 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVithursan Thangarasa
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024
This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
MediSwift: Efficient Sparse Pre-trained Biomedical Language Models
Mar 01, 2024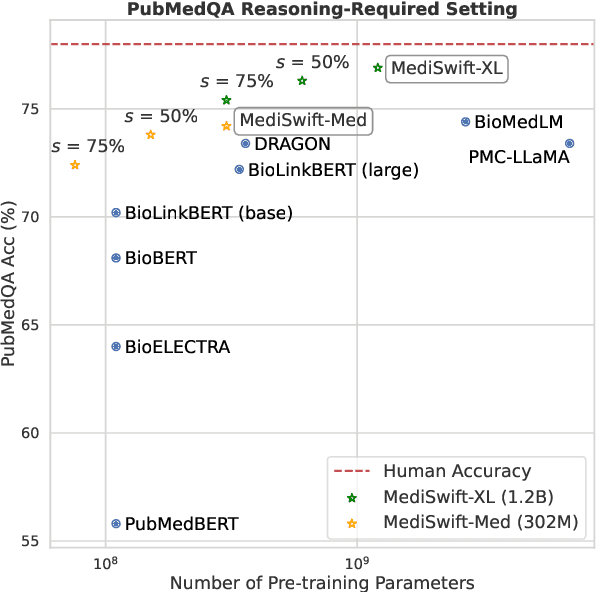
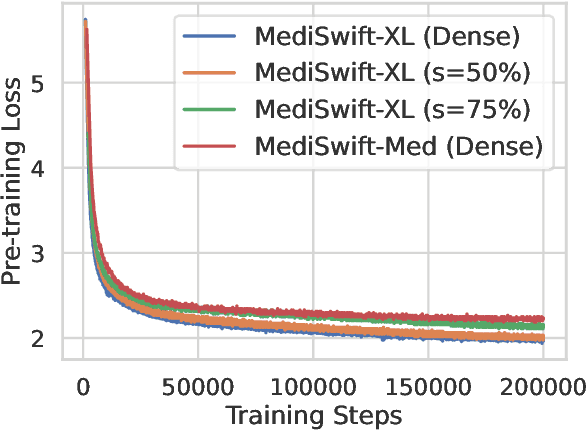
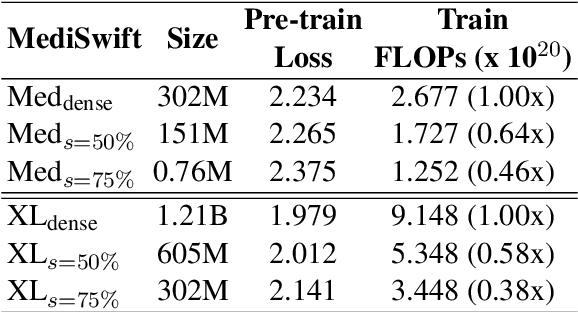
Large language models (LLMs) are typically trained on general source data for various domains, but a recent surge in domain-specific LLMs has shown their potential to outperform general-purpose models in domain-specific tasks (e.g., biomedicine). Although domain-specific pre-training enhances efficiency and leads to smaller models, the computational costs of training these LLMs remain high, posing budgeting challenges. We introduce MediSwift, a suite of biomedical LMs that leverage sparse pre-training on domain-specific biomedical text data. By inducing up to 75% weight sparsity during the pre-training phase, MediSwift achieves a 2-2.5x reduction in training FLOPs. Notably, all sparse pre-training was performed on the Cerebras CS-2 system, which is specifically designed to realize the acceleration benefits from unstructured weight sparsity, thereby significantly enhancing the efficiency of the MediSwift models. Through subsequent dense fine-tuning and strategic soft prompting, MediSwift models outperform existing LLMs up to 7B parameters on biomedical tasks, setting new benchmarks w.r.t efficiency-accuracy on tasks such as PubMedQA. Our results show that sparse pre-training, along with dense fine-tuning and soft prompting, offers an effective method for creating high-performing, computationally efficient models in specialized domains.
Sparse Iso-FLOP Transformations for Maximizing Training Efficiency
Mar 25, 2023

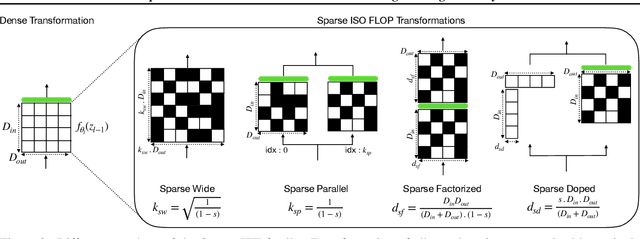

Recent works have explored the use of weight sparsity to improve the training efficiency (test accuracy w.r.t training FLOPs) of deep neural networks (DNNs). These works aim to reduce training FLOPs but training with sparse weights often leads to accuracy loss or requires longer training schedules, making the resulting training efficiency less clear. In contrast, we focus on using sparsity to increase accuracy while using the same FLOPs as the dense model and show training efficiency gains through higher accuracy. In this work, we introduce Sparse-IFT, a family of Sparse Iso-FLOP Transformations which are used as drop-in replacements for dense layers to improve their representational capacity and FLOP efficiency. Each transformation is parameterized by a single hyperparameter (sparsity level) and provides a larger search space to find optimal sparse masks. Without changing any training hyperparameters, replacing dense layers with Sparse-IFT leads to significant improvements across computer vision (CV) and natural language processing (NLP) tasks, including ResNet-18 on ImageNet (+3.5%) and GPT-3 Small on WikiText-103 (-0.4 PPL), both matching larger dense model variants that use 2x or more FLOPs. To our knowledge, this is the first work to demonstrate the use of sparsity for improving the accuracy of dense models via a simple-to-use set of sparse transformations. Code is available at: https://github.com/CerebrasResearch/Sparse-IFT.
SPDF: Sparse Pre-training and Dense Fine-tuning for Large Language Models
Mar 18, 2023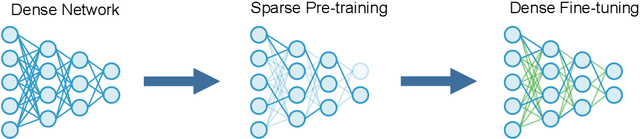
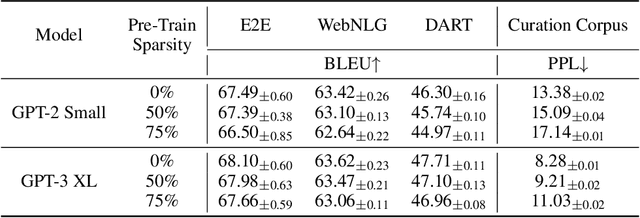
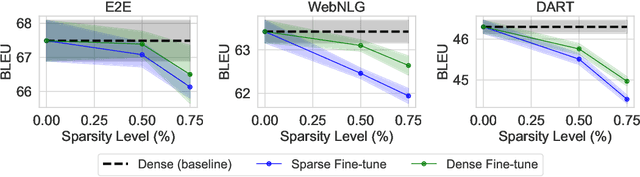
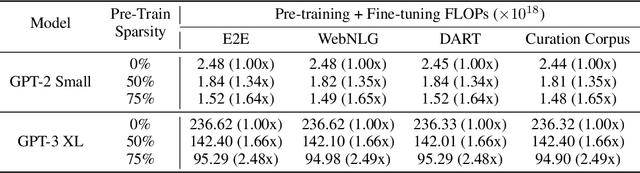
The pre-training and fine-tuning paradigm has contributed to a number of breakthroughs in Natural Language Processing (NLP). Instead of directly training on a downstream task, language models are first pre-trained on large datasets with cross-domain knowledge (e.g., Pile, MassiveText, etc.) and then fine-tuned on task-specific data (e.g., natural language generation, text summarization, etc.). Scaling the model and dataset size has helped improve the performance of LLMs, but unfortunately, this also leads to highly prohibitive computational costs. Pre-training LLMs often require orders of magnitude more FLOPs than fine-tuning and the model capacity often remains the same between the two phases. To achieve training efficiency w.r.t training FLOPs, we propose to decouple the model capacity between the two phases and introduce Sparse Pre-training and Dense Fine-tuning (SPDF). In this work, we show the benefits of using unstructured weight sparsity to train only a subset of weights during pre-training (Sparse Pre-training) and then recover the representational capacity by allowing the zeroed weights to learn (Dense Fine-tuning). We demonstrate that we can induce up to 75% sparsity into a 1.3B parameter GPT-3 XL model resulting in a 2.5x reduction in pre-training FLOPs, without a significant loss in accuracy on the downstream tasks relative to the dense baseline. By rigorously evaluating multiple downstream tasks, we also establish a relationship between sparsity, task complexity, and dataset size. Our work presents a promising direction to train large GPT models at a fraction of the training FLOPs using weight sparsity while retaining the benefits of pre-trained textual representations for downstream tasks.
RevBiFPN: The Fully Reversible Bidirectional Feature Pyramid Network
Jun 28, 2022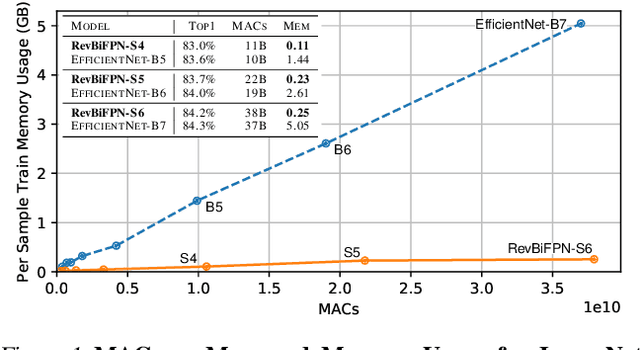
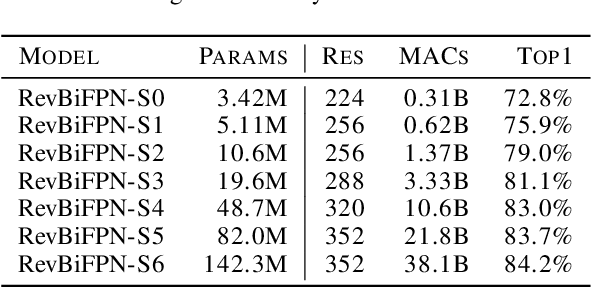
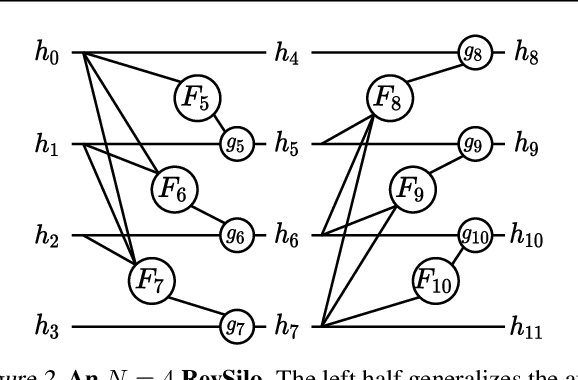

This work introduces the RevSilo, the first reversible module for bidirectional multi-scale feature fusion. Like other reversible methods, RevSilo eliminates the need to store hidden activations by recomputing them. Existing reversible methods, however, do not apply to multi-scale feature fusion and are therefore not applicable to a large class of networks. Bidirectional multi-scale feature fusion promotes local and global coherence and has become a de facto design principle for networks targeting spatially sensitive tasks e.g. HRNet and EfficientDet. When paired with high-resolution inputs, these networks achieve state-of-the-art results across various computer vision tasks, but training them requires substantial accelerator memory for saving large, multi-resolution activations. These memory requirements cap network size and limit progress. Using reversible recomputation, the RevSilo alleviates memory issues while still operating across resolution scales. Stacking RevSilos, we create RevBiFPN, a fully reversible bidirectional feature pyramid network. For classification, RevBiFPN is competitive with networks such as EfficientNet while using up to 19.8x lesser training memory. When fine-tuned on COCO, RevBiFPN provides up to a 2.5% boost in AP over HRNet using fewer MACs and a 2.4x reduction in training-time memory.
Memory Efficient 3D U-Net with Reversible Mobile Inverted Bottlenecks for Brain Tumor Segmentation
Apr 21, 2021

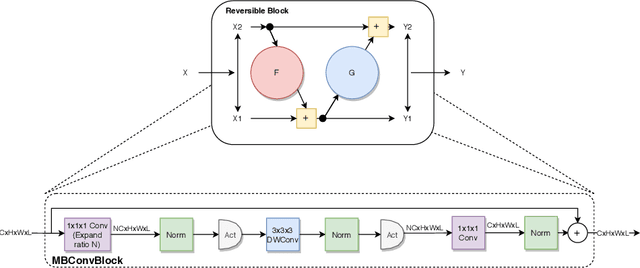
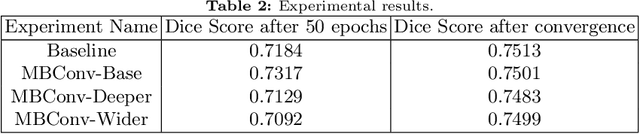
We propose combining memory saving techniques with traditional U-Net architectures to increase the complexity of the models on the Brain Tumor Segmentation (BraTS) challenge. The BraTS challenge consists of a 3D segmentation of a 240x240x155x4 input image into a set of tumor classes. Because of the large volume and need for 3D convolutional layers, this task is very memory intensive. To address this, prior approaches use smaller cropped images while constraining the model's depth and width. Our 3D U-Net uses a reversible version of the mobile inverted bottleneck block defined in MobileNetV2, MnasNet and the more recent EfficientNet architectures to save activation memory during training. Using reversible layers enables the model to recompute input activations given the outputs of that layer, saving memory by eliminating the need to store activations during the forward pass. The inverted residual bottleneck block uses lightweight depthwise separable convolutions to reduce computation by decomposing convolutions into a pointwise convolution and a depthwise convolution. Further, this block inverts traditional bottleneck blocks by placing an intermediate expansion layer between the input and output linear 1x1 convolution, reducing the total number of channels. Given a fixed memory budget, with these memory saving techniques, we are able to train image volumes up to 3x larger, models with 25% more depth, or models with up to 2x the number of channels than a corresponding non-reversible network.
* 11 pages, 5 figures, Published at MICCAI Brainles 2020
Enabling Continual Learning with Differentiable Hebbian Plasticity
Jun 30, 2020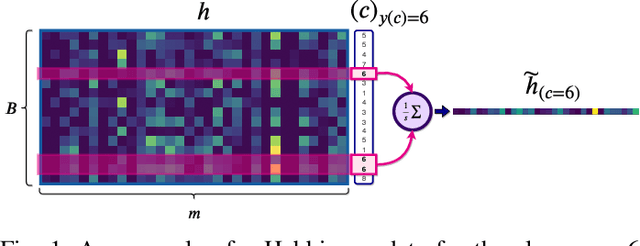
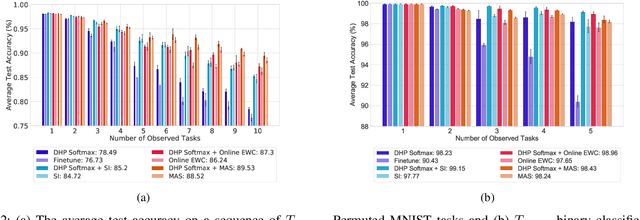
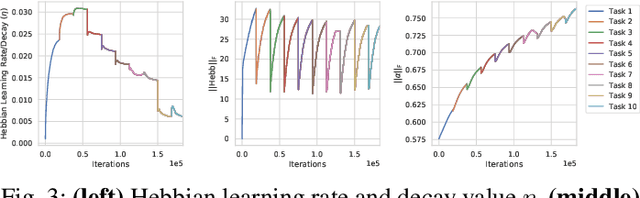
Continual learning is the problem of sequentially learning new tasks or knowledge while protecting previously acquired knowledge. However, catastrophic forgetting poses a grand challenge for neural networks performing such learning process. Thus, neural networks that are deployed in the real world often struggle in scenarios where the data distribution is non-stationary (concept drift), imbalanced, or not always fully available, i.e., rare edge cases. We propose a Differentiable Hebbian Consolidation model which is composed of a Differentiable Hebbian Plasticity (DHP) Softmax layer that adds a rapid learning plastic component (compressed episodic memory) to the fixed (slow changing) parameters of the softmax output layer; enabling learned representations to be retained for a longer timescale. We demonstrate the flexibility of our method by integrating well-known task-specific synaptic consolidation methods to penalize changes in the slow weights that are important for each target task. We evaluate our approach on the Permuted MNIST, Split MNIST and Vision Datasets Mixture benchmarks, and introduce an imbalanced variant of Permuted MNIST -- a dataset that combines the challenges of class imbalance and concept drift. Our proposed model requires no additional hyperparameters and outperforms comparable baselines by reducing forgetting.
Self-Paced Learning with Adaptive Deep Visual Embeddings
Jul 24, 2018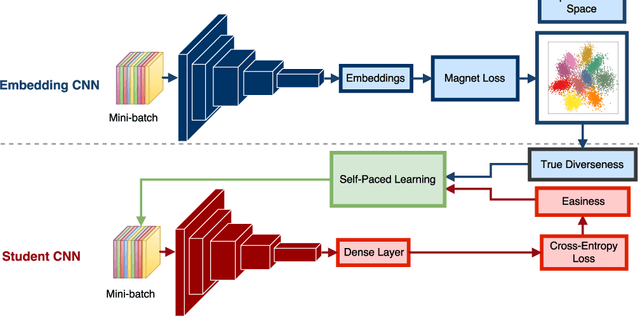

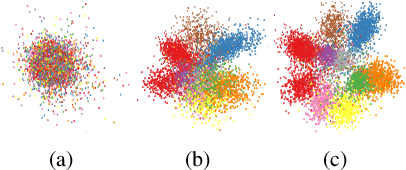
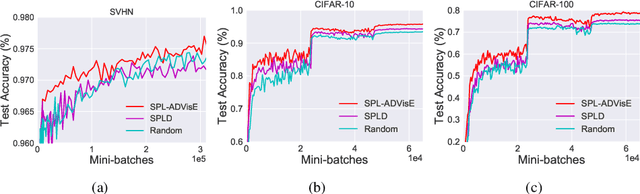
Selecting the most appropriate data examples to present a deep neural network (DNN) at different stages of training is an unsolved challenge. Though practitioners typically ignore this problem, a non-trivial data scheduling method may result in a significant improvement in both convergence and generalization performance. In this paper, we introduce Self-Paced Learning with Adaptive Deep Visual Embeddings (SPL-ADVisE), a novel end-to-end training protocol that unites self-paced learning (SPL) and deep metric learning (DML). We leverage the Magnet Loss to train an embedding convolutional neural network (CNN) to learn a salient representation space. The student CNN classifier dynamically selects similar instance-level training examples to form a mini-batch, where the easiness from the cross-entropy loss and the true diverseness of examples from the learned metric space serve as sample importance priors. To demonstrate the effectiveness of SPL-ADVisE, we use deep CNN architectures for the task of supervised image classification on several coarse- and fine-grained visual recognition datasets. Results show that, across all datasets, the proposed method converges faster and reaches a higher final accuracy than other SPL variants, particularly on fine-grained classes.