 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLauro Langosco
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
Apr 15, 2024
This work identifies 18 foundational challenges in assuring the alignment and safety of large language models (LLMs). These challenges are organized into three different categories: scientific understanding of LLMs, development and deployment methods, and sociotechnical challenges. Based on the identified challenges, we pose $200+$ concrete research questions.
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Jul 27, 2023
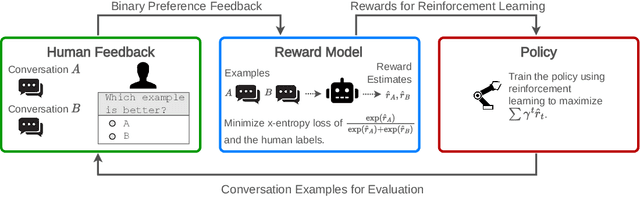
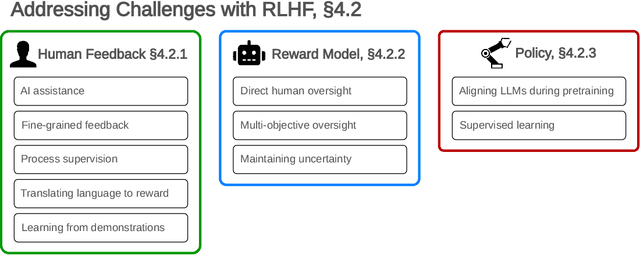
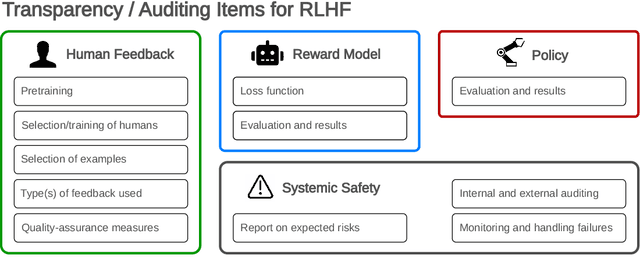
Reinforcement learning from human feedback (RLHF) is a technique for training AI systems to align with human goals. RLHF has emerged as the central method used to finetune state-of-the-art large language models (LLMs). Despite this popularity, there has been relatively little public work systematizing its flaws. In this paper, we (1) survey open problems and fundamental limitations of RLHF and related methods; (2) overview techniques to understand, improve, and complement RLHF in practice; and (3) propose auditing and disclosure standards to improve societal oversight of RLHF systems. Our work emphasizes the limitations of RLHF and highlights the importance of a multi-faceted approach to the development of safer AI systems.
Unifying Grokking and Double Descent
Mar 10, 2023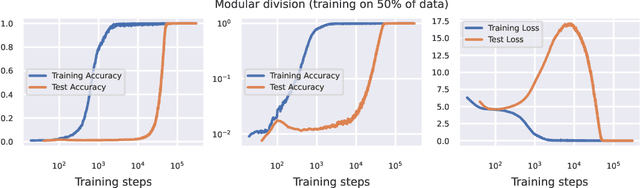


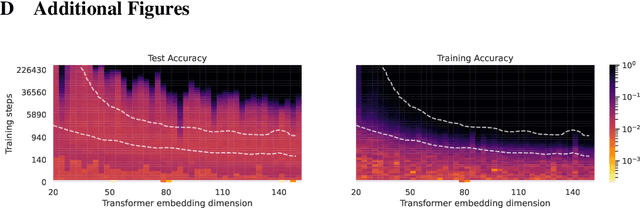
A principled understanding of generalization in deep learning may require unifying disparate observations under a single conceptual framework. Previous work has studied \emph{grokking}, a training dynamic in which a sustained period of near-perfect training performance and near-chance test performance is eventually followed by generalization, as well as the superficially similar \emph{double descent}. These topics have so far been studied in isolation. We hypothesize that grokking and double descent can be understood as instances of the same learning dynamics within a framework of pattern learning speeds. We propose that this framework also applies when varying model capacity instead of optimization steps, and provide the first demonstration of model-wise grokking.
Objective Robustness in Deep Reinforcement Learning
Jun 08, 2021

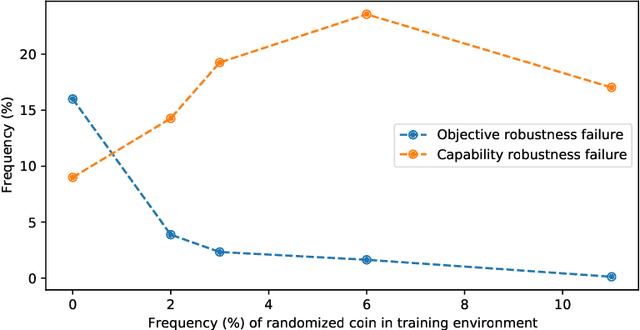

We study objective robustness failures, a type of out-of-distribution robustness failure in reinforcement learning (RL). Objective robustness failures occur when an RL agent retains its capabilities out-of-distribution yet pursues the wrong objective. This kind of failure presents different risks than the robustness problems usually considered in the literature, since it involves agents that leverage their capabilities to pursue the wrong objective rather than simply failing to do anything useful. We provide the first explicit empirical demonstrations of objective robustness failures and present a partial characterization of its causes.