 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMichał Koziarski
Towards DNA-Encoded Library Generation with GFlowNets
Apr 15, 2024
DNA-encoded libraries (DELs) are a powerful approach for rapidly screening large numbers of diverse compounds. One of the key challenges in using DELs is library design, which involves choosing the building blocks that will be combinatorially combined to produce the final library. In this paper we consider the task of protein-protein interaction (PPI) biased DEL design. To this end, we evaluate several machine learning algorithms on the PPI modulation task and use them as a reward for the proposed GFlowNet-based generative approach. We additionally investigate the possibility of using structural information about building blocks to design a hierarchical action space for the GFlowNet. The observed results indicate that GFlowNets are a promising approach for generating diverse combinatorial library candidates.
Towards equilibrium molecular conformation generation with GFlowNets
Oct 20, 2023Sampling diverse, thermodynamically feasible molecular conformations plays a crucial role in predicting properties of a molecule. In this paper we propose to use GFlowNet for sampling conformations of small molecules from the Boltzmann distribution, as determined by the molecule's energy. The proposed approach can be used in combination with energy estimation methods of different fidelity and discovers a diverse set of low-energy conformations for highly flexible drug-like molecules. We demonstrate that GFlowNet can reproduce molecular potential energy surfaces by sampling proportionally to the Boltzmann distribution.
Towards Foundational Models for Molecular Learning on Large-Scale Multi-Task Datasets
Oct 18, 2023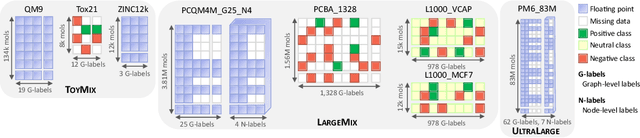
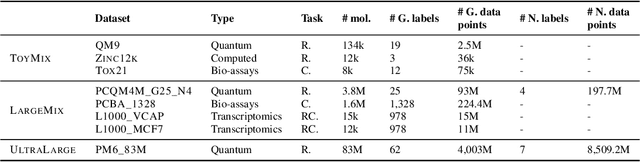
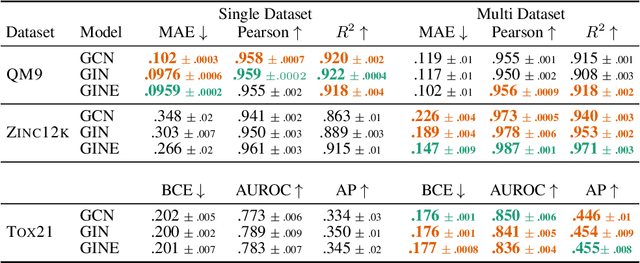
Recently, pre-trained foundation models have enabled significant advancements in multiple fields. In molecular machine learning, however, where datasets are often hand-curated, and hence typically small, the lack of datasets with labeled features, and codebases to manage those datasets, has hindered the development of foundation models. In this work, we present seven novel datasets categorized by size into three distinct categories: ToyMix, LargeMix and UltraLarge. These datasets push the boundaries in both the scale and the diversity of supervised labels for molecular learning. They cover nearly 100 million molecules and over 3000 sparsely defined tasks, totaling more than 13 billion individual labels of both quantum and biological nature. In comparison, our datasets contain 300 times more data points than the widely used OGB-LSC PCQM4Mv2 dataset, and 13 times more than the quantum-only QM1B dataset. In addition, to support the development of foundational models based on our proposed datasets, we present the Graphium graph machine learning library which simplifies the process of building and training molecular machine learning models for multi-task and multi-level molecular datasets. Finally, we present a range of baseline results as a starting point of multi-task and multi-level training on these datasets. Empirically, we observe that performance on low-resource biological datasets show improvement by also training on large amounts of quantum data. This indicates that there may be potential in multi-task and multi-level training of a foundation model and fine-tuning it to resource-constrained downstream tasks.
Crystal-GFN: sampling crystals with desirable properties and constraints
Oct 07, 2023Accelerating material discovery holds the potential to greatly help mitigate the climate crisis. Discovering new solid-state crystals such as electrocatalysts, ionic conductors or photovoltaics can have a crucial impact, for instance, in improving the efficiency of renewable energy production and storage. In this paper, we introduce Crystal-GFlowNet, a generative model of crystal structures that sequentially samples a crystal's composition, space group and lattice parameters. This domain-inspired approach enables the flexible incorporation of physical and geometrical constraints, as well as the use of any available predictive model of a desired property as an objective function. We evaluate the capabilities of Crystal-GFlowNet by using as objective the formation energy of a crystal structure, as predicted by a new proxy model trained on MatBench. The results demonstrate that Crystal-GFlowNet is able to sample diverse crystals with low formation energy.
ChiENN: Embracing Molecular Chirality with Graph Neural Networks
Jul 10, 2023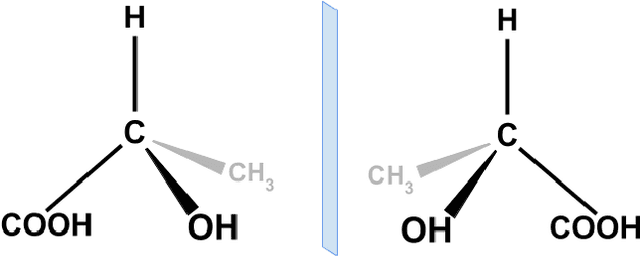
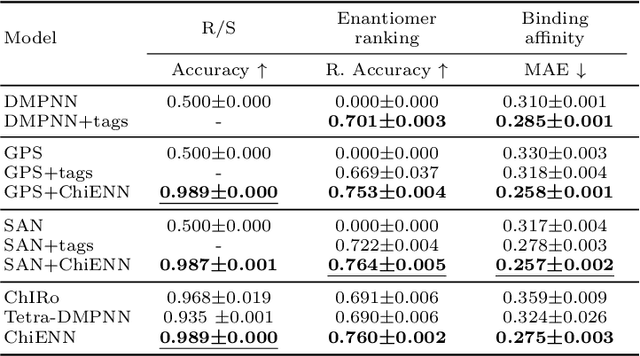
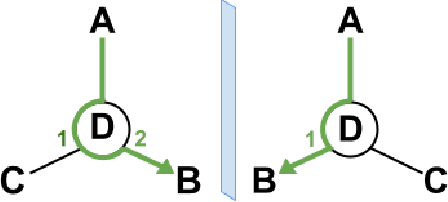
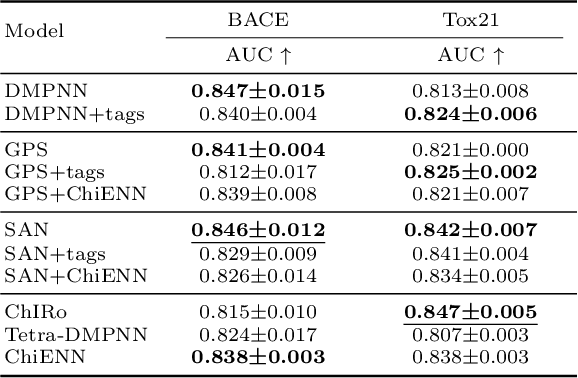
Graph Neural Networks (GNNs) play a fundamental role in many deep learning problems, in particular in cheminformatics. However, typical GNNs cannot capture the concept of chirality, which means they do not distinguish between the 3D graph of a chemical compound and its mirror image (enantiomer). The ability to distinguish between enantiomers is important especially in drug discovery because enantiomers can have very distinct biochemical properties. In this paper, we propose a theoretically justified message-passing scheme, which makes GNNs sensitive to the order of node neighbors. We apply that general concept in the context of molecular chirality to construct Chiral Edge Neural Network (ChiENN) layer which can be appended to any GNN model to enable chirality-awareness. Our experiments show that adding ChiENN layers to a GNN outperforms current state-of-the-art methods in chiral-sensitive molecular property prediction tasks.
Imbalanced data preprocessing techniques utilizing local data characteristics
Nov 28, 2021
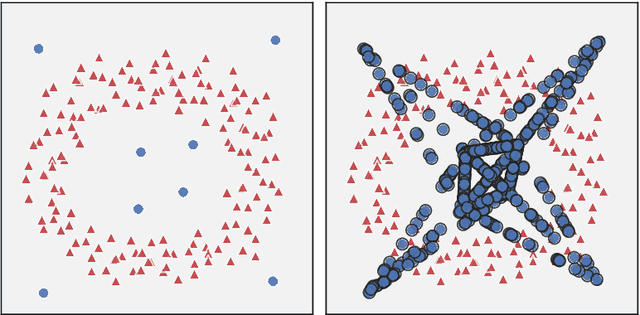
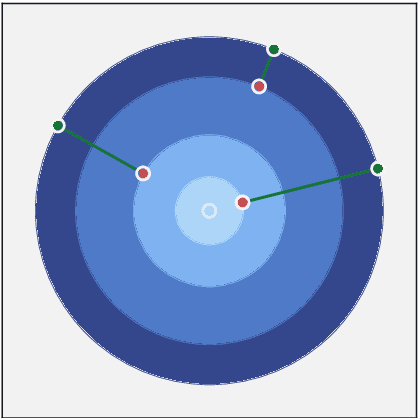
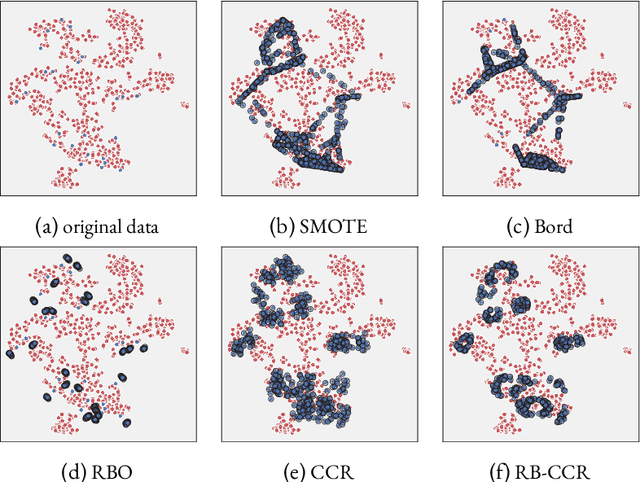
Data imbalance, that is the disproportion between the number of training observations coming from different classes, remains one of the most significant challenges affecting contemporary machine learning. The negative impact of data imbalance on traditional classification algorithms can be reduced by the data preprocessing techniques, methods that manipulate the training data to artificially reduce the degree of imbalance. However, the existing data preprocessing techniques, in particular SMOTE and its derivatives, which constitute the most prevalent paradigm of imbalanced data preprocessing, tend to be susceptible to various data difficulty factors. This is in part due to the fact that the original SMOTE algorithm does not utilize the information about majority class observations. The focus of this thesis is development of novel data resampling strategies natively utilizing the information about the distribution of both minority and majority class. The thesis summarizes the content of 12 research papers focused on the proposed binary data resampling strategies, their translation to the multi-class setting, and the practical application to the problem of histopathological data classification.
DiagSet: a dataset for prostate cancer histopathological image classification
May 09, 2021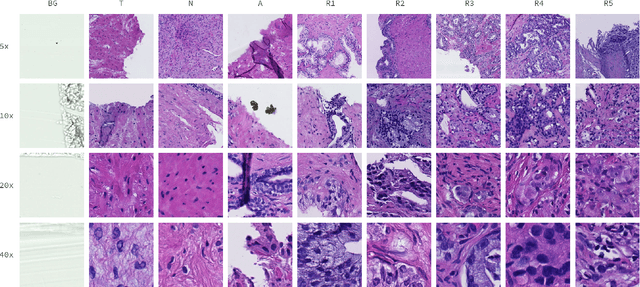

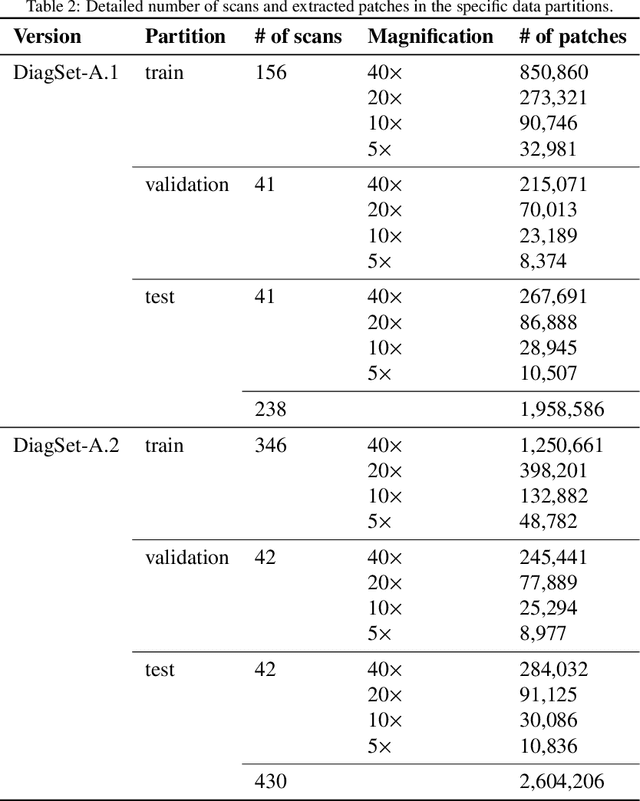
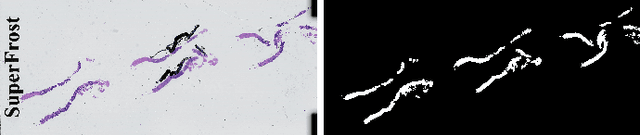
Cancer diseases constitute one of the most significant societal challenges. In this paper we introduce a novel histopathological dataset for prostate cancer detection. The proposed dataset, consisting of over 2.6 million tissue patches extracted from 430 fully annotated scans, 4675 scans with assigned binary diagnosis, and 46 scans with diagnosis given independently by a group of histopathologists, can be found at https://ai-econsilio.diag.pl. Furthermore, we propose a machine learning framework for detection of cancerous tissue regions and prediction of scan-level diagnosis, utilizing thresholding and statistical analysis to abstain from the decision in uncertain cases. During the experimental evaluation we identify several factors negatively affecting the performance of considered models, such as presence of label noise, data imbalance, and quantity of data, that can serve as a basis for further research. The proposed approach, composed of ensembles of deep neural networks operating on the histopathological scans at different scales, achieves 94.6% accuracy in patch-level recognition, and is compared in a scan-level diagnosis with 9 human histopathologists.
RB-CCR: Radial-Based Combined Cleaning and Resampling algorithm for imbalanced data classification
May 09, 2021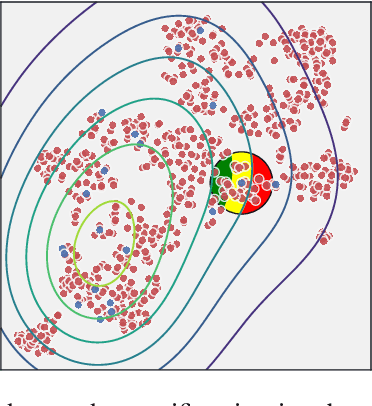
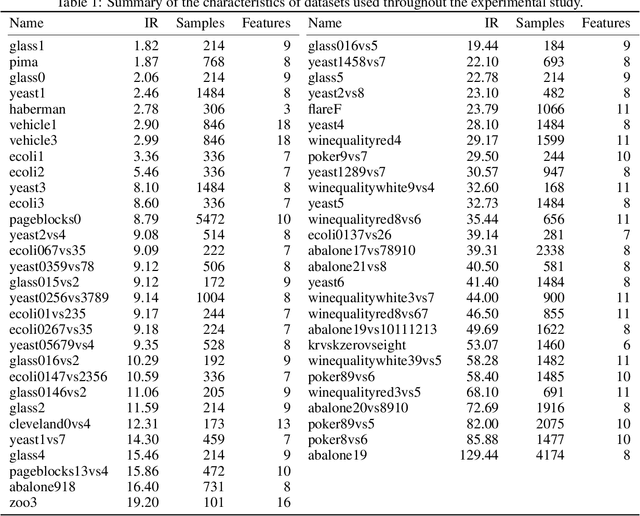
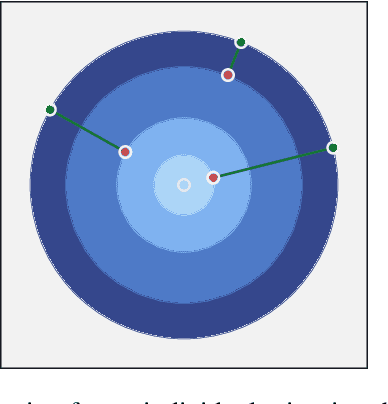
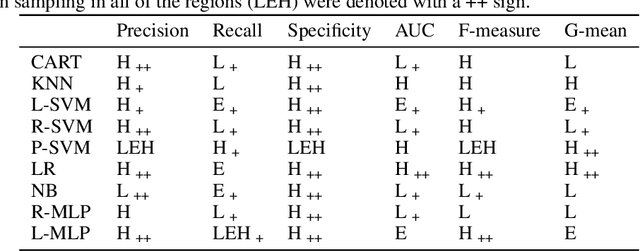
Real-world classification domains, such as medicine, health and safety, and finance, often exhibit imbalanced class priors and have asynchronous misclassification costs. In such cases, the classification model must achieve a high recall without significantly impacting precision. Resampling the training data is the standard approach to improving classification performance on imbalanced binary data. However, the state-of-the-art methods ignore the local joint distribution of the data or correct it as a post-processing step. This can causes sub-optimal shifts in the training distribution, particularly when the target data distribution is complex. In this paper, we propose Radial-Based Combined Cleaning and Resampling (RB-CCR). RB-CCR utilizes the concept of class potential to refine the energy-based resampling approach of CCR. In particular, RB-CCR exploits the class potential to accurately locate sub-regions of the data-space for synthetic oversampling. The category sub-region for oversampling can be specified as an input parameter to meet domain-specific needs or be automatically selected via cross-validation. Our $5\times2$ cross-validated results on 57 benchmark binary datasets with 9 classifiers show that RB-CCR achieves a better precision-recall trade-off than CCR and generally out-performs the state-of-the-art resampling methods in terms of AUC and G-mean.
Potential Anchoring for imbalanced data classification
Apr 17, 2021
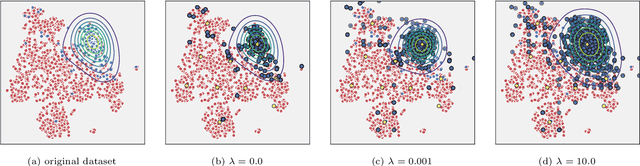


Data imbalance remains one of the factors negatively affecting the performance of contemporary machine learning algorithms. One of the most common approaches to reducing the negative impact of data imbalance is preprocessing the original dataset with data-level strategies. In this paper we propose a unified framework for imbalanced data over- and undersampling. The proposed approach utilizes radial basis functions to preserve the original shape of the underlying class distributions during the resampling process. This is done by optimizing the positions of generated synthetic observations with respect to the potential resemblance loss. The final Potential Anchoring algorithm combines over- and undersampling within the proposed framework. The results of the experiments conducted on 60 imbalanced datasets show outperformance of Potential Anchoring over state-of-the-art resampling algorithms, including previously proposed methods that utilize radial basis functions to model class potential. Furthermore, the results of the analysis based on the proposed data complexity index show that Potential Anchoring is particularly well suited for handling naturally complex (i.e. not affected by the presence of noise) datasets.
CSMOUTE: Combined Synthetic Oversampling and Undersampling Technique for Imbalanced Data Classification
Apr 07, 2020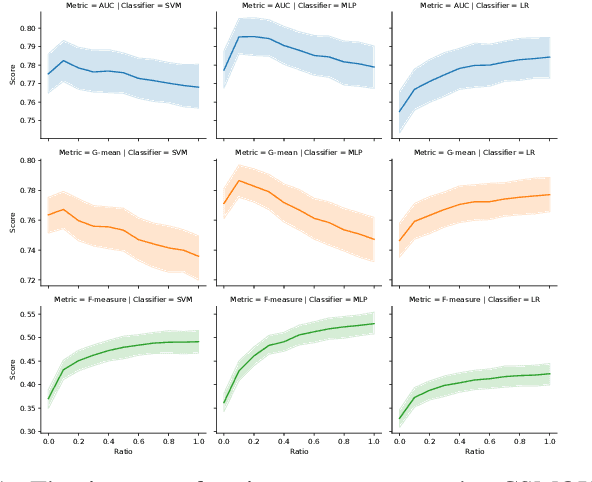
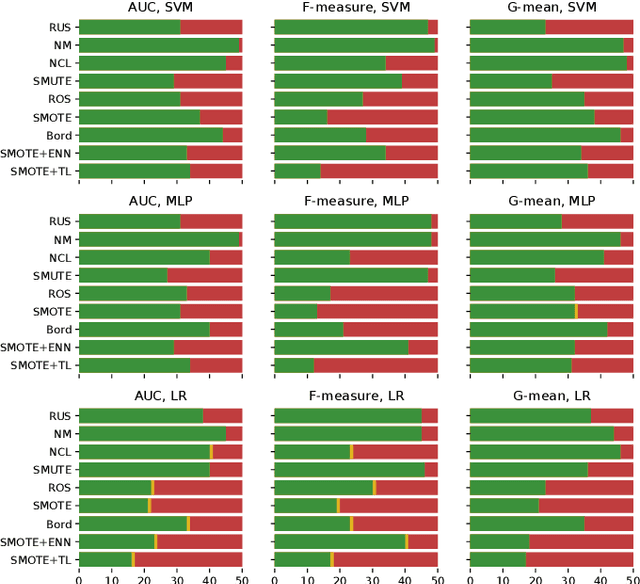
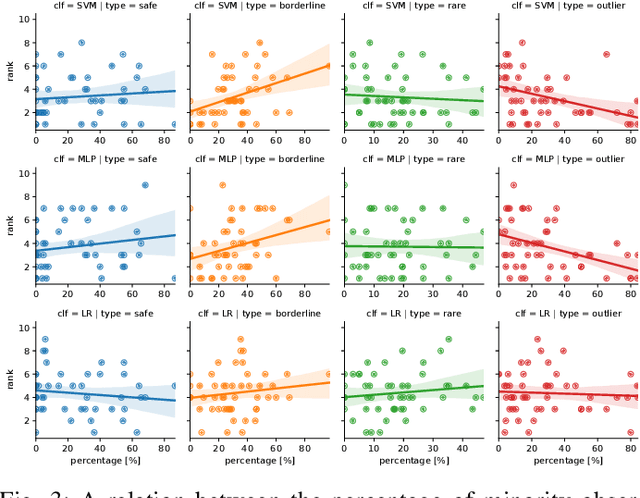
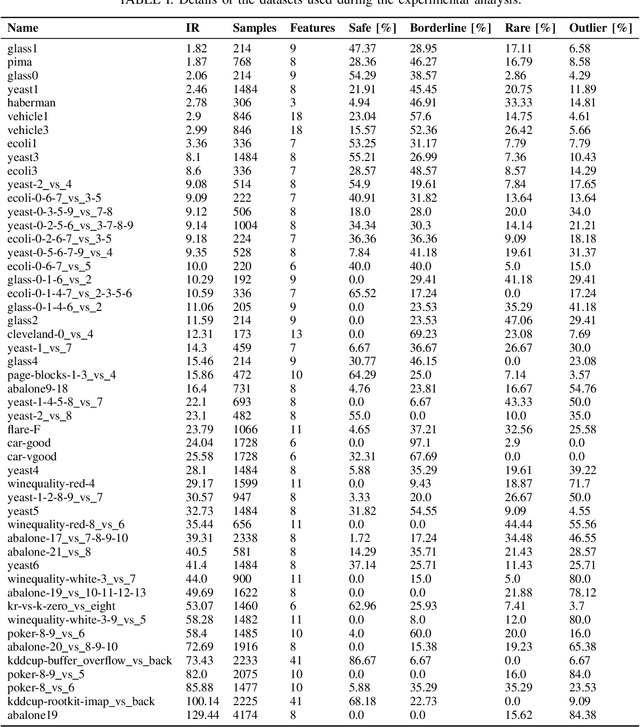
In this paper we propose two novel data-level algorithms for handling data imbalance in the classification task: first of all a Synthetic Minority Undersampling Technique (SMUTE), which leverages the concept of interpolation of nearby instances, previously introduced in the oversampling setting in SMOTE, and secondly a Combined Synthetic Oversampling and Undersampling Technique (CSMOUTE), which integrates SMOTE oversampling with SMUTE undersampling. The results of the conducted experimental study demonstrate the usefulness of both the SMUTE and the CSMOUTE algorithms, especially when combined with a more complex classifiers, namely MLP and SVM, and when applied on a datasets consisting of a large number of outliers. This leads us to a conclusion that the proposed approach shows promise for further extensions accommodating local data characteristics, a direction discussed in more detail in the paper.