 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBesmira Nushi
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024
This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
Elephants Never Forget: Memorization and Learning of Tabular Data in Large Language Models
Apr 09, 2024While many have shown how Large Language Models (LLMs) can be applied to a diverse set of tasks, the critical issues of data contamination and memorization are often glossed over. In this work, we address this concern for tabular data. Specifically, we introduce a variety of different techniques to assess whether a language model has seen a tabular dataset during training. This investigation reveals that LLMs have memorized many popular tabular datasets verbatim. We then compare the few-shot learning performance of LLMs on datasets that were seen during training to the performance on datasets released after training. We find that LLMs perform better on datasets seen during training, indicating that memorization leads to overfitting. At the same time, LLMs show non-trivial performance on novel datasets and are surprisingly robust to data transformations. We then investigate the in-context statistical learning abilities of LLMs. Without fine-tuning, we find them to be limited. This suggests that much of the few-shot performance on novel datasets is due to the LLM's world knowledge. Overall, our results highlight the importance of testing whether an LLM has seen an evaluation dataset during pre-training. We make the exposure tests we developed available as the tabmemcheck Python package at https://github.com/interpretml/LLM-Tabular-Memorization-Checker
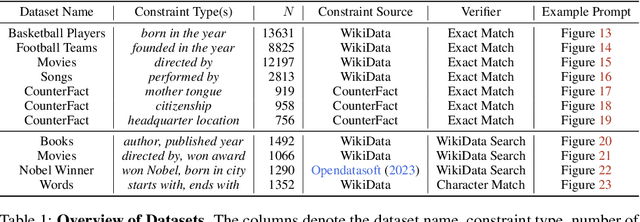
KITAB: Evaluating LLMs on Constraint Satisfaction for Information Retrieval
Oct 24, 2023We study the ability of state-of-the art models to answer constraint satisfaction queries for information retrieval (e.g., 'a list of ice cream shops in San Diego'). In the past, such queries were considered to be tasks that could only be solved via web-search or knowledge bases. More recently, large language models (LLMs) have demonstrated initial emergent abilities in this task. However, many current retrieval benchmarks are either saturated or do not measure constraint satisfaction. Motivated by rising concerns around factual incorrectness and hallucinations of LLMs, we present KITAB, a new dataset for measuring constraint satisfaction abilities of language models. KITAB consists of book-related data across more than 600 authors and 13,000 queries, and also offers an associated dynamic data collection and constraint verification approach for acquiring similar test data for other authors. Our extended experiments on GPT4 and GPT3.5 characterize and decouple common failure modes across dimensions such as information popularity, constraint types, and context availability. Results show that in the absence of context, models exhibit severe limitations as measured by irrelevant information, factual errors, and incompleteness, many of which exacerbate as information popularity decreases. While context availability mitigates irrelevant information, it is not helpful for satisfying constraints, identifying fundamental barriers to constraint satisfaction. We open source our contributions to foster further research on improving constraint satisfaction abilities of future models.
Diversity of Thought Improves Reasoning Abilities of Large Language Models
Oct 11, 2023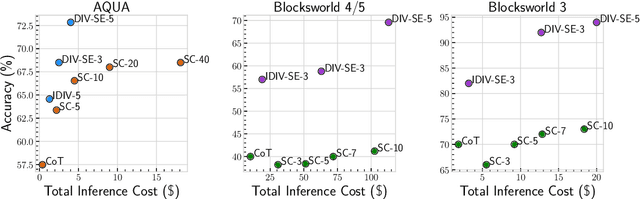
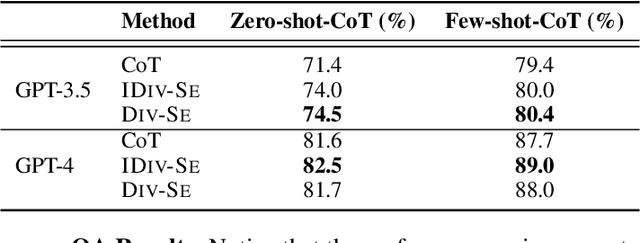
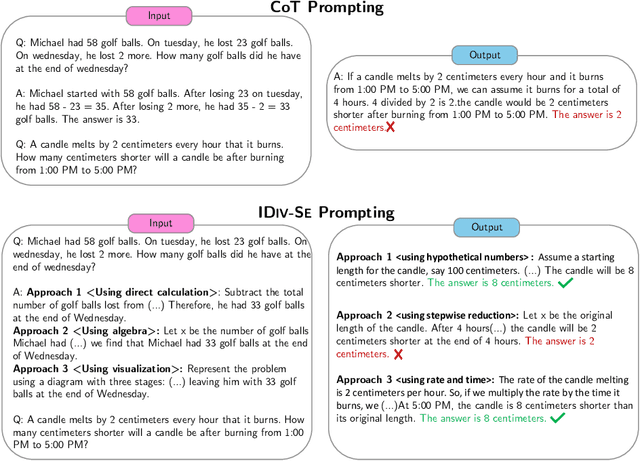
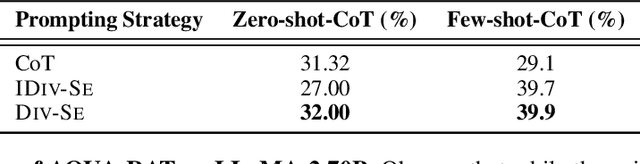
Large language models (LLMs) are documented to struggle in settings that require complex reasoning. Nevertheless, instructing the model to break down the problem into smaller reasoning steps (Wei et al., 2022), or ensembling various generations through modifying decoding steps (Wang et al., 2023) boosts performance. Current methods assume that the input prompt is fixed and expect the decoding strategies to introduce the diversity needed for ensembling. In this work, we relax this assumption and discuss how one can create and leverage variations of the input prompt as a means to diversity of thought to improve model performance. We propose a method that automatically improves prompt diversity by soliciting feedback from the LLM to ideate approaches that fit for the problem. We then ensemble the diverse prompts in our method DIV-SE (DIVerse reasoning path Self-Ensemble) across multiple inference calls. We also propose a cost-effective alternative where diverse prompts are used within a single inference call; we call this IDIV-SE (In-call DIVerse reasoning path Self-Ensemble). Under a fixed generation budget, DIV-SE and IDIV-SE outperform the previously discussed baselines using both GPT-3.5 and GPT-4 on several reasoning benchmarks, without modifying the decoding process. Additionally, DIV-SE advances state-of-the-art performance on recent planning benchmarks (Valmeekam et al., 2023), exceeding the highest previously reported accuracy by at least 29.6 percentage points on the most challenging 4/5 Blocksworld task. Our results shed light on how to enforce prompt diversity toward LLM reasoning and thereby improve the pareto frontier of the accuracy-cost trade-off.
Attention Satisfies: A Constraint-Satisfaction Lens on Factual Errors of Language Models
Sep 26, 2023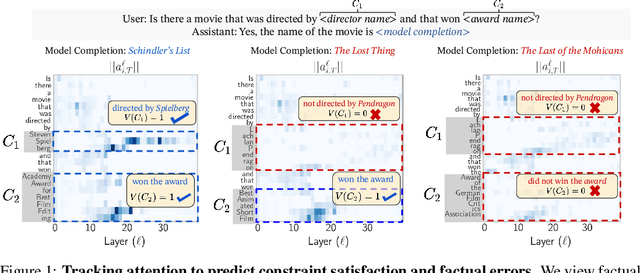
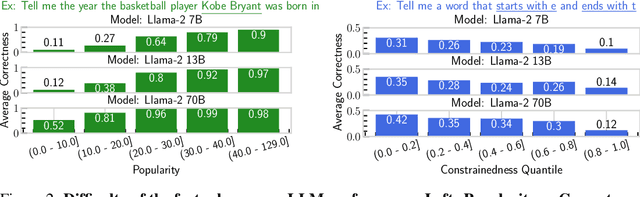

We investigate the internal behavior of Transformer-based Large Language Models (LLMs) when they generate factually incorrect text. We propose modeling factual queries as Constraint Satisfaction Problems and use this framework to investigate how the model interacts internally with factual constraints. Specifically, we discover a strong positive relation between the model's attention to constraint tokens and the factual accuracy of its responses. In our curated suite of 11 datasets with over 40,000 prompts, we study the task of predicting factual errors with the Llama-2 family across all scales (7B, 13B, 70B). We propose SAT Probe, a method probing self-attention patterns, that can predict constraint satisfaction and factual errors, and allows early error identification. The approach and findings demonstrate how using the mechanistic understanding of factuality in LLMs can enhance reliability.
Mitigating Spurious Correlations in Multi-modal Models during Fine-tuning
Apr 08, 2023

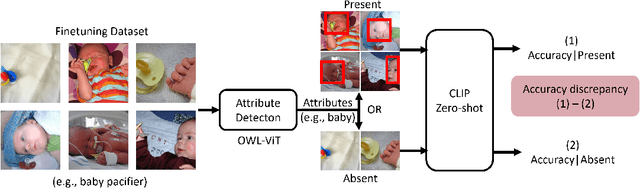
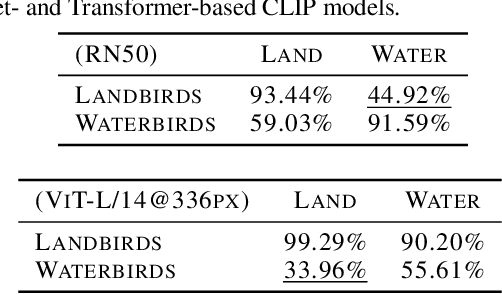
Spurious correlations that degrade model generalization or lead the model to be right for the wrong reasons are one of the main robustness concerns for real-world deployments. However, mitigating these correlations during pre-training for large-scale models can be costly and impractical, particularly for those without access to high-performance computing resources. This paper proposes a novel approach to address spurious correlations during fine-tuning for a given domain of interest. With a focus on multi-modal models (e.g., CLIP), the proposed method leverages different modalities in these models to detect and explicitly set apart spurious attributes from the affected class, achieved through a multi-modal contrastive loss function that expresses spurious relationships through language. Our experimental results and in-depth visualizations on CLIP show that such an intervention can effectively i) improve the model's accuracy when spurious attributes are not present, and ii) directs the model's activation maps towards the actual class rather than the spurious attribute when present. In particular, on the Waterbirds dataset, our algorithm achieved a worst-group accuracy 23% higher than ERM on CLIP with a ResNet-50 backbone, and 32% higher on CLIP with a ViT backbone, while maintaining the same average accuracy as ERM.
Social Biases through the Text-to-Image Generation Lens
Mar 30, 2023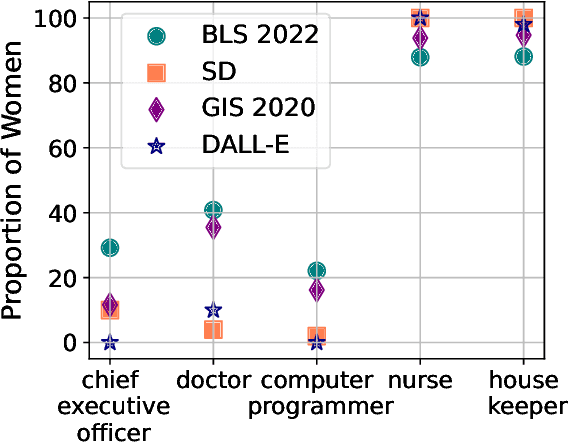
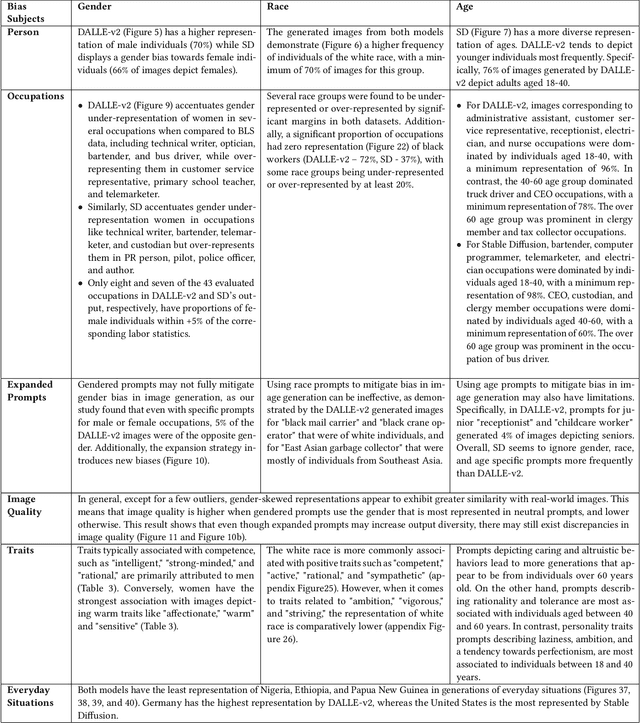

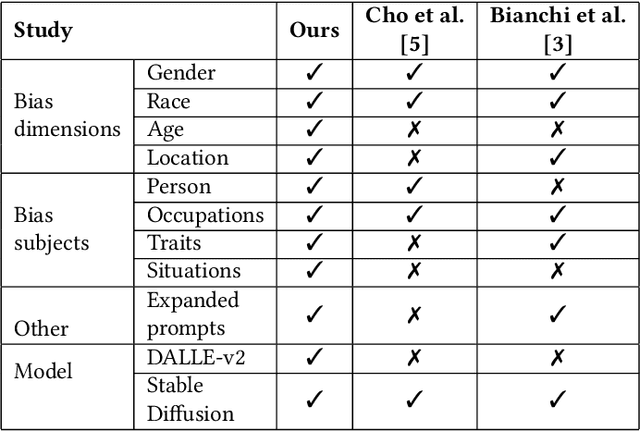
Text-to-Image (T2I) generation is enabling new applications that support creators, designers, and general end users of productivity software by generating illustrative content with high photorealism starting from a given descriptive text as a prompt. Such models are however trained on massive amounts of web data, which surfaces the peril of potential harmful biases that may leak in the generation process itself. In this paper, we take a multi-dimensional approach to studying and quantifying common social biases as reflected in the generated images, by focusing on how occupations, personality traits, and everyday situations are depicted across representations of (perceived) gender, age, race, and geographical location. Through an extensive set of both automated and human evaluation experiments we present findings for two popular T2I models: DALLE-v2 and Stable Diffusion. Our results reveal that there exist severe occupational biases of neutral prompts majorly excluding groups of people from results for both models. Such biases can get mitigated by increasing the amount of specification in the prompt itself, although the prompting mitigation will not address discrepancies in image quality or other usages of the model or its representations in other scenarios. Further, we observe personality traits being associated with only a limited set of people at the intersection of race, gender, and age. Finally, an analysis of geographical location representations on everyday situations (e.g., park, food, weddings) shows that for most situations, images generated through default location-neutral prompts are closer and more similar to images generated for locations of United States and Germany.
Benchmarking Spatial Relationships in Text-to-Image Generation
Dec 20, 2022

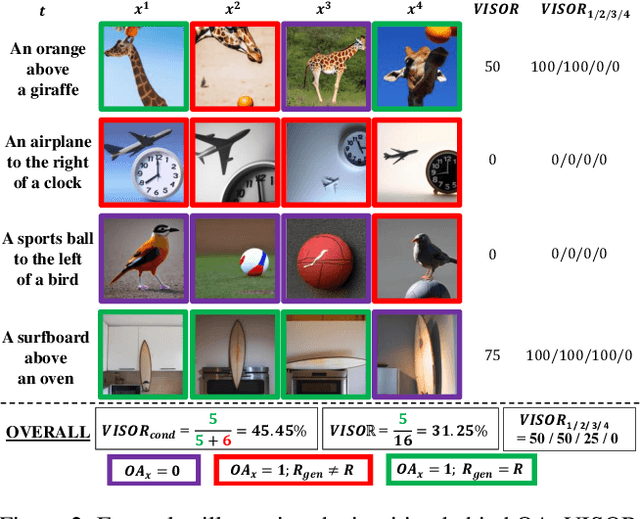

Spatial understanding is a fundamental aspect of computer vision and integral for human-level reasoning about images, making it an important component for grounded language understanding. While recent large-scale text-to-image synthesis (T2I) models have shown unprecedented improvements in photorealism, it is unclear whether they have reliable spatial understanding capabilities. We investigate the ability of T2I models to generate correct spatial relationships among objects and present VISOR, an evaluation metric that captures how accurately the spatial relationship described in text is generated in the image. To benchmark existing models, we introduce a large-scale challenge dataset SR2D that contains sentences describing two objects and the spatial relationship between them. We construct and harness an automated evaluation pipeline that employs computer vision to recognize objects and their spatial relationships, and we employ it in a large-scale evaluation of T2I models. Our experiments reveal a surprising finding that, although recent state-of-the-art T2I models exhibit high image quality, they are severely limited in their ability to generate multiple objects or the specified spatial relations such as left/right/above/below. Our analyses demonstrate several biases and artifacts of T2I models such as the difficulty with generating multiple objects, a bias towards generating the first object mentioned, spatially inconsistent outputs for equivalent relationships, and a correlation between object co-occurrence and spatial understanding capabilities. We conduct a human study that shows the alignment between VISOR and human judgment about spatial understanding. We offer the SR2D dataset and the VISOR metric to the community in support of T2I spatial reasoning research.
Advancing Human-AI Complementarity: The Impact of User Expertise and Algorithmic Tuning on Joint Decision Making
Aug 16, 2022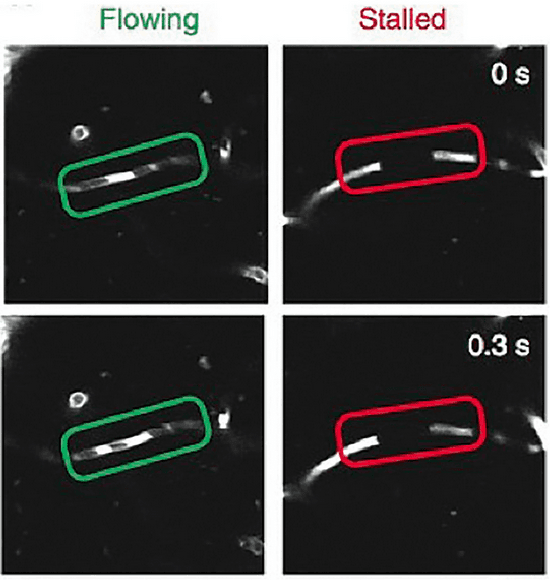

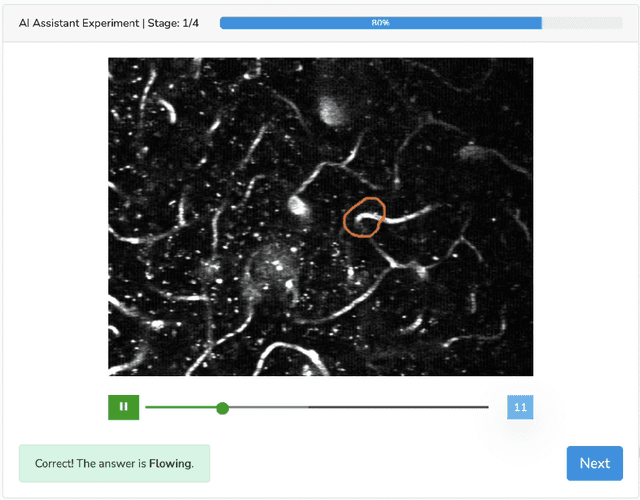

Human-AI collaboration for decision-making strives to achieve team performance that exceeds the performance of humans or AI alone. However, many factors can impact success of Human-AI teams, including a user's domain expertise, mental models of an AI system, trust in recommendations, and more. This work examines users' interaction with three simulated algorithmic models, all with similar accuracy but different tuning on their true positive and true negative rates. Our study examined user performance in a non-trivial blood vessel labeling task where participants indicated whether a given blood vessel was flowing or stalled. Our results show that while recommendations from an AI-Assistant can aid user decision making, factors such as users' baseline performance relative to the AI and complementary tuning of AI error types significantly impact overall team performance. Novice users improved, but not to the accuracy level of the AI. Highly proficient users were generally able to discern when they should follow the AI recommendation and typically maintained or improved their performance. Mid-performers, who had a similar level of accuracy to the AI, were most variable in terms of whether the AI recommendations helped or hurt their performance. In addition, we found that users' perception of the AI's performance relative on their own also had a significant impact on whether their accuracy improved when given AI recommendations. This work provides insights on the complexity of factors related to Human-AI collaboration and provides recommendations on how to develop human-centered AI algorithms to complement users in decision-making tasks.
Who Goes First? Influences of Human-AI Workflow on Decision Making in Clinical Imaging
May 19, 2022

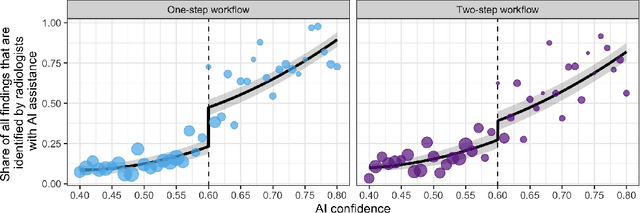
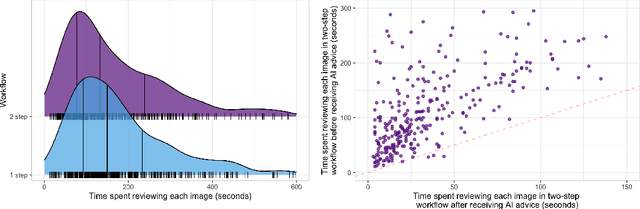
Details of the designs and mechanisms in support of human-AI collaboration must be considered in the real-world fielding of AI technologies. A critical aspect of interaction design for AI-assisted human decision making are policies about the display and sequencing of AI inferences within larger decision-making workflows. We have a poor understanding of the influences of making AI inferences available before versus after human review of a diagnostic task at hand. We explore the effects of providing AI assistance at the start of a diagnostic session in radiology versus after the radiologist has made a provisional decision. We conducted a user study where 19 veterinary radiologists identified radiographic findings present in patients' X-ray images, with the aid of an AI tool. We employed two workflow configurations to analyze (i) anchoring effects, (ii) human-AI team diagnostic performance and agreement, (iii) time spent and confidence in decision making, and (iv) perceived usefulness of the AI. We found that participants who are asked to register provisional responses in advance of reviewing AI inferences are less likely to agree with the AI regardless of whether the advice is accurate and, in instances of disagreement with the AI, are less likely to seek the second opinion of a colleague. These participants also reported the AI advice to be less useful. Surprisingly, requiring provisional decisions on cases in advance of the display of AI inferences did not lengthen the time participants spent on the task. The study provides generalizable and actionable insights for the deployment of clinical AI tools in human-in-the-loop systems and introduces a methodology for studying alternative designs for human-AI collaboration. We make our experimental platform available as open source to facilitate future research on the influence of alternate designs on human-AI workflows.