 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaul Röttger
From Languages to Geographies: Towards Evaluating Cultural Bias in Hate Speech Datasets
Apr 27, 2024
Perceptions of hate can vary greatly across cultural contexts. Hate speech (HS) datasets, however, have traditionally been developed by language. This hides potential cultural biases, as one language may be spoken in different countries home to different cultures. In this work, we evaluate cultural bias in HS datasets by leveraging two interrelated cultural proxies: language and geography. We conduct a systematic survey of HS datasets in eight languages and confirm past findings on their English-language bias, but also show that this bias has been steadily decreasing in the past few years. For three geographically-widespread languages -- English, Arabic and Spanish -- we then leverage geographical metadata from tweets to approximate geo-cultural contexts by pairing language and country information. We find that HS datasets for these languages exhibit a strong geo-cultural bias, largely overrepresenting a handful of countries (e.g., US and UK for English) relative to their prominence in both the broader social media population and the general population speaking these languages. Based on these findings, we formulate recommendations for the creation of future HS datasets.
Near to Mid-term Risks and Opportunities of Open Source Generative AI
Apr 25, 2024In the next few years, applications of Generative AI are expected to revolutionize a number of different areas, ranging from science & medicine to education. The potential for these seismic changes has triggered a lively debate about potential risks and resulted in calls for tighter regulation, in particular from some of the major tech companies who are leading in AI development. This regulation is likely to put at risk the budding field of open source Generative AI. We argue for the responsible open sourcing of generative AI models in the near and medium term. To set the stage, we first introduce an AI openness taxonomy system and apply it to 40 current large language models. We then outline differential benefits and risks of open versus closed source AI and present potential risk mitigation, ranging from best practices to calls for technical and scientific contributions. We hope that this report will add a much needed missing voice to the current public discourse on near to mid-term AI safety and other societal impact.
The PRISM Alignment Project: What Participatory, Representative and Individualised Human Feedback Reveals About the Subjective and Multicultural Alignment of Large Language Models
Apr 24, 2024Human feedback plays a central role in the alignment of Large Language Models (LLMs). However, open questions remain about the methods (how), domains (where), people (who) and objectives (to what end) of human feedback collection. To navigate these questions, we introduce PRISM, a new dataset which maps the sociodemographics and stated preferences of 1,500 diverse participants from 75 countries, to their contextual preferences and fine-grained feedback in 8,011 live conversations with 21 LLMs. PRISM contributes (i) wide geographic and demographic participation in human feedback data; (ii) two census-representative samples for understanding collective welfare (UK and US); and (iii) individualised feedback where every rating is linked to a detailed participant profile, thus permitting exploration of personalisation and attribution of sample artefacts. We focus on collecting conversations that centre subjective and multicultural perspectives on value-laden and controversial topics, where we expect the most interpersonal and cross-cultural disagreement. We demonstrate the usefulness of PRISM via three case studies of dialogue diversity, preference diversity, and welfare outcomes, showing that it matters which humans set alignment norms. As well as offering a rich community resource, we advocate for broader participation in AI development and a more inclusive approach to technology design.
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
Look at the Text: Instruction-Tuned Language Models are More Robust Multiple Choice Selectors than You Think
Apr 12, 2024Multiple choice questions (MCQs) are commonly used to evaluate the capabilities of large language models (LLMs). One common way to evaluate the model response is to rank the candidate answers based on the log probability of the first token prediction. An alternative way is to examine the text output. Prior work has shown that first token probabilities lack robustness to changes in MCQ phrasing, and that first token probabilities do not match text answers for instruction-tuned models. Therefore, in this paper, we investigate the robustness of text answers. We show that the text answers are more robust to question perturbations than the first token probabilities, when the first token answers mismatch the text answers. The difference in robustness increases as the mismatch rate becomes greater. As the mismatch reaches over 50\%, the text answer is more robust to option order changes than the debiased first token probabilities using state-of-the-art debiasing methods such as PriDe. Our findings provide further evidence for the benefits of text answer evaluation over first token probability evaluation.
SafetyPrompts: a Systematic Review of Open Datasets for Evaluating and Improving Large Language Model Safety
Apr 08, 2024The last two years have seen a rapid growth in concerns around the safety of large language models (LLMs). Researchers and practitioners have met these concerns by introducing an abundance of new datasets for evaluating and improving LLM safety. However, much of this work has happened in parallel, and with very different goals in mind, ranging from the mitigation of near-term risks around bias and toxic content generation to the assessment of longer-term catastrophic risk potential. This makes it difficult for researchers and practitioners to find the most relevant datasets for a given use case, and to identify gaps in dataset coverage that future work may fill. To remedy these issues, we conduct a first systematic review of open datasets for evaluating and improving LLM safety. We review 102 datasets, which we identified through an iterative and community-driven process over the course of several months. We highlight patterns and trends, such as a a trend towards fully synthetic datasets, as well as gaps in dataset coverage, such as a clear lack of non-English datasets. We also examine how LLM safety datasets are used in practice -- in LLM release publications and popular LLM benchmarks -- finding that current evaluation practices are highly idiosyncratic and make use of only a small fraction of available datasets. Our contributions are based on SafetyPrompts.com, a living catalogue of open datasets for LLM safety, which we commit to updating continuously as the field of LLM safety develops.
Improving Adversarial Data Collection by Supporting Annotators: Lessons from GAHD, a German Hate Speech Dataset
Mar 28, 2024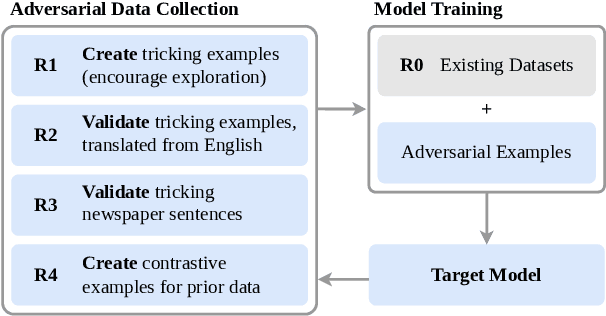
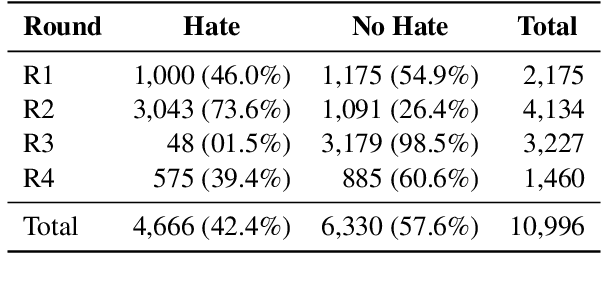
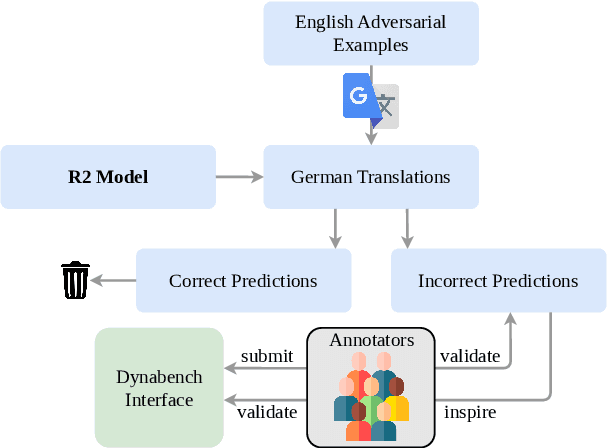

Hate speech detection models are only as good as the data they are trained on. Datasets sourced from social media suffer from systematic gaps and biases, leading to unreliable models with simplistic decision boundaries. Adversarial datasets, collected by exploiting model weaknesses, promise to fix this problem. However, adversarial data collection can be slow and costly, and individual annotators have limited creativity. In this paper, we introduce GAHD, a new German Adversarial Hate speech Dataset comprising ca.\ 11k examples. During data collection, we explore new strategies for supporting annotators, to create more diverse adversarial examples more efficiently and provide a manual analysis of annotator disagreements for each strategy. Our experiments show that the resulting dataset is challenging even for state-of-the-art hate speech detection models, and that training on GAHD clearly improves model robustness. Further, we find that mixing multiple support strategies is most advantageous. We make GAHD publicly available at https://github.com/jagol/gahd.
Evaluating the Elementary Multilingual Capabilities of Large Language Models with MultiQ
Mar 06, 2024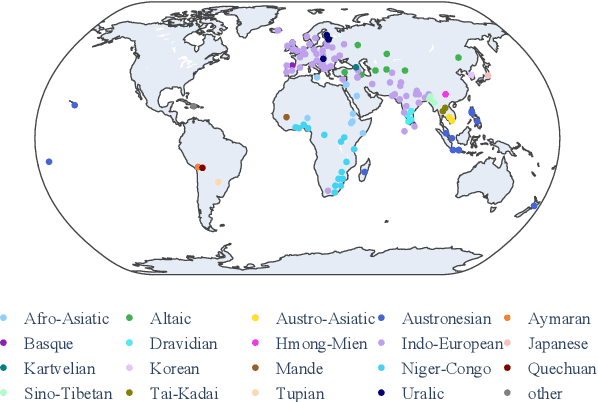

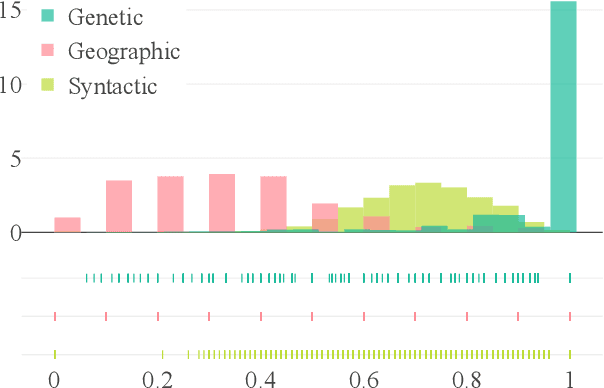
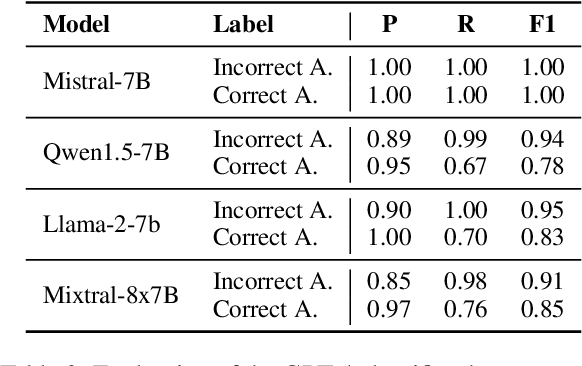
Large language models (LLMs) need to serve everyone, including a global majority of non-English speakers. However, most LLMs today, and open LLMs in particular, are often intended for use in just English (e.g. Llama2, Mistral) or a small handful of high-resource languages (e.g. Mixtral, Qwen). Recent research shows that, despite limits in their intended use, people prompt LLMs in many different languages. Therefore, in this paper, we investigate the basic multilingual capabilities of state-of-the-art open LLMs beyond their intended use. For this purpose, we introduce MultiQ, a new silver standard benchmark for basic open-ended question answering with 27.4k test questions across a typologically diverse set of 137 languages. With MultiQ, we evaluate language fidelity, i.e.\ whether models respond in the prompted language, and question answering accuracy. All LLMs we test respond faithfully and/or accurately for at least some languages beyond their intended use. Most models are more accurate when they respond faithfully. However, differences across models are large, and there is a long tail of languages where models are neither accurate nor faithful. We explore differences in tokenization as a potential explanation for our findings, identifying possible correlations that warrant further investigation.
Political Compass or Spinning Arrow? Towards More Meaningful Evaluations for Values and Opinions in Large Language Models
Feb 26, 2024Much recent work seeks to evaluate values and opinions in large language models (LLMs) using multiple-choice surveys and questionnaires. Most of this work is motivated by concerns around real-world LLM applications. For example, politically-biased LLMs may subtly influence society when they are used by millions of people. Such real-world concerns, however, stand in stark contrast to the artificiality of current evaluations: real users do not typically ask LLMs survey questions. Motivated by this discrepancy, we challenge the prevailing constrained evaluation paradigm for values and opinions in LLMs and explore more realistic unconstrained evaluations. As a case study, we focus on the popular Political Compass Test (PCT). In a systematic review, we find that most prior work using the PCT forces models to comply with the PCT's multiple-choice format. We show that models give substantively different answers when not forced; that answers change depending on how models are forced; and that answers lack paraphrase robustness. Then, we demonstrate that models give different answers yet again in a more realistic open-ended answer setting. We distill these findings into recommendations and open challenges in evaluating values and opinions in LLMs.
"My Answer is C": First-Token Probabilities Do Not Match Text Answers in Instruction-Tuned Language Models
Feb 22, 2024The open-ended nature of language generation makes the evaluation of autoregressive large language models (LLMs) challenging. One common evaluation approach uses multiple-choice questions (MCQ) to limit the response space. The model is then evaluated by ranking the candidate answers by the log probability of the first token prediction. However, first-tokens may not consistently reflect the final response output, due to model's diverse response styles such as starting with "Sure" or refusing to answer. Consequently, MCQ evaluation is not indicative of model behaviour when interacting with users. But by how much? We evaluate how aligned first-token evaluation is with the text output along several dimensions, namely final option choice, refusal rate, choice distribution and robustness under prompt perturbation. Our results show that the two approaches are severely misaligned on all dimensions, reaching mismatch rates over 60%. Models heavily fine-tuned on conversational or safety data are especially impacted. Crucially, models remain misaligned even when we increasingly constrain prompts, i.e., force them to start with an option letter or example template. Our findings i) underscore the importance of inspecting the text output, too and ii) caution against relying solely on first-token evaluation.