 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJyoti Aneja
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024
We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
Textbooks Are All You Need
Jun 20, 2023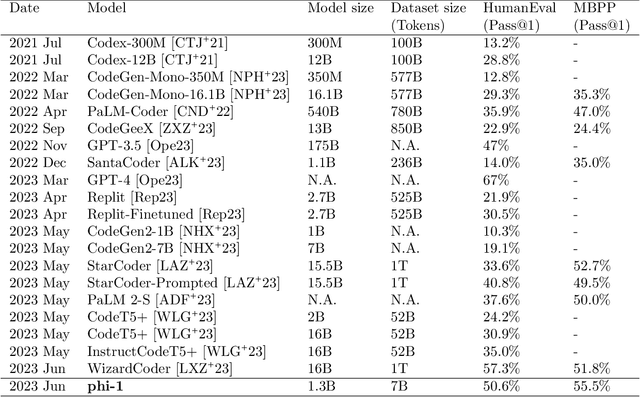
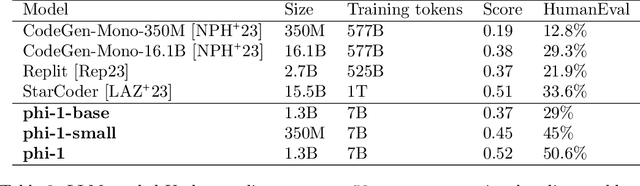
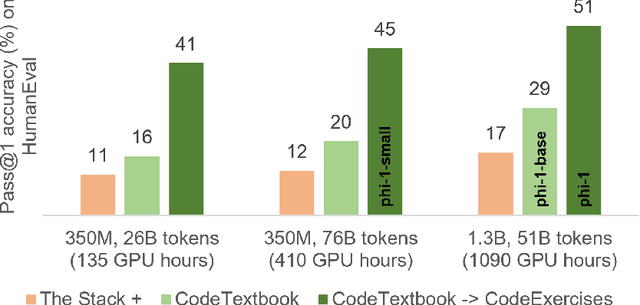
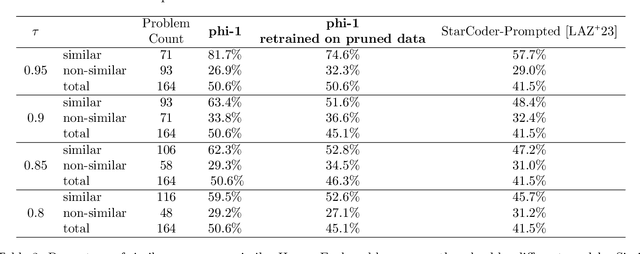
We introduce phi-1, a new large language model for code, with significantly smaller size than competing models: phi-1 is a Transformer-based model with 1.3B parameters, trained for 4 days on 8 A100s, using a selection of ``textbook quality" data from the web (6B tokens) and synthetically generated textbooks and exercises with GPT-3.5 (1B tokens). Despite this small scale, phi-1 attains pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP. It also displays surprising emergent properties compared to phi-1-base, our model before our finetuning stage on a dataset of coding exercises, and phi-1-small, a smaller model with 350M parameters trained with the same pipeline as phi-1 that still achieves 45% on HumanEval.
Explaining Patterns in Data with Language Models via Interpretable Autoprompting
Oct 04, 2022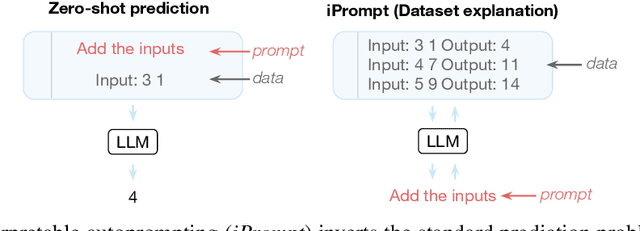
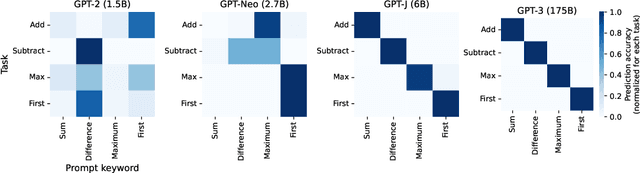

Large language models (LLMs) have displayed an impressive ability to harness natural language to perform complex tasks. In this work, we explore whether we can leverage this learned ability to find and explain patterns in data. Specifically, given a pre-trained LLM and data examples, we introduce interpretable autoprompting (iPrompt), an algorithm that generates a natural-language string explaining the data. iPrompt iteratively alternates between generating explanations with an LLM and reranking them based on their performance when used as a prompt. Experiments on a wide range of datasets, from synthetic mathematics to natural-language understanding, show that iPrompt can yield meaningful insights by accurately finding groundtruth dataset descriptions. Moreover, the prompts produced by iPrompt are simultaneously human-interpretable and highly effective for generalization: on real-world sentiment classification datasets, iPrompt produces prompts that match or even improve upon human-written prompts for GPT-3. Finally, experiments with an fMRI dataset show the potential for iPrompt to aid in scientific discovery. All code for using the methods and data here is made available on Github.
ELEVATER: A Benchmark and Toolkit for Evaluating Language-Augmented Visual Models
Apr 20, 2022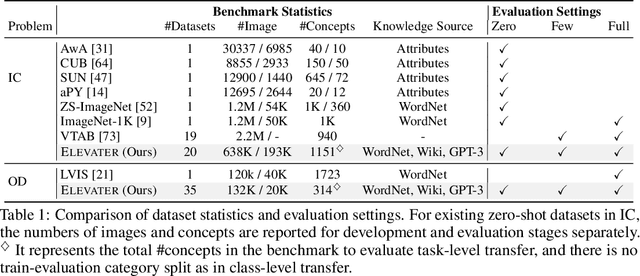

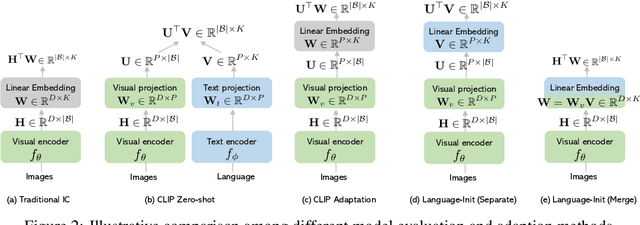
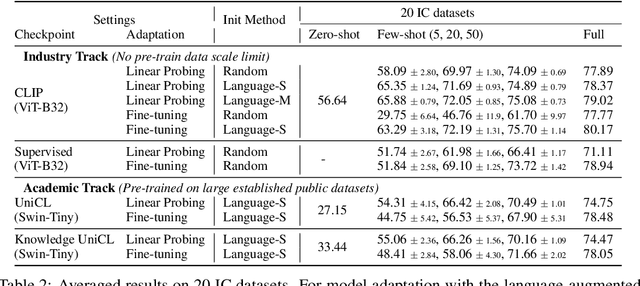
Learning visual representations from natural language supervision has recently shown great promise in a number of pioneering works. In general, these language-augmented visual models demonstrate strong transferability to a variety of datasets/tasks. However, it remains a challenge to evaluate the transferablity of these foundation models due to the lack of easy-to-use toolkits for fair benchmarking. To tackle this, we build ELEVATER (Evaluation of Language-augmented Visual Task-level Transfer), the first benchmark to compare and evaluate pre-trained language-augmented visual models. Several highlights include: (i) Datasets. As downstream evaluation suites, it consists of 20 image classification datasets and 35 object detection datasets, each of which is augmented with external knowledge. (ii) Toolkit. An automatic hyper-parameter tuning toolkit is developed to ensure the fairness in model adaption. To leverage the full power of language-augmented visual models, novel language-aware initialization methods are proposed to significantly improve the adaption performance. (iii) Metrics. A variety of evaluation metrics are used, including sample-efficiency (zero-shot and few-shot) and parameter-efficiency (linear probing and full model fine-tuning). We will release our toolkit and evaluation platforms for the research community.
NCP-VAE: Variational Autoencoders with Noise Contrastive Priors
Oct 06, 2020



Variational autoencoders (VAEs) are one of the powerful likelihood-based generative models with applications in various domains. However, they struggle to generate high-quality images, especially when samples are obtained from the prior without any tempering. One explanation for VAEs' poor generative quality is the prior hole problem: the prior distribution fails to match the aggregate approximate posterior. Due to this mismatch, there exist areas in the latent space with high density under the prior that do not correspond to any encoded image. Samples from those areas are decoded to corrupted images. To tackle this issue, we propose an energy-based prior defined by the product of a base prior distribution and a reweighting factor, designed to bring the base closer to the aggregate posterior. We train the reweighting factor by noise contrastive estimation, and we generalize it to hierarchical VAEs with many latent variable groups. Our experiments confirm that the proposed noise contrastive priors improve the generative performance of state-of-the-art VAEs by a large margin on the MNIST, CIFAR-10, CelebA 64, and CelebA HQ 256 datasets.
Sequential Latent Spaces for Modeling the Intention During Diverse Image Captioning
Aug 22, 2019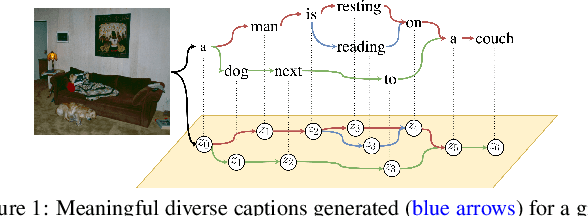
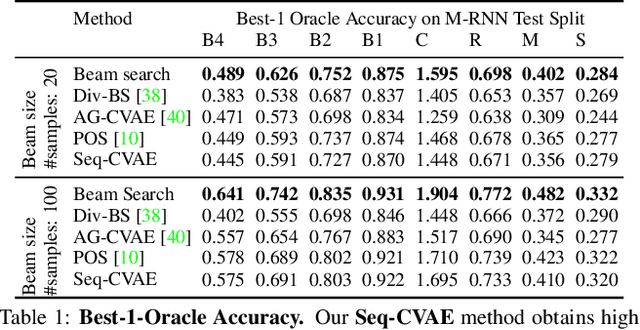
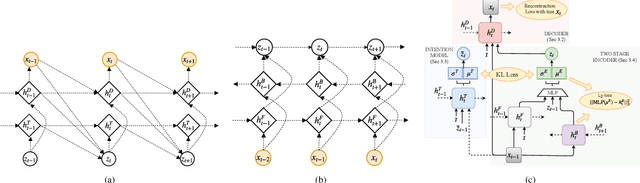
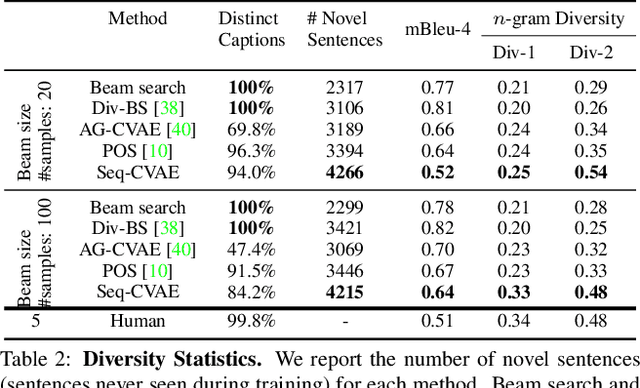
Diverse and accurate vision+language modeling is an important goal to retain creative freedom and maintain user engagement. However, adequately capturing the intricacies of diversity in language models is challenging. Recent works commonly resort to latent variable models augmented with more or less supervision from object detectors or part-of-speech tags. Common to all those methods is the fact that the latent variable either only initializes the sentence generation process or is identical across the steps of generation. Both methods offer no fine-grained control. To address this concern, we propose Seq-CVAE which learns a latent space for every word position. We encourage this temporal latent space to capture the 'intention' about how to complete the sentence by mimicking a representation which summarizes the future. We illustrate the efficacy of the proposed approach to anticipate the sentence continuation on the challenging MSCOCO dataset, significantly improving diversity metrics compared to baselines while performing on par w.r.t sentence quality.
Diverse and Controllable Image Captioning with Part-of-Speech Guidance
May 31, 2018



Automatically describing an image is an important capability for virtual assistants. Significant progress has been achieved in recent years on this task of image captioning. However, classical prediction techniques based on maximum likelihood trained LSTM nets don't embrace the inherent ambiguity of image captioning. To address this concern, recent variational auto-encoder and generative adversarial network based methods produce a set of captions by sampling from an abstract latent space. But, this latent space has limited interpretability and therefore, a control mechanism for captioning remains an open problem. This paper proposes a captioning technique conditioned on part-of-speech. Our method provides human interpretable control in form of part-of-speech. Importantly, part-of-speech is a language prior, and conditioning on it provides: (i) more diversity as evaluated by counting n-grams and the novel sentences generated, (ii) achieves high accuracy for the diverse captions on standard captioning metrics.
Convolutional Image Captioning
Nov 24, 2017



Image captioning is an important but challenging task, applicable to virtual assistants, editing tools, image indexing, and support of the disabled. Its challenges are due to the variability and ambiguity of possible image descriptions. In recent years significant progress has been made in image captioning, using Recurrent Neural Networks powered by long-short-term-memory (LSTM) units. Despite mitigating the vanishing gradient problem, and despite their compelling ability to memorize dependencies, LSTM units are complex and inherently sequential across time. To address this issue, recent work has shown benefits of convolutional networks for machine translation and conditional image generation. Inspired by their success, in this paper, we develop a convolutional image captioning technique. We demonstrate its efficacy on the challenging MSCOCO dataset and demonstrate performance on par with the baseline, while having a faster training time per number of parameters. We also perform a detailed analysis, providing compelling reasons in favor of convolutional language generation approaches.