 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEric Horvitz
The Rise of the AI Co-Pilot: Lessons for Design from Aviation and Beyond
Nov 29, 2023
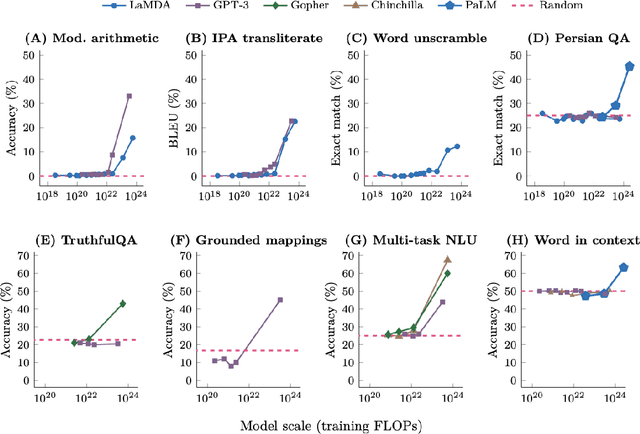
The fast pace of advances in AI promises to revolutionize various aspects of knowledge work, extending its influence to daily life and professional fields alike. We advocate for a paradigm where AI is seen as a collaborative co-pilot, working under human guidance rather than as a mere tool. Drawing from relevant research and literature in the disciplines of Human-Computer Interaction and Human Factors Engineering, we highlight the criticality of maintaining human oversight in AI interactions. Reflecting on lessons from aviation, we address the dangers of over-relying on automation, such as diminished human vigilance and skill erosion. Our paper proposes a design approach that emphasizes active human engagement, control, and skill enhancement in the AI partnership, aiming to foster a harmonious, effective, and empowering human-AI relationship. We particularly call out the critical need to design AI interaction capabilities and software applications to enable and celebrate the primacy of human agency. This calls for designs for human-AI partnership that cede ultimate control and responsibility to the human user as pilot, with the AI co-pilot acting in a well-defined supporting role.
Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine
Nov 28, 2023Generalist foundation models such as GPT-4 have displayed surprising capabilities in a wide variety of domains and tasks. Yet, there is a prevalent assumption that they cannot match specialist capabilities of fine-tuned models. For example, most explorations to date on medical competency benchmarks have leveraged domain-specific training, as exemplified by efforts on BioGPT and Med-PaLM. We build on a prior study of GPT-4's capabilities on medical challenge benchmarks in the absence of special training. Rather than using simple prompting to highlight the model's out-of-the-box capabilities, we perform a systematic exploration of prompt engineering. We find that prompting innovation can unlock deeper specialist capabilities and show that GPT-4 easily tops prior leading results for medical benchmarks. The prompting methods we explore are general purpose, and make no specific use of domain expertise, removing the need for expert-curated content. Our experimental design carefully controls for overfitting during the prompt engineering process. We introduce Medprompt, based on a composition of several prompting strategies. With Medprompt, GPT-4 achieves state-of-the-art results on all nine of the benchmark datasets in the MultiMedQA suite. The method outperforms leading specialist models such as Med-PaLM 2 by a significant margin with an order of magnitude fewer calls to the model. Steering GPT-4 with Medprompt achieves a 27% reduction in error rate on the MedQA dataset over the best methods to date achieved with specialist models and surpasses a score of 90% for the first time. Beyond medical problems, we show the power of Medprompt to generalize to other domains and provide evidence for the broad applicability of the approach via studies of the strategy on exams in electrical engineering, machine learning, philosophy, accounting, law, nursing, and clinical psychology.
Frontier AI Regulation: Managing Emerging Risks to Public Safety
Jul 11, 2023
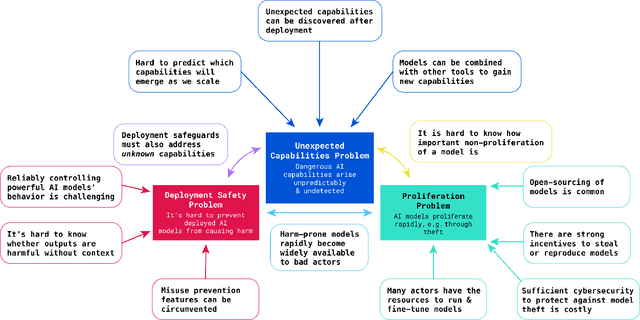
Advanced AI models hold the promise of tremendous benefits for humanity, but society needs to proactively manage the accompanying risks. In this paper, we focus on what we term "frontier AI" models: highly capable foundation models that could possess dangerous capabilities sufficient to pose severe risks to public safety. Frontier AI models pose a distinct regulatory challenge: dangerous capabilities can arise unexpectedly; it is difficult to robustly prevent a deployed model from being misused; and, it is difficult to stop a model's capabilities from proliferating broadly. To address these challenges, at least three building blocks for the regulation of frontier models are needed: (1) standard-setting processes to identify appropriate requirements for frontier AI developers, (2) registration and reporting requirements to provide regulators with visibility into frontier AI development processes, and (3) mechanisms to ensure compliance with safety standards for the development and deployment of frontier AI models. Industry self-regulation is an important first step. However, wider societal discussions and government intervention will be needed to create standards and to ensure compliance with them. We consider several options to this end, including granting enforcement powers to supervisory authorities and licensure regimes for frontier AI models. Finally, we propose an initial set of safety standards. These include conducting pre-deployment risk assessments; external scrutiny of model behavior; using risk assessments to inform deployment decisions; and monitoring and responding to new information about model capabilities and uses post-deployment. We hope this discussion contributes to the broader conversation on how to balance public safety risks and innovation benefits from advances at the frontier of AI development.
Accurate Measures of Vaccination and Concerns of Vaccine Holdouts from Web Search Logs
Jun 12, 2023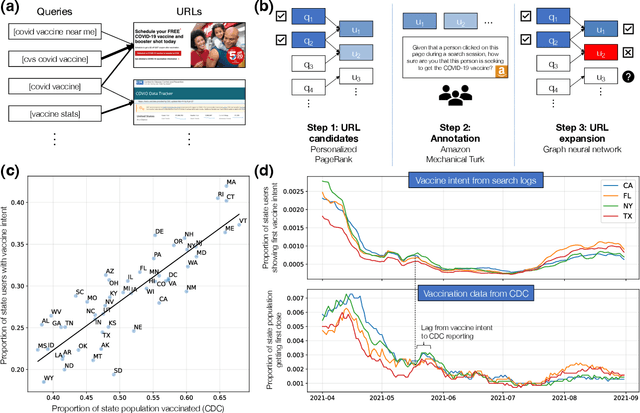
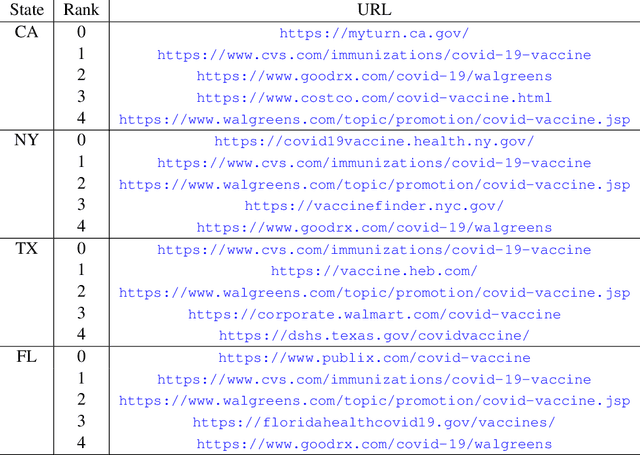
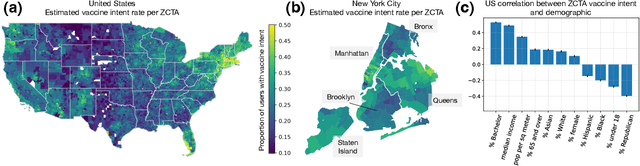
To design effective vaccine policies, policymakers need detailed data about who has been vaccinated, who is holding out, and why. However, existing data in the US are insufficient: reported vaccination rates are often delayed or missing, and surveys of vaccine hesitancy are limited by high-level questions and self-report biases. Here, we show how large-scale search engine logs and machine learning can be leveraged to fill these gaps and provide novel insights about vaccine intentions and behaviors. First, we develop a vaccine intent classifier that can accurately detect when a user is seeking the COVID-19 vaccine on search. Our classifier demonstrates strong agreement with CDC vaccination rates, with correlations above 0.86, and estimates vaccine intent rates to the level of ZIP codes in real time, allowing us to pinpoint more granular trends in vaccine seeking across regions, demographics, and time. To investigate vaccine hesitancy, we use our classifier to identify two groups, vaccine early adopters and vaccine holdouts. We find that holdouts, compared to early adopters matched on covariates, are 69% more likely to click on untrusted news sites. Furthermore, we organize 25,000 vaccine-related URLs into a hierarchical ontology of vaccine concerns, and we find that holdouts are far more concerned about vaccine requirements, vaccine development and approval, and vaccine myths, and even within holdouts, concerns vary significantly across demographic groups. Finally, we explore the temporal dynamics of vaccine concerns and vaccine seeking, and find that key indicators emerge when individuals convert from holding out to preparing to accept the vaccine.
When to Show a Suggestion? Integrating Human Feedback in AI-Assisted Programming
Jun 08, 2023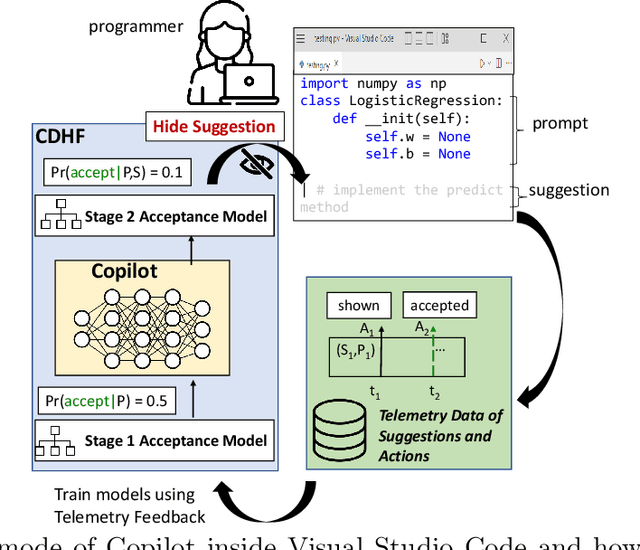
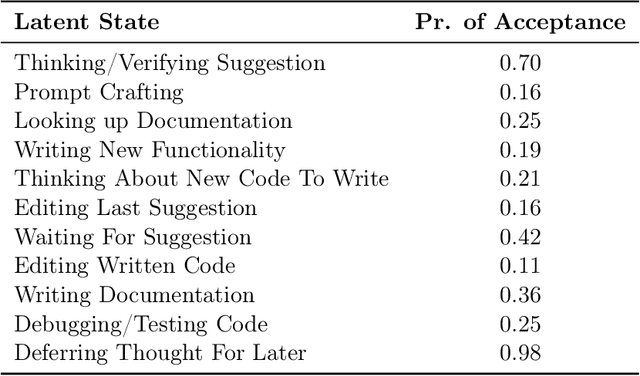
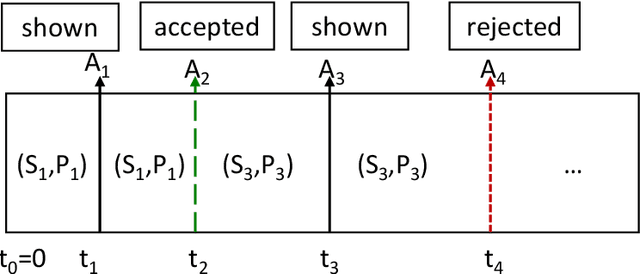
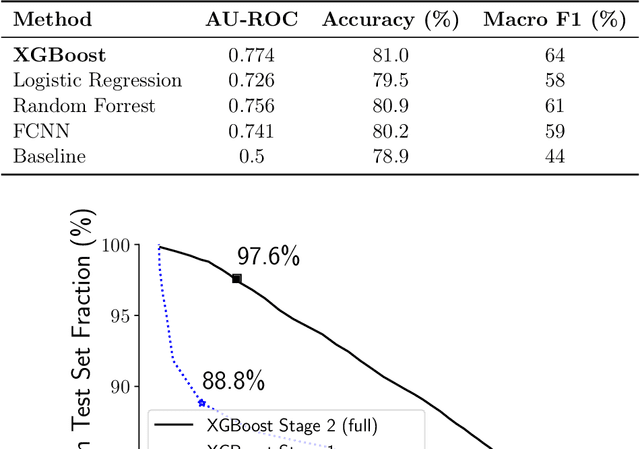
AI powered code-recommendation systems, such as Copilot and CodeWhisperer, provide code suggestions inside a programmer's environment (e.g., an IDE) with the aim to improve their productivity. Since, in these scenarios, programmers accept and reject suggestions, ideally, such a system should use this feedback in furtherance of this goal. In this work we leverage prior data of programmers interacting with Copilot to develop interventions that can save programmer time. We propose a utility theory framework, which models this interaction with programmers and decides when and which suggestions to display. Our framework Conditional suggestion Display from Human Feedback (CDHF) is based on predictive models of programmer actions. Using data from 535 programmers we build models that predict the likelihood of suggestion acceptance. In a retrospective evaluation on real-world programming tasks solved with AI-assisted programming, we find that CDHF can achieve favorable tradeoffs. Our findings show the promise of integrating human feedback to improve interaction with large language models in scenarios such as programming and possibly writing tasks.
Evaluation of GPT-3.5 and GPT-4 for supporting real-world information needs in healthcare delivery
May 01, 2023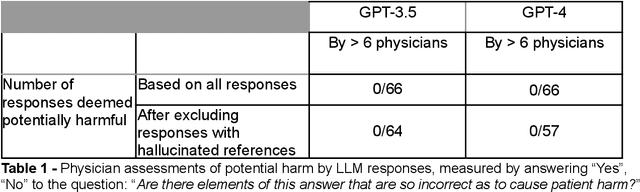
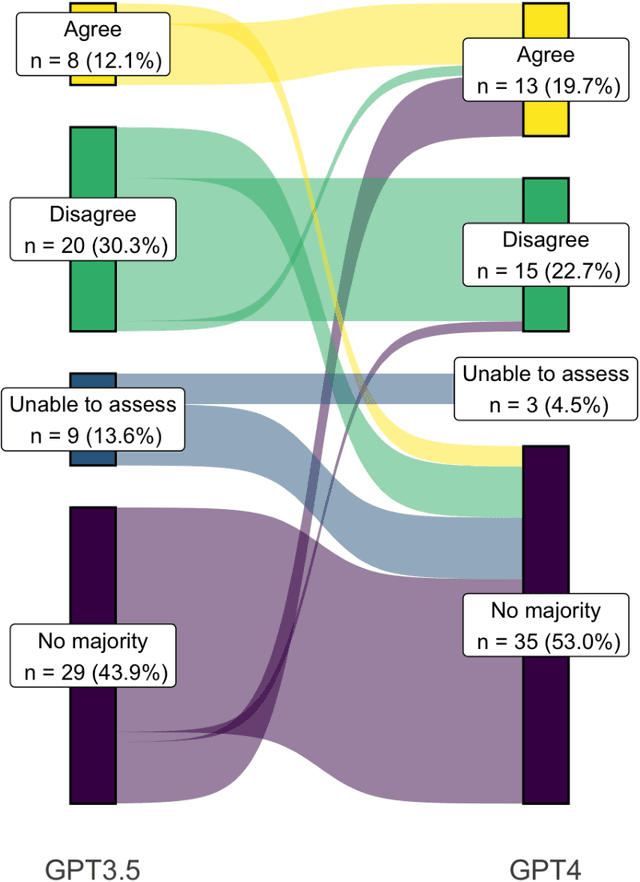
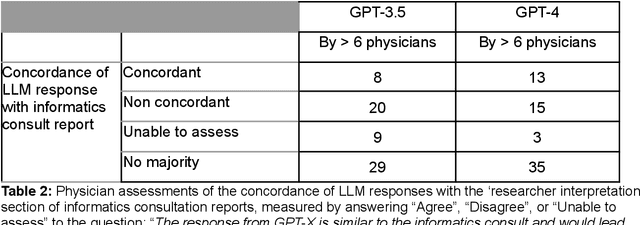
Despite growing interest in using large language models (LLMs) in healthcare, current explorations do not assess the real-world utility and safety of LLMs in clinical settings. Our objective was to determine whether two LLMs can serve information needs submitted by physicians as questions to an informatics consultation service in a safe and concordant manner. Sixty six questions from an informatics consult service were submitted to GPT-3.5 and GPT-4 via simple prompts. 12 physicians assessed the LLM responses' possibility of patient harm and concordance with existing reports from an informatics consultation service. Physician assessments were summarized based on majority vote. For no questions did a majority of physicians deem either LLM response as harmful. For GPT-3.5, responses to 8 questions were concordant with the informatics consult report, 20 discordant, and 9 were unable to be assessed. There were 29 responses with no majority on "Agree", "Disagree", and "Unable to assess". For GPT-4, responses to 13 questions were concordant, 15 discordant, and 3 were unable to be assessed. There were 35 responses with no majority. Responses from both LLMs were largely devoid of overt harm, but less than 20% of the responses agreed with an answer from an informatics consultation service, responses contained hallucinated references, and physicians were divided on what constitutes harm. These results suggest that while general purpose LLMs are able to provide safe and credible responses, they often do not meet the specific information need of a given question. A definitive evaluation of the usefulness of LLMs in healthcare settings will likely require additional research on prompt engineering, calibration, and custom-tailoring of general purpose models.
Ideal Abstractions for Decision-Focused Learning
Mar 29, 2023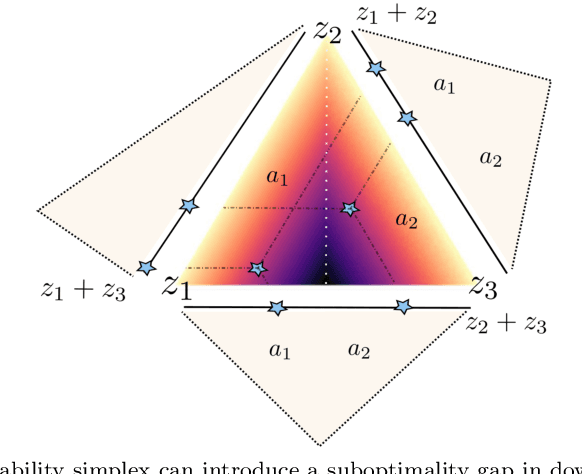
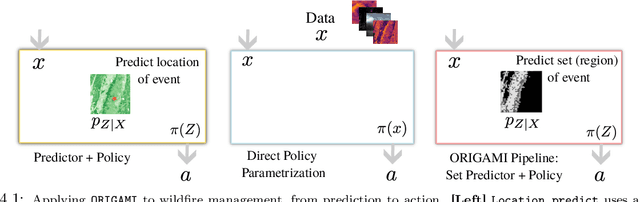
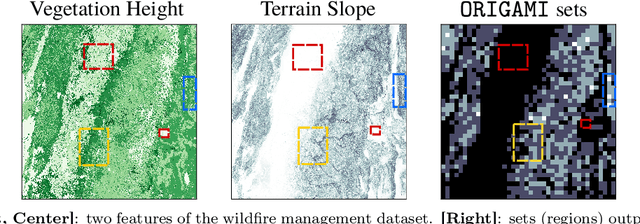
We present a methodology for formulating simplifying abstractions in machine learning systems by identifying and harnessing the utility structure of decisions. Machine learning tasks commonly involve high-dimensional output spaces (e.g., predictions for every pixel in an image or node in a graph), even though a coarser output would often suffice for downstream decision-making (e.g., regions of an image instead of pixels). Developers often hand-engineer abstractions of the output space, but numerous abstractions are possible and it is unclear how the choice of output space for a model impacts its usefulness in downstream decision-making. We propose a method that configures the output space automatically in order to minimize the loss of decision-relevant information. Taking a geometric perspective, we formulate a step of the algorithm as a projection of the probability simplex, termed fold, that minimizes the total loss of decision-related information in the H-entropy sense. Crucially, learning in the abstracted outcome space requires less data, leading to a net improvement in decision quality. We demonstrate the method in two domains: data acquisition for deep neural network training and a closed-loop wildfire management task.
Sparks of Artificial General Intelligence: Early experiments with GPT-4
Mar 27, 2023
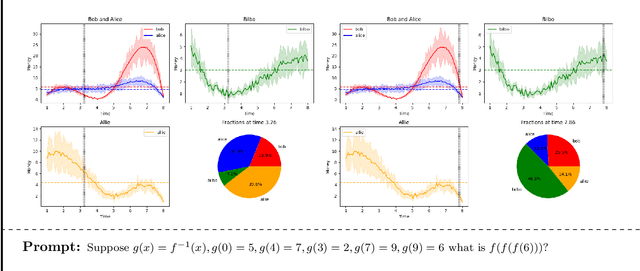


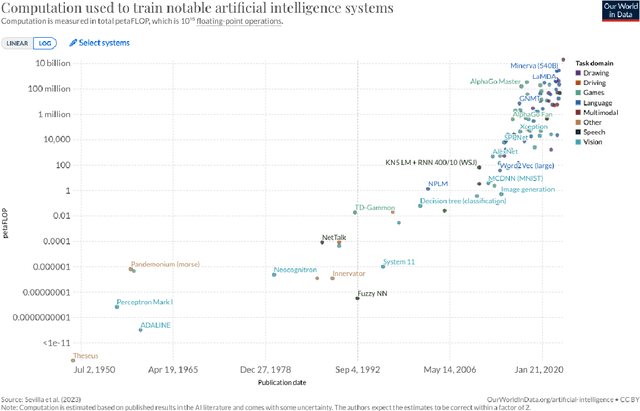
Artificial intelligence (AI) researchers have been developing and refining large language models (LLMs) that exhibit remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. The latest model developed by OpenAI, GPT-4, was trained using an unprecedented scale of compute and data. In this paper, we report on our investigation of an early version of GPT-4, when it was still in active development by OpenAI. We contend that (this early version of) GPT-4 is part of a new cohort of LLMs (along with ChatGPT and Google's PaLM for example) that exhibit more general intelligence than previous AI models. We discuss the rising capabilities and implications of these models. We demonstrate that, beyond its mastery of language, GPT-4 can solve novel and difficult tasks that span mathematics, coding, vision, medicine, law, psychology and more, without needing any special prompting. Moreover, in all of these tasks, GPT-4's performance is strikingly close to human-level performance, and often vastly surpasses prior models such as ChatGPT. Given the breadth and depth of GPT-4's capabilities, we believe that it could reasonably be viewed as an early (yet still incomplete) version of an artificial general intelligence (AGI) system. In our exploration of GPT-4, we put special emphasis on discovering its limitations, and we discuss the challenges ahead for advancing towards deeper and more comprehensive versions of AGI, including the possible need for pursuing a new paradigm that moves beyond next-word prediction. We conclude with reflections on societal influences of the recent technological leap and future research directions.
Capabilities of GPT-4 on Medical Challenge Problems
Mar 20, 2023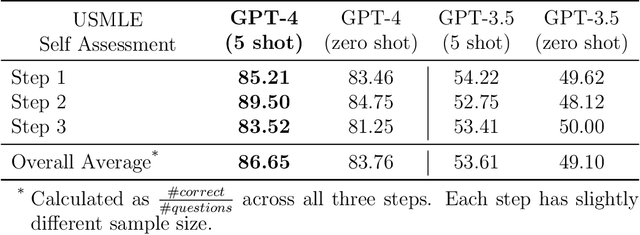
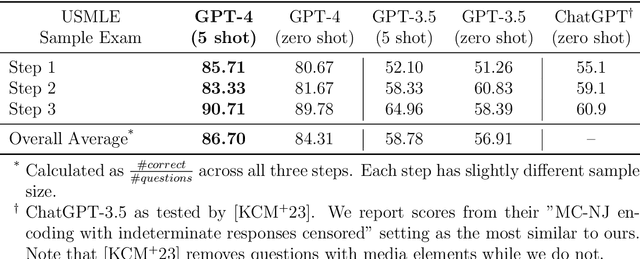
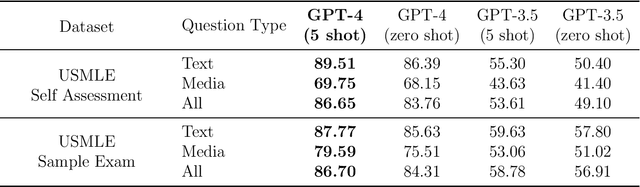
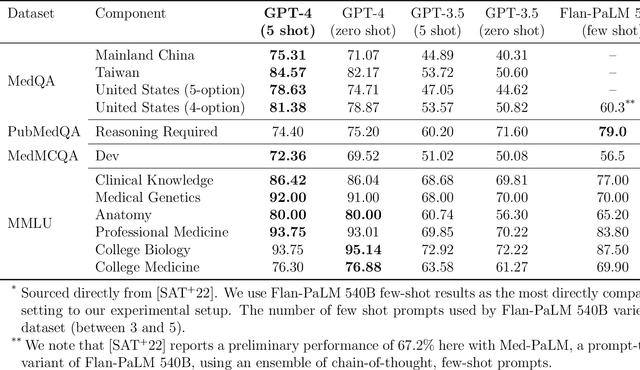
Large language models (LLMs) have demonstrated remarkable capabilities in natural language understanding and generation across various domains, including medicine. We present a comprehensive evaluation of GPT-4, a state-of-the-art LLM, on medical competency examinations and benchmark datasets. GPT-4 is a general-purpose model that is not specialized for medical problems through training or engineered to solve clinical tasks. Our analysis covers two sets of official practice materials for the USMLE, a three-step examination program used to assess clinical competency and grant licensure in the United States. We also evaluate performance on the MultiMedQA suite of benchmark datasets. Beyond measuring model performance, experiments were conducted to investigate the influence of test questions containing both text and images on model performance, probe for memorization of content during training, and study probability calibration, which is of critical importance in high-stakes applications like medicine. Our results show that GPT-4, without any specialized prompt crafting, exceeds the passing score on USMLE by over 20 points and outperforms earlier general-purpose models (GPT-3.5) as well as models specifically fine-tuned on medical knowledge (Med-PaLM, a prompt-tuned version of Flan-PaLM 540B). In addition, GPT-4 is significantly better calibrated than GPT-3.5, demonstrating a much-improved ability to predict the likelihood that its answers are correct. We also explore the behavior of the model qualitatively through a case study that shows the ability of GPT-4 to explain medical reasoning, personalize explanations to students, and interactively craft new counterfactual scenarios around a medical case. Implications of the findings are discussed for potential uses of GPT-4 in medical education, assessment, and clinical practice, with appropriate attention to challenges of accuracy and safety.
Benchmarking Spatial Relationships in Text-to-Image Generation
Dec 20, 2022

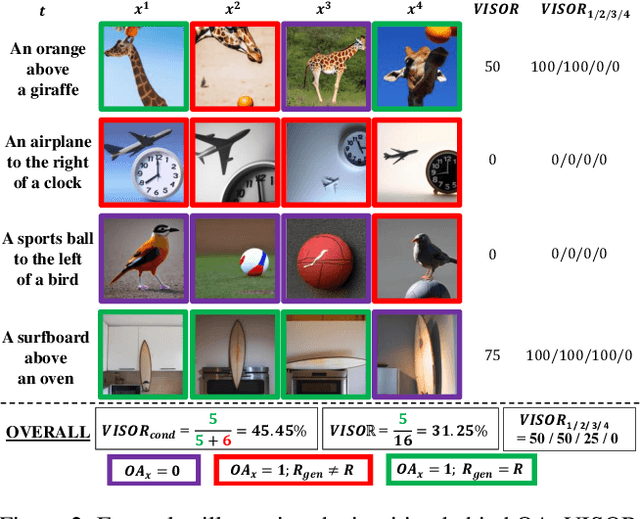

Spatial understanding is a fundamental aspect of computer vision and integral for human-level reasoning about images, making it an important component for grounded language understanding. While recent large-scale text-to-image synthesis (T2I) models have shown unprecedented improvements in photorealism, it is unclear whether they have reliable spatial understanding capabilities. We investigate the ability of T2I models to generate correct spatial relationships among objects and present VISOR, an evaluation metric that captures how accurately the spatial relationship described in text is generated in the image. To benchmark existing models, we introduce a large-scale challenge dataset SR2D that contains sentences describing two objects and the spatial relationship between them. We construct and harness an automated evaluation pipeline that employs computer vision to recognize objects and their spatial relationships, and we employ it in a large-scale evaluation of T2I models. Our experiments reveal a surprising finding that, although recent state-of-the-art T2I models exhibit high image quality, they are severely limited in their ability to generate multiple objects or the specified spatial relations such as left/right/above/below. Our analyses demonstrate several biases and artifacts of T2I models such as the difficulty with generating multiple objects, a bias towards generating the first object mentioned, spatially inconsistent outputs for equivalent relationships, and a correlation between object co-occurrence and spatial understanding capabilities. We conduct a human study that shows the alignment between VISOR and human judgment about spatial understanding. We offer the SR2D dataset and the VISOR metric to the community in support of T2I spatial reasoning research.