputs. We introduce Summarize and Score (SASC), a method that takes in a text module and returns a natural language explanation of the module's selectivity along with a score for how reliable the explanation is. We study SASC in 3 contexts. First, we evaluate SASC on synthetic modules and find that it often recovers ground truth explanations. Second, we use SASC to explain modules found within a pre-trained BERT model, enabling inspection of the model's internals. Finally, we show that SASC can generate explanations for the response of individual fMRI voxels to language stimuli, with potential applications to fine-grained brain mapping. All code for using SASC and reproducing results is made available on Github.
Explaining Patterns in Data with Language Models via Interpretable Autoprompting
Oct 04, 2022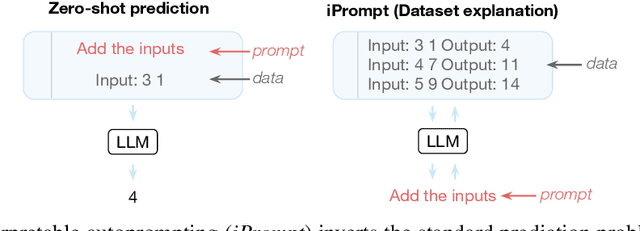
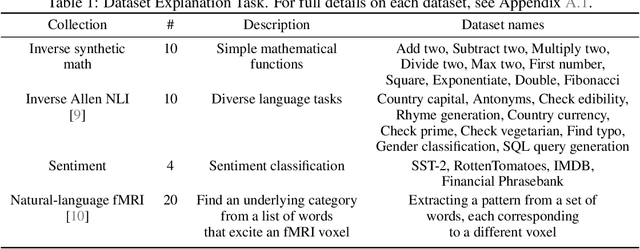
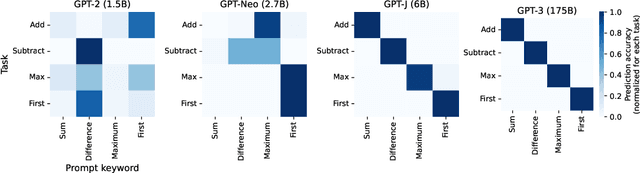

Large language models (LLMs) have displayed an impressive ability to harness natural language to perform complex tasks. In this work, we explore whether we can leverage this learned ability to find and explain patterns in data. Specifically, given a pre-trained LLM and data examples, we introduce interpretable autoprompting (iPrompt), an algorithm that generates a natural-language string explaining the data. iPrompt iteratively alternates between generating explanations with an LLM and reranking them based on their performance when used as a prompt. Experiments on a wide range of datasets, from synthetic mathematics to natural-language understanding, show that iPrompt can yield meaningful insights by accurately finding groundtruth dataset descriptions. Moreover, the prompts produced by iPrompt are simultaneously human-interpretable and highly effective for generalization: on real-world sentiment classification datasets, iPrompt produces prompts that match or even improve upon human-written prompts for GPT-3. Finally, experiments with an fMRI dataset show the potential for iPrompt to aid in scientific discovery. All code for using the methods and data here is made available on Github.
Emb-GAM: an Interpretable and Efficient Predictor using Pre-trained Language Models
Sep 23, 2022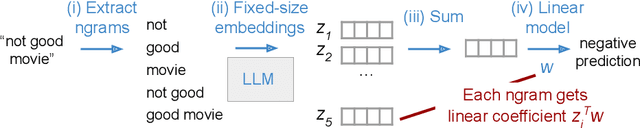

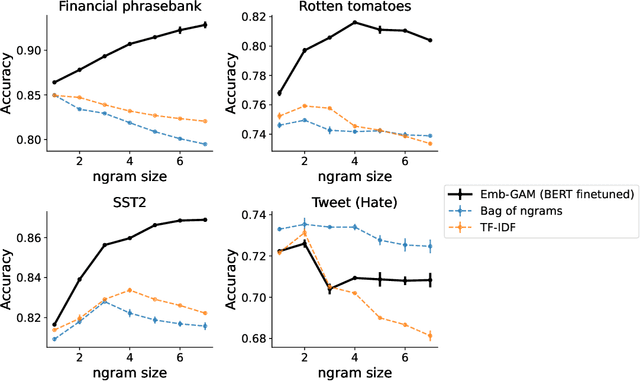

Deep learning models have achieved impressive prediction performance but often sacrifice interpretability, a critical consideration in high-stakes domains such as healthcare or policymaking. In contrast, generalized additive models (GAMs) can maintain interpretability but often suffer from poor prediction performance due to their inability to effectively capture feature interactions. In this work, we aim to bridge this gap by using pre-trained neural language models to extract embeddings for each input before learning a linear model in the embedding space. The final model (which we call Emb-GAM) is a transparent, linear function of its input features and feature interactions. Leveraging the language model allows Emb-GAM to learn far fewer linear coefficients, model larger interactions, and generalize well to novel inputs (e.g. unseen ngrams in text). Across a variety of natural-language-processing datasets, Emb-GAM achieves strong prediction performance without sacrificing interpretability. All code is made available on Github.