 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuanzhi Li
AgentKit: Flow Engineering with Graphs, not Coding
Apr 17, 2024
We propose an intuitive LLM prompting framework (AgentKit) for multifunctional agents. AgentKit offers a unified framework for explicitly constructing a complex "thought process" from simple natural language prompts. The basic building block in AgentKit is a node, containing a natural language prompt for a specific subtask. The user then puts together chains of nodes, like stacking LEGO pieces. The chains of nodes can be designed to explicitly enforce a naturally structured "thought process". For example, for the task of writing a paper, one may start with the thought process of 1) identify a core message, 2) identify prior research gaps, etc. The nodes in AgentKit can be designed and combined in different ways to implement multiple advanced capabilities including on-the-fly hierarchical planning, reflection, and learning from interactions. In addition, due to the modular nature and the intuitive design to simulate explicit human thought process, a basic agent could be implemented as simple as a list of prompts for the subtasks and therefore could be designed and tuned by someone without any programming experience. Quantitatively, we show that agents designed through AgentKit achieve SOTA performance on WebShop and Crafter. These advances underscore AgentKit's potential in making LLM agents effective and accessible for a wider range of applications. https://github.com/holmeswww/AgentKit
VisualWebBench: How Far Have Multimodal LLMs Evolved in Web Page Understanding and Grounding?
Apr 09, 2024Multimodal Large Language models (MLLMs) have shown promise in web-related tasks, but evaluating their performance in the web domain remains a challenge due to the lack of comprehensive benchmarks. Existing benchmarks are either designed for general multimodal tasks, failing to capture the unique characteristics of web pages, or focus on end-to-end web agent tasks, unable to measure fine-grained abilities such as OCR, understanding, and grounding. In this paper, we introduce \bench{}, a multimodal benchmark designed to assess the capabilities of MLLMs across a variety of web tasks. \bench{} consists of seven tasks, and comprises 1.5K human-curated instances from 139 real websites, covering 87 sub-domains. We evaluate 14 open-source MLLMs, Gemini Pro, Claude-3 series, and GPT-4V(ision) on \bench{}, revealing significant challenges and performance gaps. Further analysis highlights the limitations of current MLLMs, including inadequate grounding in text-rich environments and subpar performance with low-resolution image inputs. We believe \bench{} will serve as a valuable resource for the research community and contribute to the creation of more powerful and versatile MLLMs for web-related applications.
Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws
Apr 08, 2024Scaling laws describe the relationship between the size of language models and their capabilities. Unlike prior studies that evaluate a model's capability via loss or benchmarks, we estimate the number of knowledge bits a model stores. We focus on factual knowledge represented as tuples, such as (USA, capital, Washington D.C.) from a Wikipedia page. Through multiple controlled datasets, we establish that language models can and only can store 2 bits of knowledge per parameter, even when quantized to int8, and such knowledge can be flexibly extracted for downstream applications. Consequently, a 7B model can store 14B bits of knowledge, surpassing the English Wikipedia and textbooks combined based on our estimation. More broadly, we present 12 results on how (1) training duration, (2) model architecture, (3) quantization, (4) sparsity constraints such as MoE, and (5) data signal-to-noise ratio affect a model's knowledge storage capacity. Notable insights include: * The GPT-2 architecture, with rotary embedding, matches or even surpasses LLaMA/Mistral architectures in knowledge storage, particularly over shorter training durations. This arises because LLaMA/Mistral uses GatedMLP, which is less stable and harder to train. * Prepending training data with domain names (e.g., wikipedia.org) significantly increases a model's knowledge capacity. Language models can autonomously identify and prioritize domains rich in knowledge, optimizing their storage capacity.
Role of Locality and Weight Sharing in Image-Based Tasks: A Sample Complexity Separation between CNNs, LCNs, and FCNs
Mar 23, 2024Vision tasks are characterized by the properties of locality and translation invariance. The superior performance of convolutional neural networks (CNNs) on these tasks is widely attributed to the inductive bias of locality and weight sharing baked into their architecture. Existing attempts to quantify the statistical benefits of these biases in CNNs over locally connected convolutional neural networks (LCNs) and fully connected neural networks (FCNs) fall into one of the following categories: either they disregard the optimizer and only provide uniform convergence upper bounds with no separating lower bounds, or they consider simplistic tasks that do not truly mirror the locality and translation invariance as found in real-world vision tasks. To address these deficiencies, we introduce the Dynamic Signal Distribution (DSD) classification task that models an image as consisting of $k$ patches, each of dimension $d$, and the label is determined by a $d$-sparse signal vector that can freely appear in any one of the $k$ patches. On this task, for any orthogonally equivariant algorithm like gradient descent, we prove that CNNs require $\tilde{O}(k+d)$ samples, whereas LCNs require $\Omega(kd)$ samples, establishing the statistical advantages of weight sharing in translation invariant tasks. Furthermore, LCNs need $\tilde{O}(k(k+d))$ samples, compared to $\Omega(k^2d)$ samples for FCNs, showcasing the benefits of locality in local tasks. Additionally, we develop information theoretic tools for analyzing randomized algorithms, which may be of interest for statistical research.
Revisiting Disentanglement in Downstream Tasks: A Study on Its Necessity for Abstract Visual Reasoning
Mar 01, 2024
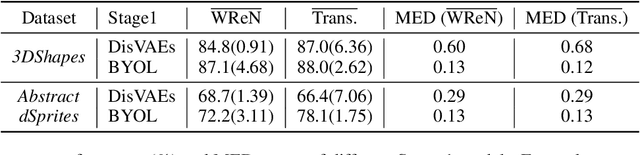


In representation learning, a disentangled representation is highly desirable as it encodes generative factors of data in a separable and compact pattern. Researchers have advocated leveraging disentangled representations to complete downstream tasks with encouraging empirical evidence. This paper further investigates the necessity of disentangled representation in downstream applications. Specifically, we show that dimension-wise disentangled representations are unnecessary on a fundamental downstream task, abstract visual reasoning. We provide extensive empirical evidence against the necessity of disentanglement, covering multiple datasets, representation learning methods, and downstream network architectures. Furthermore, our findings suggest that the informativeness of representations is a better indicator of downstream performance than disentanglement. Finally, the positive correlation between informativeness and disentanglement explains the claimed usefulness of disentangled representations in previous works. The source code is available at https://github.com/Richard-coder-Nai/disentanglement-lib-necessity.git.
Provably learning a multi-head attention layer
Feb 06, 2024The multi-head attention layer is one of the key components of the transformer architecture that sets it apart from traditional feed-forward models. Given a sequence length $k$, attention matrices $\mathbf{\Theta}_1,\ldots,\mathbf{\Theta}_m\in\mathbb{R}^{d\times d}$, and projection matrices $\mathbf{W}_1,\ldots,\mathbf{W}_m\in\mathbb{R}^{d\times d}$, the corresponding multi-head attention layer $F: \mathbb{R}^{k\times d}\to \mathbb{R}^{k\times d}$ transforms length-$k$ sequences of $d$-dimensional tokens $\mathbf{X}\in\mathbb{R}^{k\times d}$ via $F(\mathbf{X}) \triangleq \sum^m_{i=1} \mathrm{softmax}(\mathbf{X}\mathbf{\Theta}_i\mathbf{X}^\top)\mathbf{X}\mathbf{W}_i$. In this work, we initiate the study of provably learning a multi-head attention layer from random examples and give the first nontrivial upper and lower bounds for this problem: - Provided $\{\mathbf{W}_i, \mathbf{\Theta}_i\}$ satisfy certain non-degeneracy conditions, we give a $(dk)^{O(m^3)}$-time algorithm that learns $F$ to small error given random labeled examples drawn uniformly from $\{\pm 1\}^{k\times d}$. - We prove computational lower bounds showing that in the worst case, exponential dependence on $m$ is unavoidable. We focus on Boolean $\mathbf{X}$ to mimic the discrete nature of tokens in large language models, though our techniques naturally extend to standard continuous settings, e.g. Gaussian. Our algorithm, which is centered around using examples to sculpt a convex body containing the unknown parameters, is a significant departure from existing provable algorithms for learning feedforward networks, which predominantly exploit algebraic and rotation invariance properties of the Gaussian distribution. In contrast, our analysis is more flexible as it primarily relies on various upper and lower tail bounds for the input distribution and "slices" thereof.
TinyGSM: achieving >80% on GSM8k with small language models
Dec 14, 2023Small-scale models offer various computational advantages, and yet to which extent size is critical for problem-solving abilities remains an open question. Specifically for solving grade school math, the smallest model size so far required to break the 80\% barrier on the GSM8K benchmark remains to be 34B. Our work studies how high-quality datasets may be the key for small language models to acquire mathematical reasoning. We introduce \texttt{TinyGSM}, a synthetic dataset of 12.3M grade school math problems paired with Python solutions, generated fully by GPT-3.5. After finetuning on \texttt{TinyGSM}, we find that a duo of a 1.3B generation model and a 1.3B verifier model can achieve 81.5\% accuracy, outperforming existing models that are orders of magnitude larger. This also rivals the performance of the GPT-3.5 ``teacher'' model (77.4\%), from which our model's training data is generated. Our approach is simple and has two key components: 1) the high-quality dataset \texttt{TinyGSM}, 2) the use of a verifier, which selects the final outputs from multiple candidate generations.
Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine
Nov 28, 2023Generalist foundation models such as GPT-4 have displayed surprising capabilities in a wide variety of domains and tasks. Yet, there is a prevalent assumption that they cannot match specialist capabilities of fine-tuned models. For example, most explorations to date on medical competency benchmarks have leveraged domain-specific training, as exemplified by efforts on BioGPT and Med-PaLM. We build on a prior study of GPT-4's capabilities on medical challenge benchmarks in the absence of special training. Rather than using simple prompting to highlight the model's out-of-the-box capabilities, we perform a systematic exploration of prompt engineering. We find that prompting innovation can unlock deeper specialist capabilities and show that GPT-4 easily tops prior leading results for medical benchmarks. The prompting methods we explore are general purpose, and make no specific use of domain expertise, removing the need for expert-curated content. Our experimental design carefully controls for overfitting during the prompt engineering process. We introduce Medprompt, based on a composition of several prompting strategies. With Medprompt, GPT-4 achieves state-of-the-art results on all nine of the benchmark datasets in the MultiMedQA suite. The method outperforms leading specialist models such as Med-PaLM 2 by a significant margin with an order of magnitude fewer calls to the model. Steering GPT-4 with Medprompt achieves a 27% reduction in error rate on the MedQA dataset over the best methods to date achieved with specialist models and surpasses a score of 90% for the first time. Beyond medical problems, we show the power of Medprompt to generalize to other domains and provide evidence for the broad applicability of the approach via studies of the strategy on exams in electrical engineering, machine learning, philosophy, accounting, law, nursing, and clinical psychology.
Positional Description Matters for Transformers Arithmetic
Nov 22, 2023Transformers, central to the successes in modern Natural Language Processing, often falter on arithmetic tasks despite their vast capabilities --which paradoxically include remarkable coding abilities. We observe that a crucial challenge is their naive reliance on positional information to solve arithmetic problems with a small number of digits, leading to poor performance on larger numbers. Herein, we delve deeper into the role of positional encoding, and propose several ways to fix the issue, either by modifying the positional encoding directly, or by modifying the representation of the arithmetic task to leverage standard positional encoding differently. We investigate the value of these modifications for three tasks: (i) classical multiplication, (ii) length extrapolation in addition, and (iii) addition in natural language context. For (i) we train a small model on a small dataset (100M parameters and 300k samples) with remarkable aptitude in (direct, no scratchpad) 15 digits multiplication and essentially perfect up to 12 digits, while usual training in this context would give a model failing at 4 digits multiplication. In the experiments on addition, we use a mere 120k samples to demonstrate: for (ii) extrapolation from 10 digits to testing on 12 digits numbers while usual training would have no extrapolation, and for (iii) almost perfect accuracy up to 5 digits while usual training would be correct only up to 3 digits (which is essentially memorization with a training set of 120k samples).
Simple Mechanisms for Representing, Indexing and Manipulating Concepts
Oct 18, 2023Deep networks typically learn concepts via classifiers, which involves setting up a model and training it via gradient descent to fit the concept-labeled data. We will argue instead that learning a concept could be done by looking at its moment statistics matrix to generate a concrete representation or signature of that concept. These signatures can be used to discover structure across the set of concepts and could recursively produce higher-level concepts by learning this structure from those signatures. When the concepts are `intersected', signatures of the concepts can be used to find a common theme across a number of related `intersected' concepts. This process could be used to keep a dictionary of concepts so that inputs could correctly identify and be routed to the set of concepts involved in the (latent) generation of the input.