 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNicolo Fusi
Tag-LLM: Repurposing General-Purpose LLMs for Specialized Domains
Feb 06, 2024
Large Language Models (LLMs) have demonstrated remarkable proficiency in understanding and generating natural language. However, their capabilities wane in highly specialized domains underrepresented in the pretraining corpus, such as physical and biomedical sciences. This work explores how to repurpose general LLMs into effective task solvers for specialized domains. We introduce a novel, model-agnostic framework for learning custom input tags, which are parameterized as continuous vectors appended to the LLM's embedding layer, to condition the LLM. We design two types of input tags: domain tags are used to delimit specialized representations (e.g., chemical formulas) and provide domain-relevant context; function tags are used to represent specific functions (e.g., predicting molecular properties) and compress function-solving instructions. We develop a three-stage protocol to learn these tags using auxiliary data and domain knowledge. By explicitly disentangling task domains from task functions, our method enables zero-shot generalization to unseen problems through diverse combinations of the input tags. It also boosts LLM's performance in various specialized domains, such as predicting protein or chemical properties and modeling drug-target interactions, outperforming expert models tailored to these tasks.
Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine
Nov 28, 2023Generalist foundation models such as GPT-4 have displayed surprising capabilities in a wide variety of domains and tasks. Yet, there is a prevalent assumption that they cannot match specialist capabilities of fine-tuned models. For example, most explorations to date on medical competency benchmarks have leveraged domain-specific training, as exemplified by efforts on BioGPT and Med-PaLM. We build on a prior study of GPT-4's capabilities on medical challenge benchmarks in the absence of special training. Rather than using simple prompting to highlight the model's out-of-the-box capabilities, we perform a systematic exploration of prompt engineering. We find that prompting innovation can unlock deeper specialist capabilities and show that GPT-4 easily tops prior leading results for medical benchmarks. The prompting methods we explore are general purpose, and make no specific use of domain expertise, removing the need for expert-curated content. Our experimental design carefully controls for overfitting during the prompt engineering process. We introduce Medprompt, based on a composition of several prompting strategies. With Medprompt, GPT-4 achieves state-of-the-art results on all nine of the benchmark datasets in the MultiMedQA suite. The method outperforms leading specialist models such as Med-PaLM 2 by a significant margin with an order of magnitude fewer calls to the model. Steering GPT-4 with Medprompt achieves a 27% reduction in error rate on the MedQA dataset over the best methods to date achieved with specialist models and surpasses a score of 90% for the first time. Beyond medical problems, we show the power of Medprompt to generalize to other domains and provide evidence for the broad applicability of the approach via studies of the strategy on exams in electrical engineering, machine learning, philosophy, accounting, law, nursing, and clinical psychology.
Interpretable Distribution Shift Detection using Optimal Transport
Aug 04, 2022
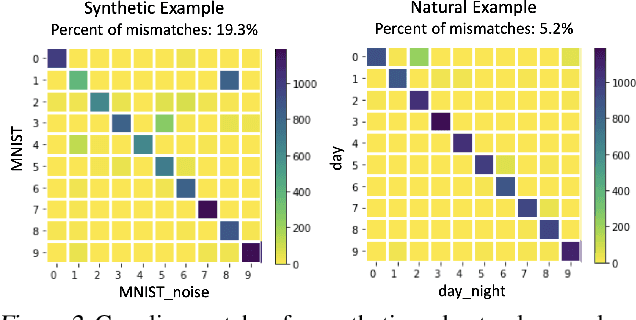


We propose a method to identify and characterize distribution shifts in classification datasets based on optimal transport. It allows the user to identify the extent to which each class is affected by the shift, and retrieves corresponding pairs of samples to provide insights on its nature. We illustrate its use on synthetic and natural shift examples. While the results we present are preliminary, we hope that this inspires future work on interpretable methods for analyzing distribution shifts.
Bayesian Optimization Over Iterative Learners with Structured Responses: A Budget-aware Planning Approach
Jun 25, 2022



The rising growth of deep neural networks (DNNs) and datasets in size motivates the need for efficient solutions for simultaneous model selection and training. Many methods for hyperparameter optimization (HPO) of iterative learners including DNNs attempt to solve this problem by querying and learning a response surface while searching for the optimum of that surface. However, many of these methods make myopic queries, do not consider prior knowledge about the response structure, and/or perform biased cost-aware search, all of which exacerbate identifying the best-performing model when a total cost budget is specified. This paper proposes a novel approach referred to as Budget-Aware Planning for Iterative Learners (BAPI) to solve HPO problems under a constrained cost budget. BAPI is an efficient non-myopic Bayesian optimization solution that accounts for the budget and leverages the prior knowledge about the objective function and cost function to select better configurations and to take more informed decisions during the evaluation (training). Experiments on diverse HPO benchmarks for iterative learners show that BAPI performs better than state-of-the-art baselines in most of the cases.
On Hard Episodes in Meta-Learning
Oct 21, 2021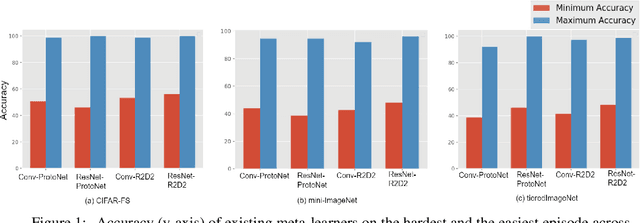
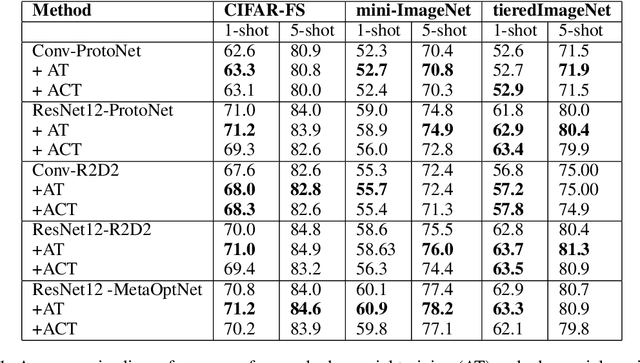

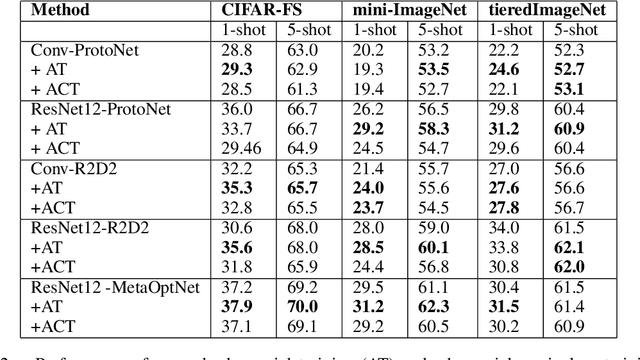
Existing meta-learners primarily focus on improving the average task accuracy across multiple episodes. Different episodes, however, may vary in hardness and quality leading to a wide gap in the meta-learner's performance across episodes. Understanding this issue is particularly critical in industrial few-shot settings, where there is limited control over test episodes as they are typically uploaded by end-users. In this paper, we empirically analyse the behaviour of meta-learners on episodes of varying hardness across three standard benchmark datasets: CIFAR-FS, mini-ImageNet, and tiered-ImageNet. Surprisingly, we observe a wide gap in accuracy of around 50% between the hardest and easiest episodes across all the standard benchmarks and meta-learners. We additionally investigate various properties of hard episodes and highlight their connection to catastrophic forgetting during meta-training. To address the issue of sub-par performance on hard episodes, we investigate and benchmark different meta-training strategies based on adversarial training and curriculum learning. We find that adversarial training strategies are much more powerful than curriculum learning in improving the prediction performance on hard episodes.
Rapid Model Architecture Adaption for Meta-Learning
Sep 10, 2021



Network Architecture Search (NAS) methods have recently gathered much attention. They design networks with better performance and use a much shorter search time compared to traditional manual tuning. Despite their efficiency in model deployments, most NAS algorithms target a single task on a fixed hardware system. However, real-life few-shot learning environments often cover a great number of tasks (T ) and deployments on a wide variety of hardware platforms (H ). The combinatorial search complexity T times H creates a fundamental search efficiency challenge if one naively applies existing NAS methods to these scenarios. To overcome this issue, we show, for the first time, how to rapidly adapt model architectures to new tasks in a many-task many-hardware few-shot learning setup by integrating Model Agnostic Meta Learning (MAML) into the NAS flow. The proposed NAS method (H-Meta-NAS) is hardware-aware and performs optimisation in the MAML framework. H-Meta-NAS shows a Pareto dominance compared to a variety of NAS and manual baselines in popular few-shot learning benchmarks with various hardware platforms and constraints. In particular, on the 5-way 1-shot Mini-ImageNet classification task, the proposed method outperforms the best manual baseline by a large margin (5.21% in accuracy) using 60% less computation.
HANT: Hardware-Aware Network Transformation
Jul 12, 2021



Given a trained network, how can we accelerate it to meet efficiency needs for deployment on particular hardware? The commonly used hardware-aware network compression techniques address this question with pruning, kernel fusion, quantization and lowering precision. However, these approaches do not change the underlying network operations. In this paper, we propose hardware-aware network transformation (HANT), which accelerates a network by replacing inefficient operations with more efficient alternatives using a neural architecture search like approach. HANT tackles the problem in two phase: In the first phase, a large number of alternative operations per every layer of the teacher model is trained using layer-wise feature map distillation. In the second phase, the combinatorial selection of efficient operations is relaxed to an integer optimization problem that can be solved in a few seconds. We extend HANT with kernel fusion and quantization to improve throughput even further. Our experimental results on accelerating the EfficientNet family show that HANT can accelerate them by up to 3.6x with <0.4% drop in the top-1 accuracy on the ImageNet dataset. When comparing the same latency level, HANT can accelerate EfficientNet-B4 to the same latency as EfficientNet-B1 while having 3% higher accuracy. We examine a large pool of operations, up to 197 per layer, and we provide insights into the selected operations and final architectures.
Model-specific Data Subsampling with Influence Functions
Oct 20, 2020
Model selection requires repeatedly evaluating models on a given dataset and measuring their relative performances. In modern applications of machine learning, the models being considered are increasingly more expensive to evaluate and the datasets of interest are increasing in size. As a result, the process of model selection is time-consuming and computationally inefficient. In this work, we develop a model-specific data subsampling strategy that improves over random sampling whenever training points have varying influence. Specifically, we leverage influence functions to guide our selection strategy, proving theoretically, and demonstrating empirically that our approach quickly selects high-quality models.
Weighted Meta-Learning
Mar 20, 2020



Meta-learning leverages related source tasks to learn an initialization that can be quickly fine-tuned to a target task with limited labeled examples. However, many popular meta-learning algorithms, such as model-agnostic meta-learning (MAML), only assume access to the target samples for fine-tuning. In this work, we provide a general framework for meta-learning based on weighting the loss of different source tasks, where the weights are allowed to depend on the target samples. In this general setting, we provide upper bounds on the distance of the weighted empirical risk of the source tasks and expected target risk in terms of an integral probability metric (IPM) and Rademacher complexity, which apply to a number of meta-learning settings including MAML and a weighted MAML variant. We then develop a learning algorithm based on minimizing the error bound with respect to an empirical IPM, including a weighted MAML algorithm, $\alpha$-MAML. Finally, we demonstrate empirically on several regression problems that our weighted meta-learning algorithm is able to find better initializations than uniformly-weighted meta-learning algorithms, such as MAML.
Feature Gradients: Scalable Feature Selection via Discrete Relaxation
Aug 27, 2019



In this paper we introduce Feature Gradients, a gradient-based search algorithm for feature selection. Our approach extends a recent result on the estimation of learnability in the sublinear data regime by showing that the calculation can be performed iteratively (i.e., in mini-batches) and in linear time and space with respect to both the number of features D and the sample size N . This, along with a discrete-to-continuous relaxation of the search domain, allows for an efficient, gradient-based search algorithm among feature subsets for very large datasets. Crucially, our algorithm is capable of finding higher-order correlations between features and targets for both the N > D and N < D regimes, as opposed to approaches that do not consider such interactions and/or only consider one regime. We provide experimental demonstration of the algorithm in small and large sample-and feature-size settings.