 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJakob Foerster
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
Apr 15, 2024
This work identifies 18 foundational challenges in assuring the alignment and safety of large language models (LLMs). These challenges are organized into three different categories: scientific understanding of LLMs, development and deployment methods, and sociotechnical challenges. Based on the identified challenges, we pose $200+$ concrete research questions.
Rethinking Out-of-Distribution Detection for Reinforcement Learning: Advancing Methods for Evaluation and Detection
Apr 10, 2024While reinforcement learning (RL) algorithms have been successfully applied across numerous sequential decision-making problems, their generalization to unforeseen testing environments remains a significant concern. In this paper, we study the problem of out-of-distribution (OOD) detection in RL, which focuses on identifying situations at test time that RL agents have not encountered in their training environments. We first propose a clarification of terminology for OOD detection in RL, which aligns it with the literature from other machine learning domains. We then present new benchmark scenarios for OOD detection, which introduce anomalies with temporal autocorrelation into different components of the agent-environment loop. We argue that such scenarios have been understudied in the current literature, despite their relevance to real-world situations. Confirming our theoretical predictions, our experimental results suggest that state-of-the-art OOD detectors are not able to identify such anomalies. To address this problem, we propose a novel method for OOD detection, which we call DEXTER (Detection via Extraction of Time Series Representations). By treating environment observations as time series data, DEXTER extracts salient time series features, and then leverages an ensemble of isolation forest algorithms to detect anomalies. We find that DEXTER can reliably identify anomalies across benchmark scenarios, exhibiting superior performance compared to both state-of-the-art OOD detectors and high-dimensional changepoint detectors adopted from statistics.
Policy-Guided Diffusion
Apr 09, 2024In many real-world settings, agents must learn from an offline dataset gathered by some prior behavior policy. Such a setting naturally leads to distribution shift between the behavior policy and the target policy being trained - requiring policy conservatism to avoid instability and overestimation bias. Autoregressive world models offer a different solution to this by generating synthetic, on-policy experience. However, in practice, model rollouts must be severely truncated to avoid compounding error. As an alternative, we propose policy-guided diffusion. Our method uses diffusion models to generate entire trajectories under the behavior distribution, applying guidance from the target policy to move synthetic experience further on-policy. We show that policy-guided diffusion models a regularized form of the target distribution that balances action likelihood under both the target and behavior policies, leading to plausible trajectories with high target policy probability, while retaining a lower dynamics error than an offline world model baseline. Using synthetic experience from policy-guided diffusion as a drop-in substitute for real data, we demonstrate significant improvements in performance across a range of standard offline reinforcement learning algorithms and environments. Our approach provides an effective alternative to autoregressive offline world models, opening the door to the controllable generation of synthetic training data.
JaxUED: A simple and useable UED library in Jax
Mar 19, 2024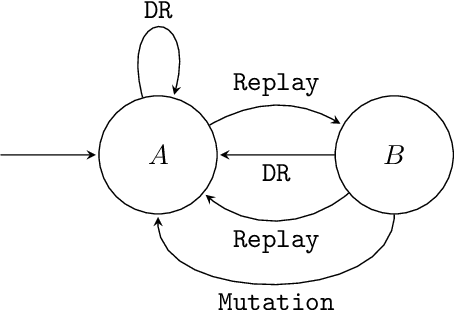
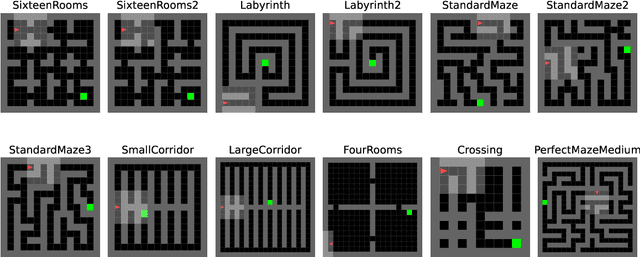

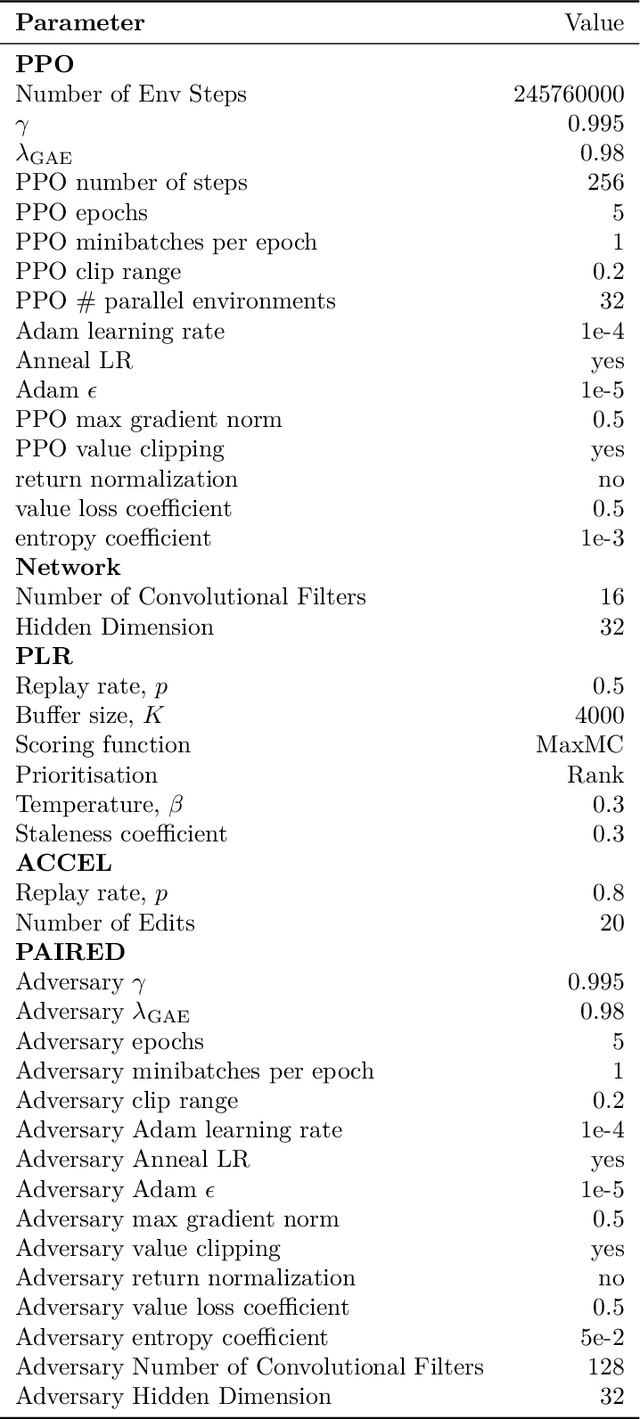
We present JaxUED, an open-source library providing minimal dependency implementations of modern Unsupervised Environment Design (UED) algorithms in Jax. JaxUED leverages hardware acceleration to obtain on the order of 100x speedups compared to prior, CPU-based implementations. Inspired by CleanRL, we provide fast, clear, understandable, and easily modifiable implementations, with the aim of accelerating research into UED. This paper describes our library and contains baseline results. Code can be found at https://github.com/DramaCow/jaxued.
Craftax: A Lightning-Fast Benchmark for Open-Ended Reinforcement Learning
Feb 26, 2024Benchmarks play a crucial role in the development and analysis of reinforcement learning (RL) algorithms. We identify that existing benchmarks used for research into open-ended learning fall into one of two categories. Either they are too slow for meaningful research to be performed without enormous computational resources, like Crafter, NetHack and Minecraft, or they are not complex enough to pose a significant challenge, like Minigrid and Procgen. To remedy this, we first present Craftax-Classic: a ground-up rewrite of Crafter in JAX that runs up to 250x faster than the Python-native original. A run of PPO using 1 billion environment interactions finishes in under an hour using only a single GPU and averages 90% of the optimal reward. To provide a more compelling challenge we present the main Craftax benchmark, a significant extension of the Crafter mechanics with elements inspired from NetHack. Solving Craftax requires deep exploration, long term planning and memory, as well as continual adaptation to novel situations as more of the world is discovered. We show that existing methods including global and episodic exploration, as well as unsupervised environment design fail to make material progress on the benchmark. We believe that Craftax can for the first time allow researchers to experiment in a complex, open-ended environment with limited computational resources.
Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts
Feb 26, 2024As large language models (LLMs) become increasingly prevalent across many real-world applications, understanding and enhancing their robustness to user inputs is of paramount importance. Existing methods for identifying adversarial prompts tend to focus on specific domains, lack diversity, or require extensive human annotations. To address these limitations, we present Rainbow Teaming, a novel approach for producing a diverse collection of adversarial prompts. Rainbow Teaming casts adversarial prompt generation as a quality-diversity problem, and uses open-ended search to generate prompts that are both effective and diverse. It can uncover a model's vulnerabilities across a broad range of domains including, in this paper, safety, question answering, and cybersecurity. We also demonstrate that fine-tuning on synthetic data generated by Rainbow Teaming improves the safety of state-of-the-art LLMs without hurting their general capabilities and helpfulness, paving the path to open-ended self-improvement.
Refining Minimax Regret for Unsupervised Environment Design
Feb 19, 2024In unsupervised environment design, reinforcement learning agents are trained on environment configurations (levels) generated by an adversary that maximises some objective. Regret is a commonly used objective that theoretically results in a minimax regret (MMR) policy with desirable robustness guarantees; in particular, the agent's maximum regret is bounded. However, once the agent reaches this regret bound on all levels, the adversary will only sample levels where regret cannot be further reduced. Although there are possible performance improvements to be made outside of these regret-maximising levels, learning stagnates. In this work, we introduce Bayesian level-perfect MMR (BLP), a refinement of the minimax regret objective that overcomes this limitation. We formally show that solving for this objective results in a subset of MMR policies, and that BLP policies act consistently with a Perfect Bayesian policy over all levels. We further introduce an algorithm, ReMiDi, that results in a BLP policy at convergence. We empirically demonstrate that training on levels from a minimax regret adversary causes learning to prematurely stagnate, but that ReMiDi continues learning.
Revisiting Recurrent Reinforcement Learning with Memory Monoids
Feb 15, 2024In RL, memory models such as RNNs and transformers address Partially Observable Markov Decision Processes (POMDPs) by mapping trajectories to latent Markov states. Neither model scales particularly well to long sequences, especially compared to an emerging class of memory models sometimes called linear recurrent models. We discover that the recurrent update of these models is a monoid, leading us to formally define a novel memory monoid framework. We revisit the traditional approach to batching in recurrent RL, highlighting both theoretical and empirical deficiencies. Leveraging the properties of memory monoids, we propose a new batching method that improves sample efficiency, increases the return, and simplifies the implementation of recurrent loss functions in RL.
Symmetry-Breaking Augmentations for Ad Hoc Teamwork
Feb 15, 2024In many collaborative settings, artificial intelligence (AI) agents must be able to adapt to new teammates that use unknown or previously unobserved strategies. While often simple for humans, this can be challenging for AI agents. For example, if an AI agent learns to drive alongside others (a training set) that only drive on one side of the road, it may struggle to adapt this experience to coordinate with drivers on the opposite side, even if their behaviours are simply flipped along the left-right symmetry. To address this we introduce symmetry-breaking augmentations (SBA), which increases diversity in the behaviour of training teammates by applying a symmetry-flipping operation. By learning a best-response to the augmented set of teammates, our agent is exposed to a wider range of behavioural conventions, improving performance when deployed with novel teammates. We demonstrate this experimentally in two settings, and show that our approach improves upon previous ad hoc teamwork results in the challenging card game Hanabi. We also propose a general metric for estimating symmetry-dependency amongst a given set of policies.
Mixtures of Experts Unlock Parameter Scaling for Deep RL
Feb 13, 2024The recent rapid progress in (self) supervised learning models is in large part predicted by empirical scaling laws: a model's performance scales proportionally to its size. Analogous scaling laws remain elusive for reinforcement learning domains, however, where increasing the parameter count of a model often hurts its final performance. In this paper, we demonstrate that incorporating Mixture-of-Expert (MoE) modules, and in particular Soft MoEs (Puigcerver et al., 2023), into value-based networks results in more parameter-scalable models, evidenced by substantial performance increases across a variety of training regimes and model sizes. This work thus provides strong empirical evidence towards developing scaling laws for reinforcement learning.