 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeErik Jenner
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
Apr 15, 2024
This work identifies 18 foundational challenges in assuring the alignment and safety of large language models (LLMs). These challenges are organized into three different categories: scientific understanding of LLMs, development and deployment methods, and sociotechnical challenges. Based on the identified challenges, we pose $200+$ concrete research questions.
When Your AIs Deceive You: Challenges with Partial Observability of Human Evaluators in Reward Learning
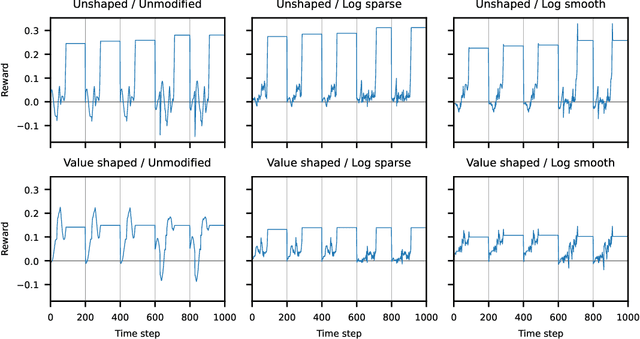
Mar 03, 2024Past analyses of reinforcement learning from human feedback (RLHF) assume that the human fully observes the environment. What happens when human feedback is based only on partial observations? We formally define two failure cases: deception and overjustification. Modeling the human as Boltzmann-rational w.r.t. a belief over trajectories, we prove conditions under which RLHF is guaranteed to result in policies that deceptively inflate their performance, overjustify their behavior to make an impression, or both. To help address these issues, we mathematically characterize how partial observability of the environment translates into (lack of) ambiguity in the learned return function. In some cases, accounting for partial observability makes it theoretically possible to recover the return function and thus the optimal policy, while in other cases, there is irreducible ambiguity. We caution against blindly applying RLHF in partially observable settings and propose research directions to help tackle these challenges.
STARC: A General Framework For Quantifying Differences Between Reward Functions
Sep 26, 2023
In order to solve a task using reinforcement learning, it is necessary to first formalise the goal of that task as a reward function. However, for many real-world tasks, it is very difficult to manually specify a reward function that never incentivises undesirable behaviour. As a result, it is increasingly popular to use reward learning algorithms, which attempt to learn a reward function from data. However, the theoretical foundations of reward learning are not yet well-developed. In particular, it is typically not known when a given reward learning algorithm with high probability will learn a reward function that is safe to optimise. This means that reward learning algorithms generally must be evaluated empirically, which is expensive, and that their failure modes are difficult to predict in advance. One of the roadblocks to deriving better theoretical guarantees is the lack of good methods for quantifying the difference between reward functions. In this paper we provide a solution to this problem, in the form of a class of pseudometrics on the space of all reward functions that we call STARC (STAndardised Reward Comparison) metrics. We show that STARC metrics induce both an upper and a lower bound on worst-case regret, which implies that our metrics are tight, and that any metric with the same properties must be bilipschitz equivalent to ours. Moreover, we also identify a number of issues with reward metrics proposed by earlier works. Finally, we evaluate our metrics empirically, to demonstrate their practical efficacy. STARC metrics can be used to make both theoretical and empirical analysis of reward learning algorithms both easier and more principled.
imitation: Clean Imitation Learning Implementations
Nov 22, 2022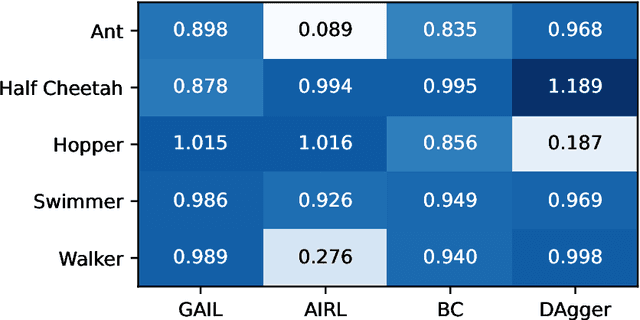



imitation provides open-source implementations of imitation and reward learning algorithms in PyTorch. We include three inverse reinforcement learning (IRL) algorithms, three imitation learning algorithms and a preference comparison algorithm. The implementations have been benchmarked against previous results, and automated tests cover 98% of the code. Moreover, the algorithms are implemented in a modular fashion, making it simple to develop novel algorithms in the framework. Our source code, including documentation and examples, is available at https://github.com/HumanCompatibleAI/imitation
Calculus on MDPs: Potential Shaping as a Gradient
Aug 20, 2022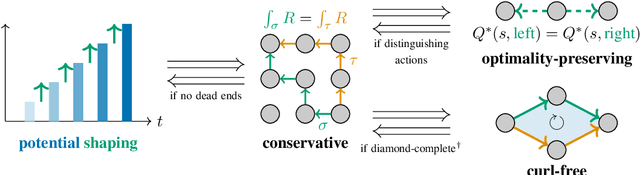

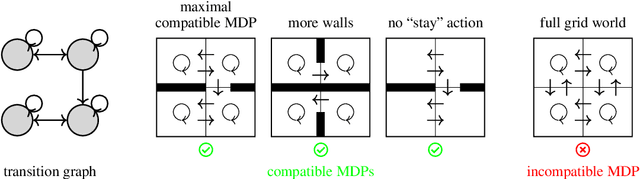
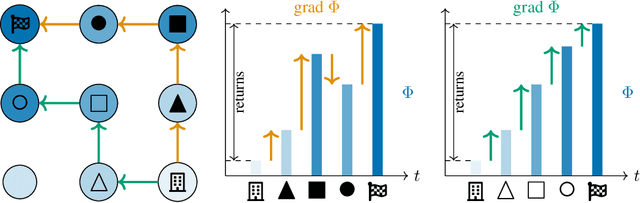
In reinforcement learning, different reward functions can be equivalent in terms of the optimal policies they induce. A particularly well-known and important example is potential shaping, a class of functions that can be added to any reward function without changing the optimal policy set under arbitrary transition dynamics. Potential shaping is conceptually similar to potentials, conservative vector fields and gauge transformations in math and physics, but this connection has not previously been formally explored. We develop a formalism for discrete calculus on graphs that abstract a Markov Decision Process, and show how potential shaping can be formally interpreted as a gradient within this framework. This allows us to strengthen results from Ng et al. (1999) describing conditions under which potential shaping is the only additive reward transformation to always preserve optimal policies. As an additional application of our formalism, we define a rule for picking a single unique reward function from each potential shaping equivalence class.
Preprocessing Reward Functions for Interpretability
Mar 25, 2022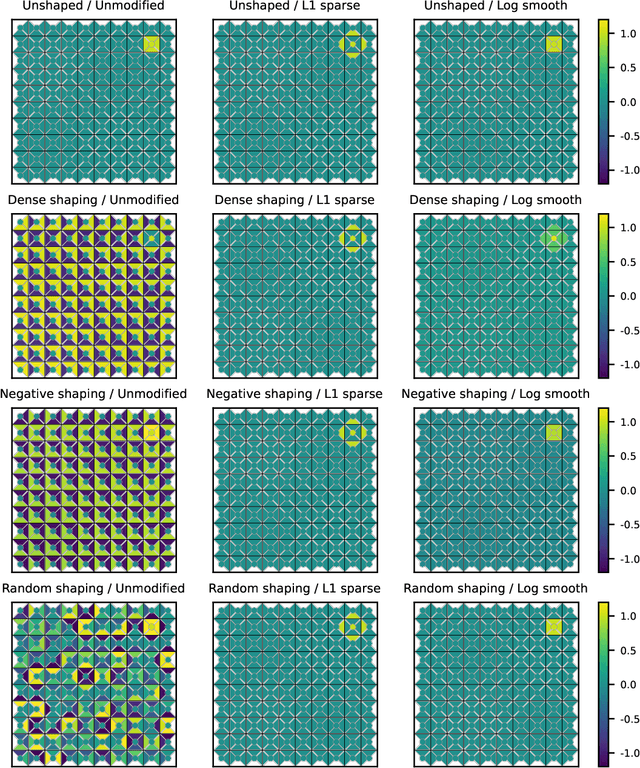

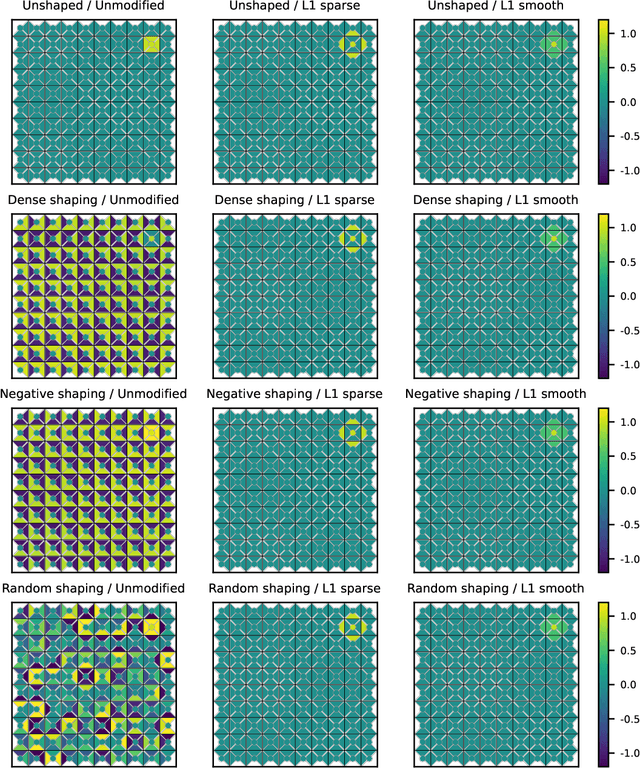
In many real-world applications, the reward function is too complex to be manually specified. In such cases, reward functions must instead be learned from human feedback. Since the learned reward may fail to represent user preferences, it is important to be able to validate the learned reward function prior to deployment. One promising approach is to apply interpretability tools to the reward function to spot potential deviations from the user's intention. Existing work has applied general-purpose interpretability tools to understand learned reward functions. We propose exploiting the intrinsic structure of reward functions by first preprocessing them into simpler but equivalent reward functions, which are then visualized. We introduce a general framework for such reward preprocessing and propose concrete preprocessing algorithms. Our empirical evaluation shows that preprocessed rewards are often significantly easier to understand than the original reward.
Extensions of Karger's Algorithm: Why They Fail in Theory and How They Are Useful in Practice
Oct 05, 2021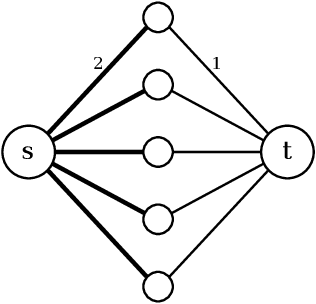
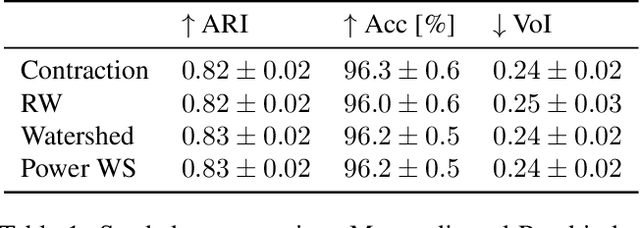
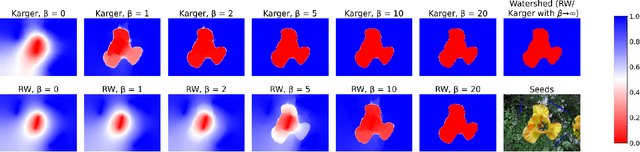
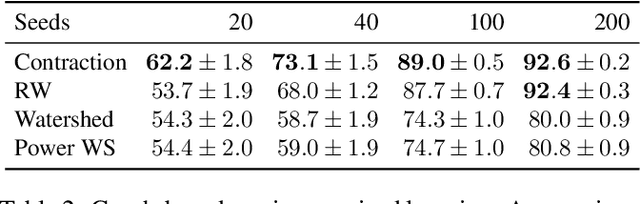
The minimum graph cut and minimum $s$-$t$-cut problems are important primitives in the modeling of combinatorial problems in computer science, including in computer vision and machine learning. Some of the most efficient algorithms for finding global minimum cuts are randomized algorithms based on Karger's groundbreaking contraction algorithm. Here, we study whether Karger's algorithm can be successfully generalized to other cut problems. We first prove that a wide class of natural generalizations of Karger's algorithm cannot efficiently solve the $s$-$t$-mincut or the normalized cut problem to optimality. However, we then present a simple new algorithm for seeded segmentation / graph-based semi-supervised learning that is closely based on Karger's original algorithm, showing that for these problems, extensions of Karger's algorithm can be useful. The new algorithm has linear asymptotic runtime and yields a potential that can be interpreted as the posterior probability of a sample belonging to a given seed / class. We clarify its relation to the random walker algorithm / harmonic energy minimization in terms of distributions over spanning forests. On classical problems from seeded image segmentation and graph-based semi-supervised learning on image data, the method performs at least as well as the random walker / harmonic energy minimization / Gaussian processes.
Steerable Partial Differential Operators for Equivariant Neural Networks
Jun 18, 2021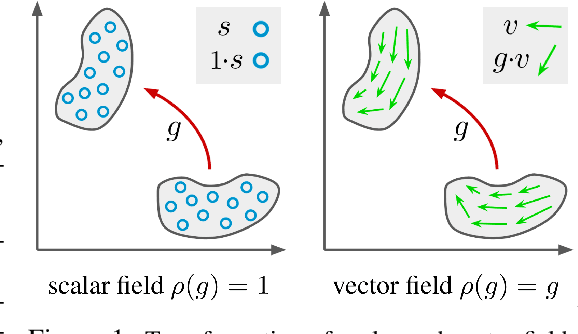
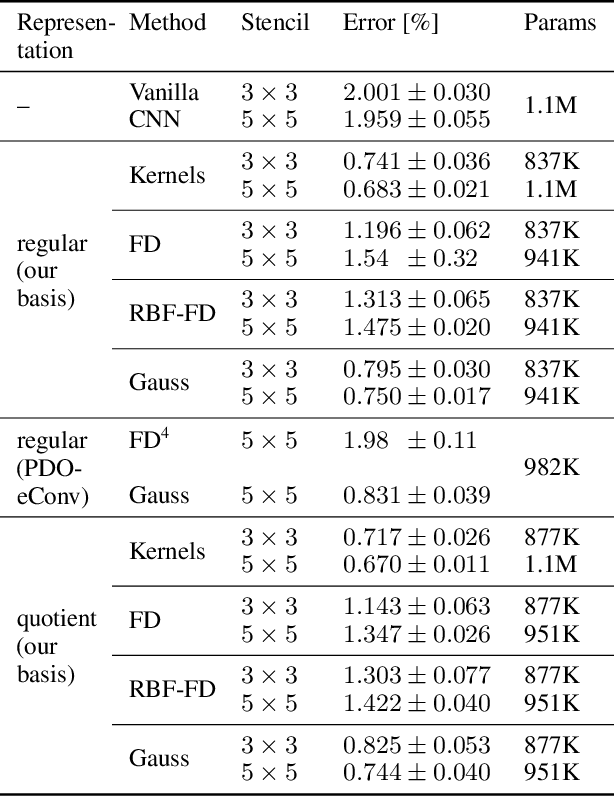
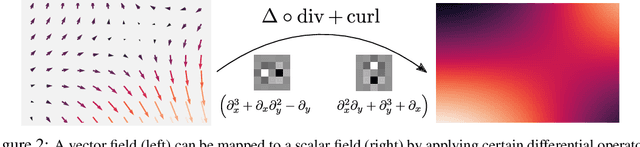
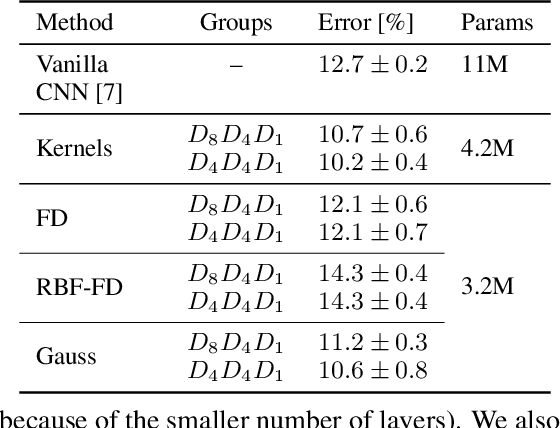
Recent work in equivariant deep learning bears strong similarities to physics. Fields over a base space are fundamental entities in both subjects, as are equivariant maps between these fields. In deep learning, however, these maps are usually defined by convolutions with a kernel, whereas they are partial differential operators (PDOs) in physics. Developing the theory of equivariant PDOs in the context of deep learning could bring these subjects even closer together and lead to a stronger flow of ideas. In this work, we derive a $G$-steerability constraint that completely characterizes when a PDO between feature vector fields is equivariant, for arbitrary symmetry groups $G$. We then fully solve this constraint for several important groups. We use our solutions as equivariant drop-in replacements for convolutional layers and benchmark them in that role. Finally, we develop a framework for equivariant maps based on Schwartz distributions that unifies classical convolutions and differential operators and gives insight about the relation between the two.