 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyril Zhang
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024
We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
Can large language models explore in-context?
Mar 22, 2024We investigate the extent to which contemporary Large Language Models (LLMs) can engage in exploration, a core capability in reinforcement learning and decision making. We focus on native performance of existing LLMs, without training interventions. We deploy LLMs as agents in simple multi-armed bandit environments, specifying the environment description and interaction history entirely in-context, i.e., within the LLM prompt. We experiment with GPT-3.5, GPT-4, and Llama2, using a variety of prompt designs, and find that the models do not robustly engage in exploration without substantial interventions: i) Across all of our experiments, only one configuration resulted in satisfactory exploratory behavior: GPT-4 with chain-of-thought reasoning and an externally summarized interaction history, presented as sufficient statistics; ii) All other configurations did not result in robust exploratory behavior, including those with chain-of-thought reasoning but unsummarized history. Although these findings can be interpreted positively, they suggest that external summarization -- which may not be possible in more complex settings -- is important for obtaining desirable behavior from LLM agents. We conclude that non-trivial algorithmic interventions, such as fine-tuning or dataset curation, may be required to empower LLM-based decision making agents in complex settings.
Butterfly Effects of SGD Noise: Error Amplification in Behavior Cloning and Autoregression
Oct 17, 2023This work studies training instabilities of behavior cloning with deep neural networks. We observe that minibatch SGD updates to the policy network during training result in sharp oscillations in long-horizon rewards, despite negligibly affecting the behavior cloning loss. We empirically disentangle the statistical and computational causes of these oscillations, and find them to stem from the chaotic propagation of minibatch SGD noise through unstable closed-loop dynamics. While SGD noise is benign in the single-step action prediction objective, it results in catastrophic error accumulation over long horizons, an effect we term gradient variance amplification (GVA). We show that many standard mitigation techniques do not alleviate GVA, but find an exponential moving average (EMA) of iterates to be surprisingly effective at doing so. We illustrate the generality of this phenomenon by showing the existence of GVA and its amelioration by EMA in both continuous control and autoregressive language generation. Finally, we provide theoretical vignettes that highlight the benefits of EMA in alleviating GVA and shed light on the extent to which classical convex models can help in understanding the benefits of iterate averaging in deep learning.
Pareto Frontiers in Neural Feature Learning: Data, Compute, Width, and Luck
Sep 07, 2023

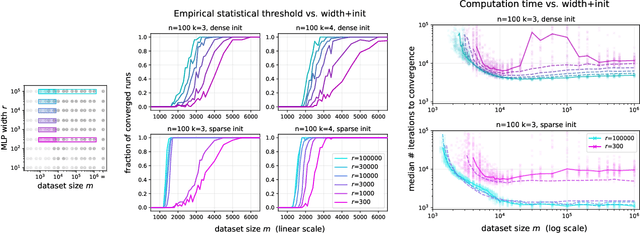
This work investigates the nuanced algorithm design choices for deep learning in the presence of computational-statistical gaps. We begin by considering offline sparse parity learning, a supervised classification problem which admits a statistical query lower bound for gradient-based training of a multilayer perceptron. This lower bound can be interpreted as a multi-resource tradeoff frontier: successful learning can only occur if one is sufficiently rich (large model), knowledgeable (large dataset), patient (many training iterations), or lucky (many random guesses). We show, theoretically and experimentally, that sparse initialization and increasing network width yield significant improvements in sample efficiency in this setting. Here, width plays the role of parallel search: it amplifies the probability of finding "lottery ticket" neurons, which learn sparse features more sample-efficiently. Finally, we show that the synthetic sparse parity task can be useful as a proxy for real problems requiring axis-aligned feature learning. We demonstrate improved sample efficiency on tabular classification benchmarks by using wide, sparsely-initialized MLP models; these networks sometimes outperform tuned random forests.
Exposing Attention Glitches with Flip-Flop Language Modeling
Jun 01, 2023
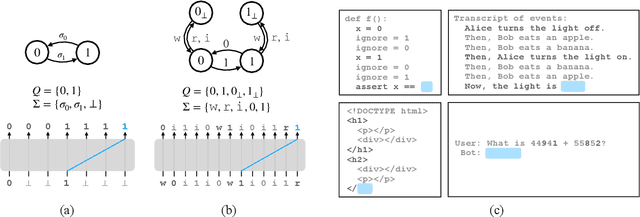

Why do large language models sometimes output factual inaccuracies and exhibit erroneous reasoning? The brittleness of these models, particularly when executing long chains of reasoning, currently seems to be an inevitable price to pay for their advanced capabilities of coherently synthesizing knowledge, pragmatics, and abstract thought. Towards making sense of this fundamentally unsolved problem, this work identifies and analyzes the phenomenon of attention glitches, in which the Transformer architecture's inductive biases intermittently fail to capture robust reasoning. To isolate the issue, we introduce flip-flop language modeling (FFLM), a parametric family of synthetic benchmarks designed to probe the extrapolative behavior of neural language models. This simple generative task requires a model to copy binary symbols over long-range dependencies, ignoring the tokens in between. We find that Transformer FFLMs suffer from a long tail of sporadic reasoning errors, some of which we can eliminate using various regularization techniques. Our preliminary mechanistic analyses show why the remaining errors may be very difficult to diagnose and resolve. We hypothesize that attention glitches account for (some of) the closed-domain hallucinations in natural LLMs.
Learning Hidden Markov Models Using Conditional Samples
Feb 28, 2023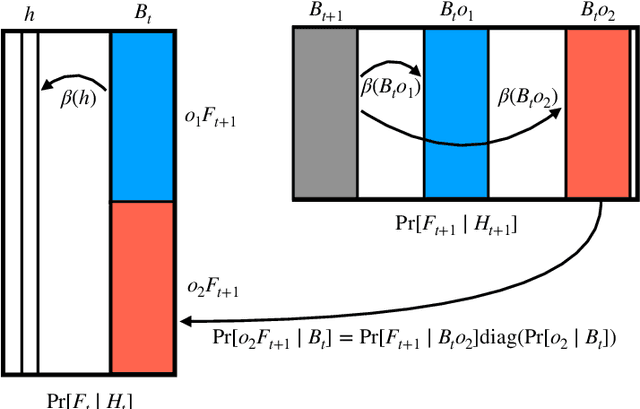
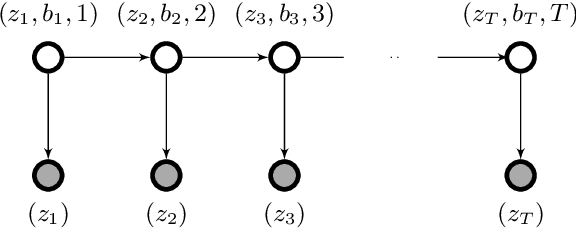
This paper is concerned with the computational complexity of learning the Hidden Markov Model (HMM). Although HMMs are some of the most widely used tools in sequential and time series modeling, they are cryptographically hard to learn in the standard setting where one has access to i.i.d. samples of observation sequences. In this paper, we depart from this setup and consider an interactive access model, in which the algorithm can query for samples from the conditional distributions of the HMMs. We show that interactive access to the HMM enables computationally efficient learning algorithms, thereby bypassing cryptographic hardness. Specifically, we obtain efficient algorithms for learning HMMs in two settings: (a) An easier setting where we have query access to the exact conditional probabilities. Here our algorithm runs in polynomial time and makes polynomially many queries to approximate any HMM in total variation distance. (b) A harder setting where we can only obtain samples from the conditional distributions. Here the performance of the algorithm depends on a new parameter, called the fidelity of the HMM. We show that this captures cryptographically hard instances and previously known positive results. We also show that these results extend to a broader class of distributions with latent low rank structure. Our algorithms can be viewed as generalizations and robustifications of Angluin's $L^*$ algorithm for learning deterministic finite automata from membership queries.
Neural Active Learning on Heteroskedastic Distributions
Nov 02, 2022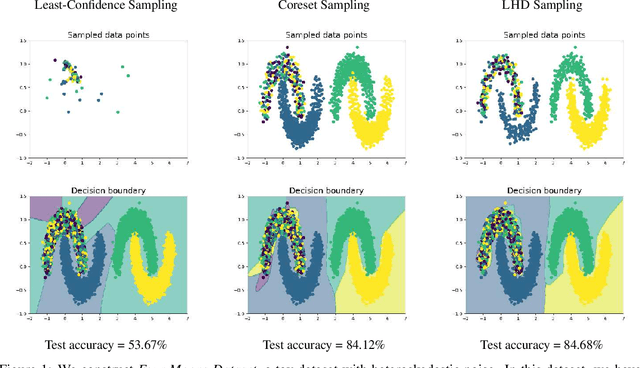
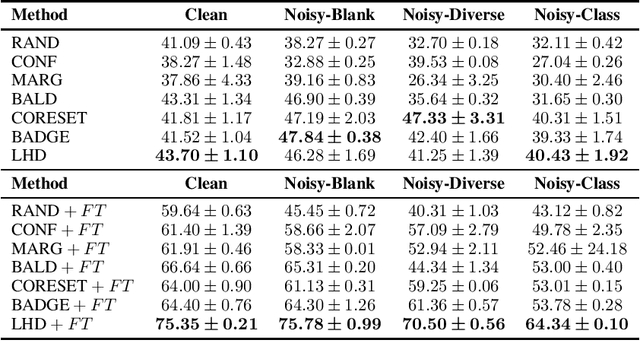
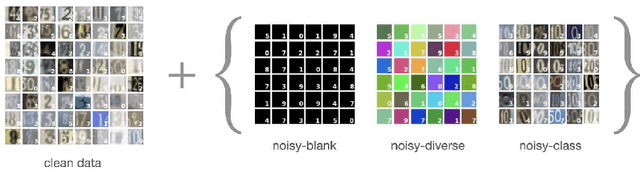

Models that can actively seek out the best quality training data hold the promise of more accurate, adaptable, and efficient machine learning. State-of-the-art active learning techniques tend to prefer examples that are the most difficult to classify. While this works well on homogeneous datasets, we find that it can lead to catastrophic failures when performed on multiple distributions with different degrees of label noise or heteroskedasticity. These active learning algorithms strongly prefer to draw from the distribution with more noise, even if their examples have no informative structure (such as solid color images with random labels). To this end, we demonstrate the catastrophic failure of these active learning algorithms on heteroskedastic distributions and propose a fine-tuning-based approach to mitigate these failures. Further, we propose a new algorithm that incorporates a model difference scoring function for each data point to filter out the noisy examples and sample clean examples that maximize accuracy, outperforming the existing active learning techniques on the heteroskedastic datasets. We hope these observations and techniques are immediately helpful to practitioners and can help to challenge common assumptions in the design of active learning algorithms.
Transformers Learn Shortcuts to Automata
Oct 19, 2022Algorithmic reasoning requires capabilities which are most naturally understood through recurrent models of computation, like the Turing machine. However, Transformer models, while lacking recurrence, are able to perform such reasoning using far fewer layers than the number of reasoning steps. This raises the question: what solutions are these shallow and non-recurrent models finding? We investigate this question in the setting of learning automata, discrete dynamical systems naturally suited to recurrent modeling and expressing algorithmic tasks. Our theoretical results completely characterize shortcut solutions, whereby a shallow Transformer with only $o(T)$ layers can exactly replicate the computation of an automaton on an input sequence of length $T$. By representing automata using the algebraic structure of their underlying transformation semigroups, we obtain $O(\log T)$-depth simulators for all automata and $O(1)$-depth simulators for all automata whose associated groups are solvable. Empirically, we perform synthetic experiments by training Transformers to simulate a wide variety of automata, and show that shortcut solutions can be learned via standard training. We further investigate the brittleness of these solutions and propose potential mitigations.
Recurrent Convolutional Neural Networks Learn Succinct Learning Algorithms
Sep 01, 2022
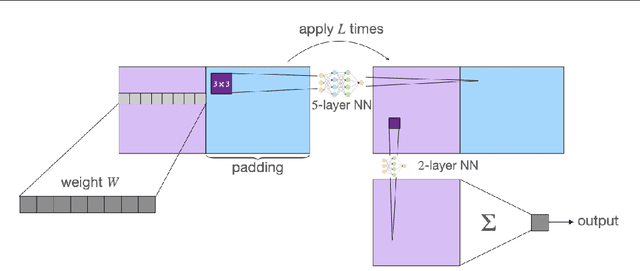
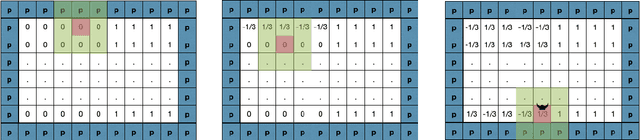
Neural Networks (NNs) struggle to efficiently learn certain problems, such as parity problems, even when there are simple learning algorithms for those problems. Can NNs discover learning algorithms on their own? We exhibit a NN architecture that, in polynomial time, learns as well as any efficient learning algorithm describable by a constant-sized learning algorithm. For example, on parity problems, the NN learns as well as row reduction, an efficient algorithm that can be succinctly described. Our architecture combines both recurrent weight-sharing between layers and convolutional weight-sharing to reduce the number of parameters down to a constant, even though the network itself may have trillions of nodes. While in practice the constants in our analysis are too large to be directly meaningful, our work suggests that the synergy of Recurrent and Convolutional NNs (RCNNs) may be more powerful than either alone.
Hidden Progress in Deep Learning: SGD Learns Parities Near the Computational Limit
Jul 18, 2022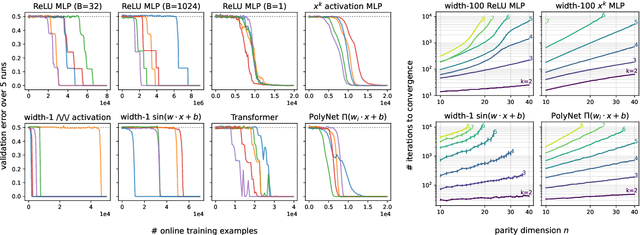
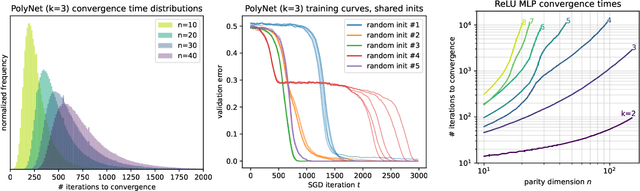

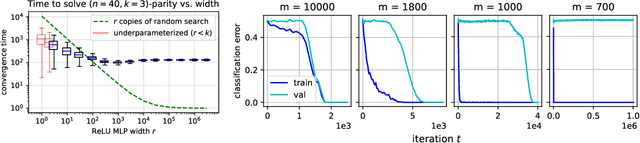
There is mounting empirical evidence of emergent phenomena in the capabilities of deep learning methods as we scale up datasets, model sizes, and training times. While there are some accounts of how these resources modulate statistical capacity, far less is known about their effect on the computational problem of model training. This work conducts such an exploration through the lens of learning $k$-sparse parities of $n$ bits, a canonical family of problems which pose theoretical computational barriers. In this setting, we find that neural networks exhibit surprising phase transitions when scaling up dataset size and running time. In particular, we demonstrate empirically that with standard training, a variety of architectures learn sparse parities with $n^{O(k)}$ examples, with loss (and error) curves abruptly dropping after $n^{O(k)}$ iterations. These positive results nearly match known SQ lower bounds, even without an explicit sparsity-promoting prior. We elucidate the mechanisms of these phenomena with a theoretical analysis: we find that the phase transition in performance is not due to SGD "stumbling in the dark" until it finds the hidden set of features (a natural algorithm which also runs in $n^{O(k)}$ time); instead, we show that SGD gradually amplifies a Fourier gap in the population gradient.