 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoshua Bengio
Towards DNA-Encoded Library Generation with GFlowNets
Apr 15, 2024
DNA-encoded libraries (DELs) are a powerful approach for rapidly screening large numbers of diverse compounds. One of the key challenges in using DELs is library design, which involves choosing the building blocks that will be combinatorially combined to produce the final library. In this paper we consider the task of protein-protein interaction (PPI) biased DEL design. To this end, we evaluate several machine learning algorithms on the PPI modulation task and use them as a reward for the proposed GFlowNet-based generative approach. We additionally investigate the possibility of using structural information about building blocks to design a hierarchical action space for the GFlowNet. The observed results indicate that GFlowNets are a promising approach for generating diverse combinatorial library candidates.
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
Apr 15, 2024This work identifies 18 foundational challenges in assuring the alignment and safety of large language models (LLMs). These challenges are organized into three different categories: scientific understanding of LLMs, development and deployment methods, and sociotechnical challenges. Based on the identified challenges, we pose $200+$ concrete research questions.
Language Models Can Reduce Asymmetry in Information Markets
Mar 21, 2024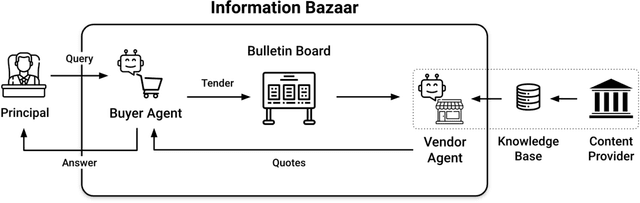

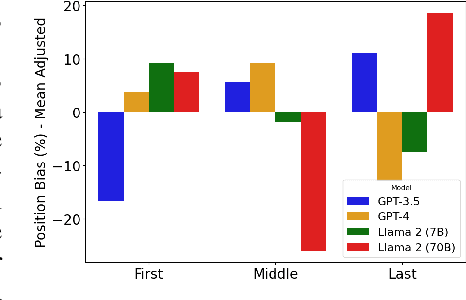
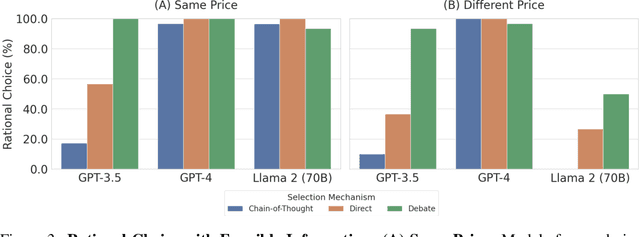
This work addresses the buyer's inspection paradox for information markets. The paradox is that buyers need to access information to determine its value, while sellers need to limit access to prevent theft. To study this, we introduce an open-source simulated digital marketplace where intelligent agents, powered by language models, buy and sell information on behalf of external participants. The central mechanism enabling this marketplace is the agents' dual capabilities: they not only have the capacity to assess the quality of privileged information but also come equipped with the ability to forget. This ability to induce amnesia allows vendors to grant temporary access to proprietary information, significantly reducing the risk of unauthorized retention while enabling agents to accurately gauge the information's relevance to specific queries or tasks. To perform well, agents must make rational decisions, strategically explore the marketplace through generated sub-queries, and synthesize answers from purchased information. Concretely, our experiments (a) uncover biases in language models leading to irrational behavior and evaluate techniques to mitigate these biases, (b) investigate how price affects demand in the context of informational goods, and (c) show that inspection and higher budgets both lead to higher quality outcomes.
Ant Colony Sampling with GFlowNets for Combinatorial Optimization
Mar 11, 2024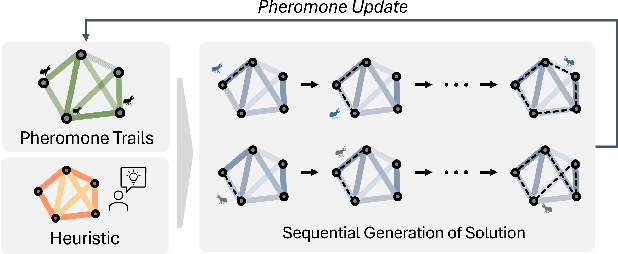
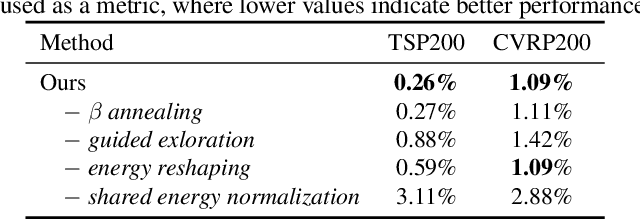
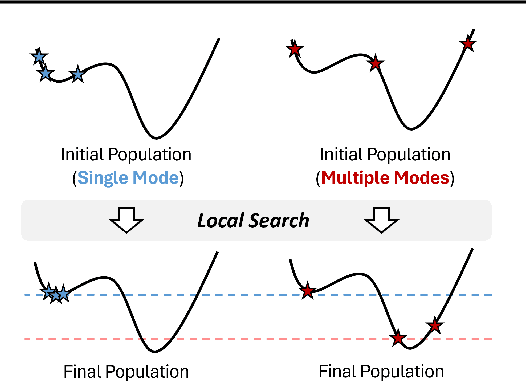
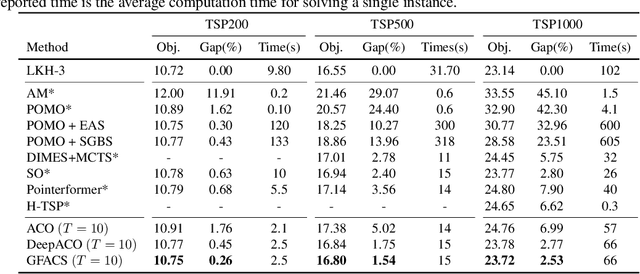
This paper introduces the Generative Flow Ant Colony Sampler (GFACS), a novel neural-guided meta-heuristic algorithm for combinatorial optimization. GFACS integrates generative flow networks (GFlowNets) with the ant colony optimization (ACO) methodology. GFlowNets, a generative model that learns a constructive policy in combinatorial spaces, enhance ACO by providing an informed prior distribution of decision variables conditioned on input graph instances. Furthermore, we introduce a novel combination of training tricks, including search-guided local exploration, energy normalization, and energy shaping to improve GFACS. Our experimental results demonstrate that GFACS outperforms baseline ACO algorithms in seven CO tasks and is competitive with problem-specific heuristics for vehicle routing problems. The source code is available at \url{https://github.com/ai4co/gfacs}.
Machine learning and information theory concepts towards an AI Mathematician
Mar 07, 2024The current state-of-the-art in artificial intelligence is impressive, especially in terms of mastery of language, but not so much in terms of mathematical reasoning. What could be missing? Can we learn something useful about that gap from how the brains of mathematicians go about their craft? This essay builds on the idea that current deep learning mostly succeeds at system 1 abilities -- which correspond to our intuition and habitual behaviors -- but still lacks something important regarding system 2 abilities -- which include reasoning and robust uncertainty estimation. It takes an information-theoretical posture to ask questions about what constitutes an interesting mathematical statement, which could guide future work in crafting an AI mathematician. The focus is not on proving a given theorem but on discovering new and interesting conjectures. The central hypothesis is that a desirable body of theorems better summarizes the set of all provable statements, for example by having a small description length while at the same time being close (in terms of number of derivation steps) to many provable statements.
Discrete Probabilistic Inference as Control in Multi-path Environments
Feb 15, 2024We consider the problem of sampling from a discrete and structured distribution as a sequential decision problem, where the objective is to find a stochastic policy such that objects are sampled at the end of this sequential process proportionally to some predefined reward. While we could use maximum entropy Reinforcement Learning (MaxEnt RL) to solve this problem for some distributions, it has been shown that in general, the distribution over states induced by the optimal policy may be biased in cases where there are multiple ways to generate the same object. To address this issue, Generative Flow Networks (GFlowNets) learn a stochastic policy that samples objects proportionally to their reward by approximately enforcing a conservation of flows across the whole Markov Decision Process (MDP). In this paper, we extend recent methods correcting the reward in order to guarantee that the marginal distribution induced by the optimal MaxEnt RL policy is proportional to the original reward, regardless of the structure of the underlying MDP. We also prove that some flow-matching objectives found in the GFlowNet literature are in fact equivalent to well-established MaxEnt RL algorithms with a corrected reward. Finally, we study empirically the performance of multiple MaxEnt RL and GFlowNet algorithms on multiple problems involving sampling from discrete distributions.
On diffusion models for amortized inference: Benchmarking and improving stochastic control and sampling
Feb 13, 2024We study the problem of training diffusion models to sample from a distribution with a given unnormalized density or energy function. We benchmark several diffusion-structured inference methods, including simulation-based variational approaches and off-policy methods (continuous generative flow networks). Our results shed light on the relative advantages of existing algorithms while bringing into question some claims from past work. We also propose a novel exploration strategy for off-policy methods, based on local search in the target space with the use of a replay buffer, and show that it improves the quality of samples on a variety of target distributions. Our code for the sampling methods and benchmarks studied is made public at https://github.com/GFNOrg/gfn-diffusion as a base for future work on diffusion models for amortized inference.
Iterated Denoising Energy Matching for Sampling from Boltzmann Densities
Feb 09, 2024Efficiently generating statistically independent samples from an unnormalized probability distribution, such as equilibrium samples of many-body systems, is a foundational problem in science. In this paper, we propose Iterated Denoising Energy Matching (iDEM), an iterative algorithm that uses a novel stochastic score matching objective leveraging solely the energy function and its gradient -- and no data samples -- to train a diffusion-based sampler. Specifically, iDEM alternates between (I) sampling regions of high model density from a diffusion-based sampler and (II) using these samples in our stochastic matching objective to further improve the sampler. iDEM is scalable to high dimensions as the inner matching objective, is simulation-free, and requires no MCMC samples. Moreover, by leveraging the fast mode mixing behavior of diffusion, iDEM smooths out the energy landscape enabling efficient exploration and learning of an amortized sampler. We evaluate iDEM on a suite of tasks ranging from standard synthetic energy functions to invariant $n$-body particle systems. We show that the proposed approach achieves state-of-the-art performance on all metrics and trains $2-5\times$ faster, which allows it to be the first method to train using energy on the challenging $55$-particle Lennard-Jones system.
Efficient Causal Graph Discovery Using Large Language Models
Feb 05, 2024We propose a novel framework that leverages LLMs for full causal graph discovery. While previous LLM-based methods have used a pairwise query approach, this requires a quadratic number of queries which quickly becomes impractical for larger causal graphs. In contrast, the proposed framework uses a breadth-first search (BFS) approach which allows it to use only a linear number of queries. We also show that the proposed method can easily incorporate observational data when available, to improve performance. In addition to being more time and data-efficient, the proposed framework achieves state-of-the-art results on real-world causal graphs of varying sizes. The results demonstrate the effectiveness and efficiency of the proposed method in discovering causal relationships, showcasing its potential for broad applicability in causal graph discovery tasks across different domains.