 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeter Hase
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
Apr 15, 2024
This work identifies 18 foundational challenges in assuring the alignment and safety of large language models (LLMs). These challenges are organized into three different categories: scientific understanding of LLMs, development and deployment methods, and sociotechnical challenges. Based on the identified challenges, we pose $200+$ concrete research questions.
Rethinking Machine Unlearning for Large Language Models
Feb 15, 2024We explore machine unlearning (MU) in the domain of large language models (LLMs), referred to as LLM unlearning. This initiative aims to eliminate undesirable data influence (e.g., sensitive or illegal information) and the associated model capabilities, while maintaining the integrity of essential knowledge generation and not affecting causally unrelated information. We envision LLM unlearning becoming a pivotal element in the life-cycle management of LLMs, potentially standing as an essential foundation for developing generative AI that is not only safe, secure, and trustworthy, but also resource-efficient without the need of full retraining. We navigate the unlearning landscape in LLMs from conceptual formulation, methodologies, metrics, and applications. In particular, we highlight the often-overlooked aspects of existing LLM unlearning research, e.g., unlearning scope, data-model interaction, and multifaceted efficacy assessment. We also draw connections between LLM unlearning and related areas such as model editing, influence functions, model explanation, adversarial training, and reinforcement learning. Furthermore, we outline an effective assessment framework for LLM unlearning and explore its applications in copyright and privacy safeguards and sociotechnical harm reduction.
The Unreasonable Effectiveness of Easy Training Data for Hard Tasks
Jan 12, 2024How can we train models to perform well on hard test data when hard training data is by definition difficult to label correctly? This question has been termed the scalable oversight problem and has drawn increasing attention as language models have continually improved. In this paper, we present the surprising conclusion that current language models often generalize relatively well from easy to hard data, even performing as well as "oracle" models trained on hard data. We demonstrate this kind of easy-to-hard generalization using simple training methods like in-context learning, linear classifier heads, and QLoRA for seven different measures of datapoint hardness, including six empirically diverse human hardness measures (like grade level) and one model-based measure (loss-based). Furthermore, we show that even if one cares most about model performance on hard data, it can be better to collect and train on easy data rather than hard data, since hard data is generally noisier and costlier to collect. Our experiments use open models up to 70b in size and four publicly available question-answering datasets with questions ranging in difficulty from 3rd grade science questions to college level STEM questions and general-knowledge trivia. We conclude that easy-to-hard generalization in LMs is surprisingly strong for the tasks studied, suggesting the scalable oversight problem may be easier than previously thought. Our code is available at https://github.com/allenai/easy-to-hard-generalization
Can Sensitive Information Be Deleted From LLMs? Objectives for Defending Against Extraction Attacks
Sep 29, 2023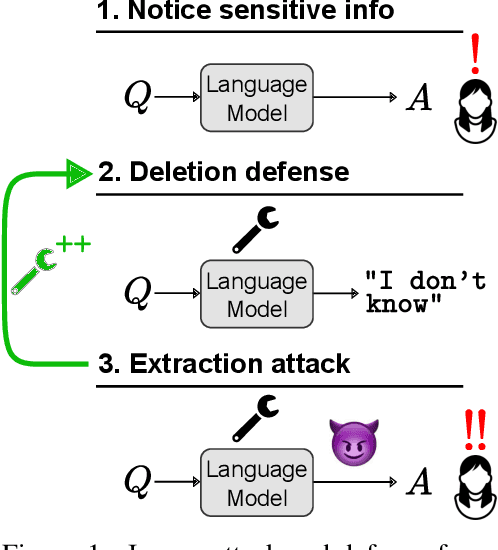
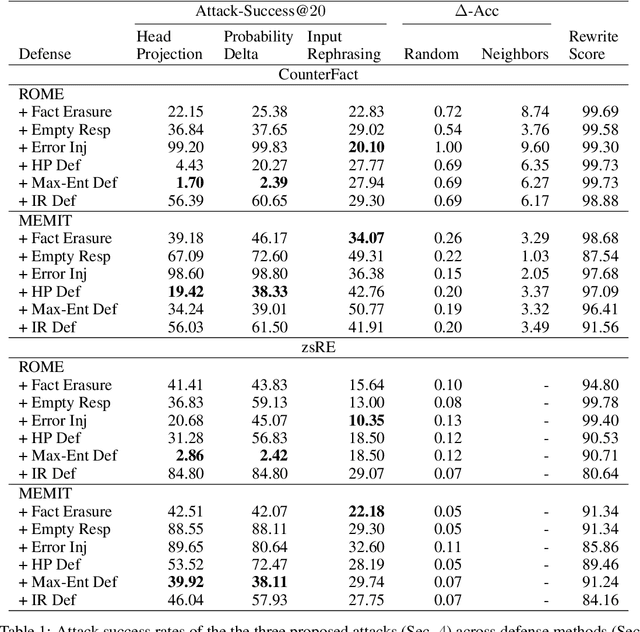
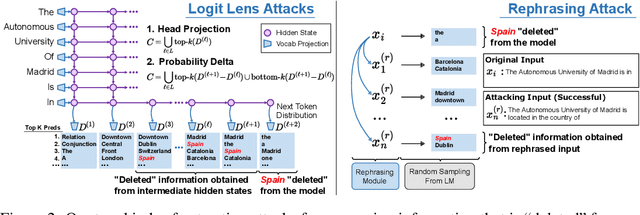

Pretrained language models sometimes possess knowledge that we do not wish them to, including memorized personal information and knowledge that could be used to harm people. They can also output toxic or harmful text. To mitigate these safety and informational issues, we propose an attack-and-defense framework for studying the task of deleting sensitive information directly from model weights. We study direct edits to model weights because (1) this approach should guarantee that particular deleted information is never extracted by future prompt attacks, and (2) it should protect against whitebox attacks, which is necessary for making claims about safety/privacy in a setting where publicly available model weights could be used to elicit sensitive information. Our threat model assumes that an attack succeeds if the answer to a sensitive question is located among a set of B generated candidates, based on scenarios where the information would be insecure if the answer is among B candidates. Experimentally, we show that even state-of-the-art model editing methods such as ROME struggle to truly delete factual information from models like GPT-J, as our whitebox and blackbox attacks can recover "deleted" information from an edited model 38% of the time. These attacks leverage two key observations: (1) that traces of deleted information can be found in intermediate model hidden states, and (2) that applying an editing method for one question may not delete information across rephrased versions of the question. Finally, we provide new defense methods that protect against some extraction attacks, but we do not find a single universally effective defense method. Our results suggest that truly deleting sensitive information is a tractable but difficult problem, since even relatively low attack success rates have potentially severe societal implications for real-world deployment of language models.
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Jul 27, 2023
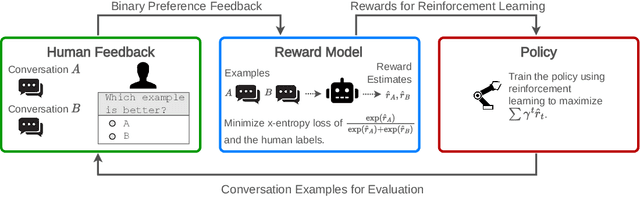
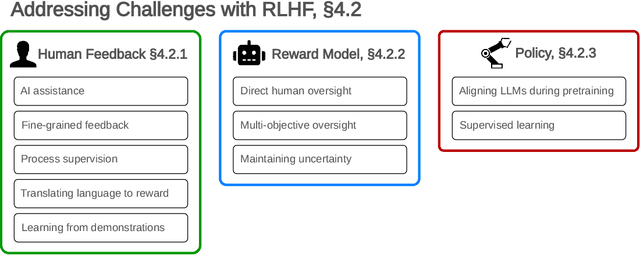
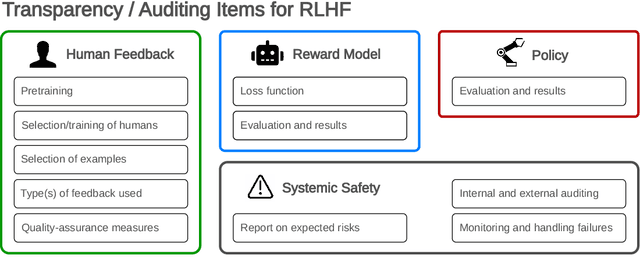
Reinforcement learning from human feedback (RLHF) is a technique for training AI systems to align with human goals. RLHF has emerged as the central method used to finetune state-of-the-art large language models (LLMs). Despite this popularity, there has been relatively little public work systematizing its flaws. In this paper, we (1) survey open problems and fundamental limitations of RLHF and related methods; (2) overview techniques to understand, improve, and complement RLHF in practice; and (3) propose auditing and disclosure standards to improve societal oversight of RLHF systems. Our work emphasizes the limitations of RLHF and highlights the importance of a multi-faceted approach to the development of safer AI systems.
Can Language Models Teach Weaker Agents? Teacher Explanations Improve Students via Theory of Mind
Jun 15, 2023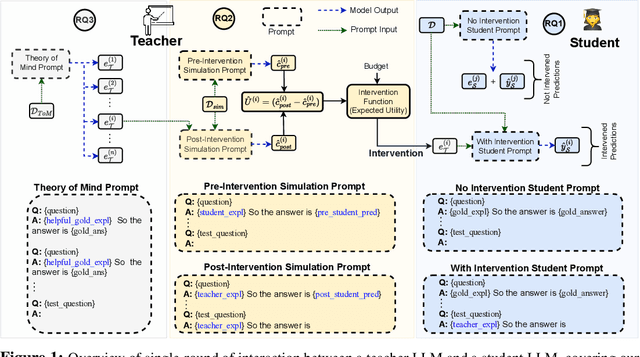
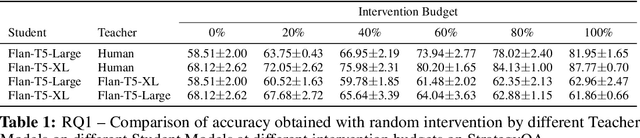
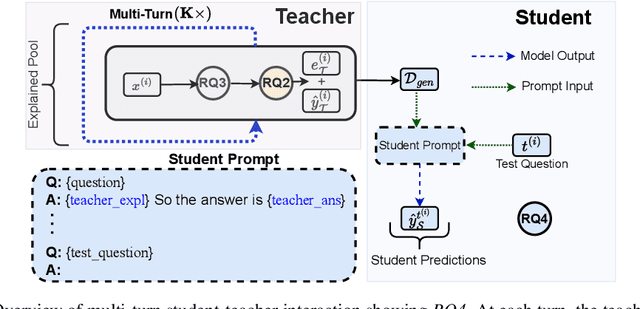

Large Language Models (LLMs) perform complex reasoning by generating explanations for their predictions. However, a complementary goal of explanations is to also communicate useful knowledge that improves weaker agents. Hence, we investigate whether LLMs also make good teachers for weaker agents. In particular, we consider a student-teacher framework between two LLM agents and study if, when, and how the teacher should intervene with natural language explanations to improve the student's performance. Since communication is expensive, we define a budget such that the teacher only communicates explanations for a fraction of the data, after which the student should perform well on its own. We decompose the teaching problem along four axes: (1) if teacher's test time intervention improve student predictions, (2) when it is worth explaining a data point, (3) how the teacher should personalize explanations to better teach the student, and (4) if teacher explanations also improve student performance on future unexplained data. We first show that teacher LLMs can indeed intervene on student reasoning to improve their performance. Next, we propose a Theory of Mind approach, in which the teacher builds two few-shot mental models of the student. The first model defines an Intervention Function that simulates the utility of an intervention, allowing the teacher to intervene when this utility is the highest and improving student performance at lower budgets. The second model enables the teacher to personalize explanations for a particular student and outperform unpersonalized teachers. We also demonstrate that in multi-turn interactions, teacher explanations generalize and learning from explained data improves student performance on future unexplained data. Finally, we also verify that misaligned teachers can lower student performance to random chance by intentionally misleading them.
Adaptive Contextual Perception: How to Generalize to New Backgrounds and Ambiguous Objects
Jun 09, 2023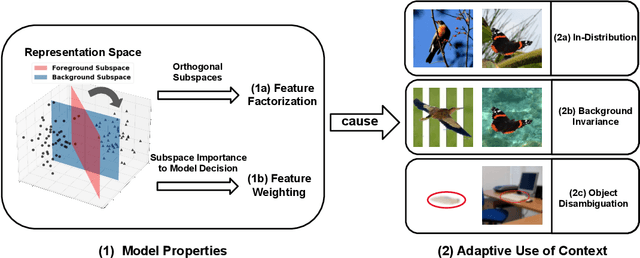
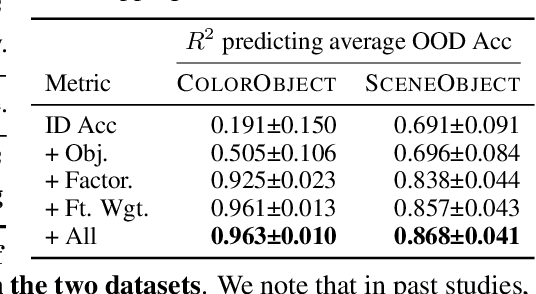

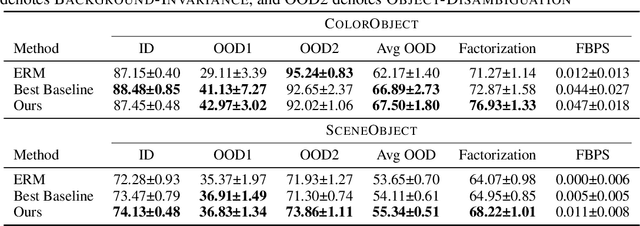
Biological vision systems make adaptive use of context to recognize objects in new settings with novel contexts as well as occluded or blurry objects in familiar settings. In this paper, we investigate how vision models adaptively use context for out-of-distribution (OOD) generalization and leverage our analysis results to improve model OOD generalization. First, we formulate two distinct OOD settings where the contexts are either irrelevant (Background-Invariance) or beneficial (Object-Disambiguation), reflecting the diverse contextual challenges faced in biological vision. We then analyze model performance in these two different OOD settings and demonstrate that models that excel in one setting tend to struggle in the other. Notably, prior works on learning causal features improve on one setting but hurt in the other. This underscores the importance of generalizing across both OOD settings, as this ability is crucial for both human cognition and robust AI systems. Next, to better understand the model properties contributing to OOD generalization, we use representational geometry analysis and our own probing methods to examine a population of models, and we discover that those with more factorized representations and appropriate feature weighting are more successful in handling Background-Invariance and Object-Disambiguation tests. We further validate these findings through causal intervention on representation factorization and feature weighting to demonstrate their causal effect on performance. Lastly, we propose new augmentation methods to enhance model generalization. These methods outperform strong baselines, yielding improvements in both in-distribution and OOD tests. In conclusion, to replicate the generalization abilities of biological vision, computer vision models must have factorized object vs. background representations and appropriately weight both kinds of features.
Does Localization Inform Editing? Surprising Differences in Causality-Based Localization vs. Knowledge Editing in Language Models
Jan 10, 2023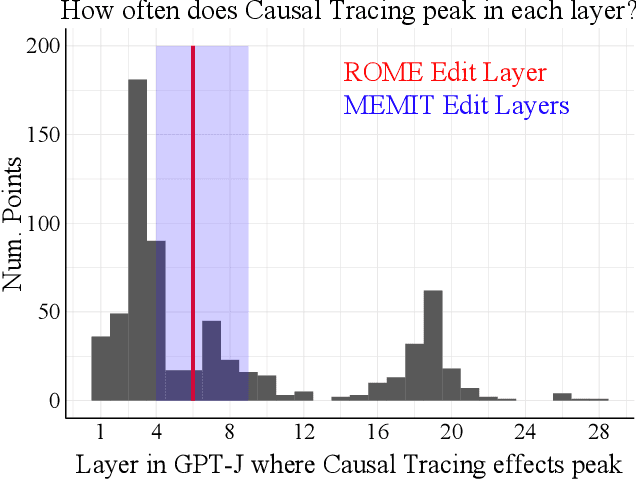
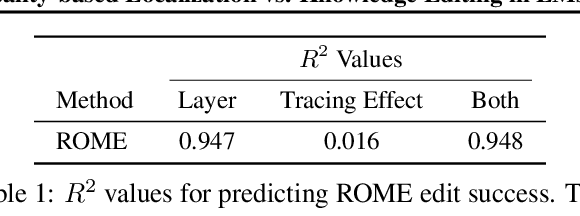
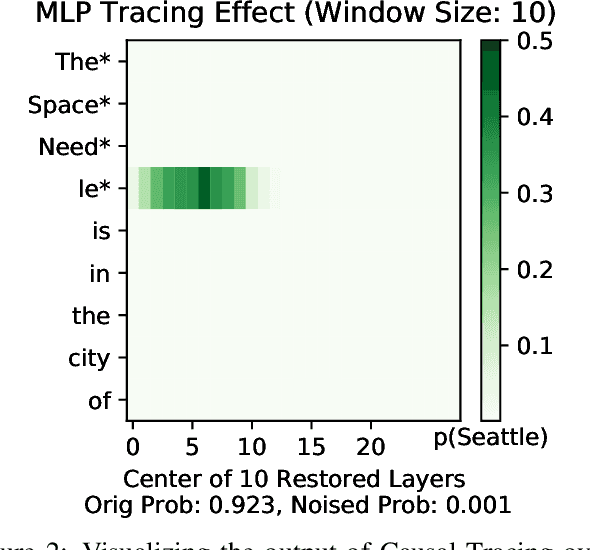
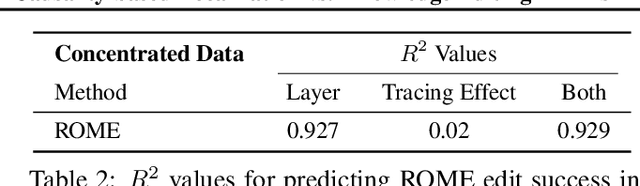
Language models are known to learn a great quantity of factual information during pretraining, and recent work localizes this information to specific model weights like mid-layer MLP weights (Meng et al., 2022). In this paper, we find that we can change how a fact is stored in a model by editing weights that are in a different location than where existing methods suggest that the fact is stored. This is surprising because we would expect that localizing facts to specific parameters in models would tell us where to manipulate knowledge in models, and this assumption has motivated past work on model editing methods. Specifically, we show that localization conclusions from representation denoising (also known as Causal Tracing) do not provide any insight into which model MLP layer would be best to edit in order to override an existing stored fact with a new one. This finding raises questions about how past work relies on Causal Tracing to select which model layers to edit (Meng et al., 2022). Next, to better understand the discrepancy between representation denoising and weight editing, we develop several variants of the editing problem that appear more and more like representation denoising in their design and objective. Experiments show that, for one of our editing problems, editing performance does relate to localization results from representation denoising, but we find that which layer we edit is a far better predictor of performance. Our results suggest, counterintuitively, that better mechanistic understanding of how pretrained language models work may not always translate to insights about how to best change their behavior. Code is available at: https://github.com/google/belief-localization
Are Hard Examples also Harder to Explain? A Study with Human and Model-Generated Explanations
Nov 14, 2022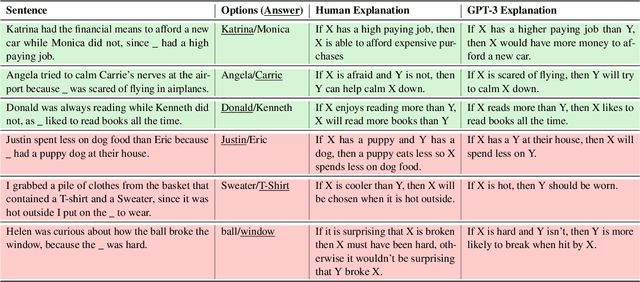
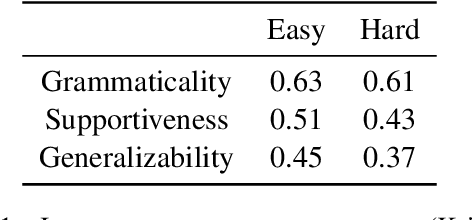
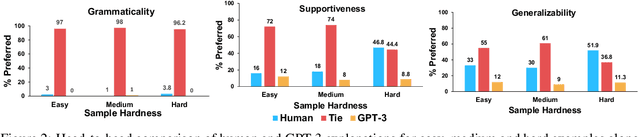
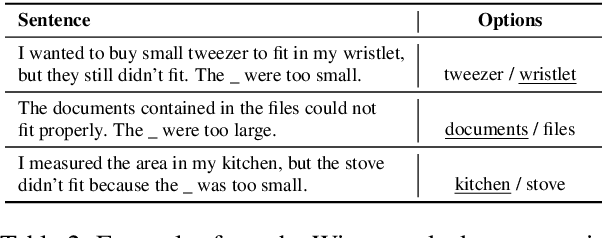
Recent work on explainable NLP has shown that few-shot prompting can enable large pretrained language models (LLMs) to generate grammatical and factual natural language explanations for data labels. In this work, we study the connection between explainability and sample hardness by investigating the following research question - "Are LLMs and humans equally good at explaining data labels for both easy and hard samples?" We answer this question by first collecting human-written explanations in the form of generalizable commonsense rules on the task of Winograd Schema Challenge (Winogrande dataset). We compare these explanations with those generated by GPT-3 while varying the hardness of the test samples as well as the in-context samples. We observe that (1) GPT-3 explanations are as grammatical as human explanations regardless of the hardness of the test samples, (2) for easy examples, GPT-3 generates highly supportive explanations but human explanations are more generalizable, and (3) for hard examples, human explanations are significantly better than GPT-3 explanations both in terms of label-supportiveness and generalizability judgements. We also find that hardness of the in-context examples impacts the quality of GPT-3 explanations. Finally, we show that the supportiveness and generalizability aspects of human explanations are also impacted by sample hardness, although by a much smaller margin than models. Supporting code and data are available at https://github.com/swarnaHub/ExplanationHardness
Summarization Programs: Interpretable Abstractive Summarization with Neural Modular Trees
Sep 21, 2022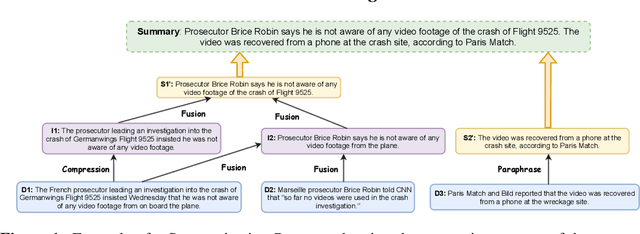

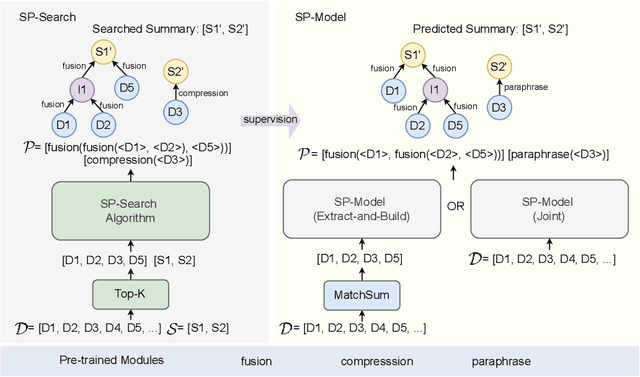
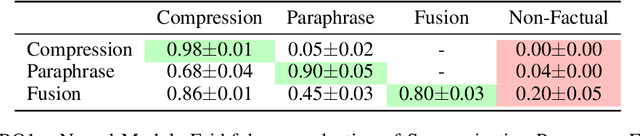
Current abstractive summarization models either suffer from a lack of clear interpretability or provide incomplete rationales by only highlighting parts of the source document. To this end, we propose the Summarization Program (SP), an interpretable modular framework consisting of an (ordered) list of binary trees, each encoding the step-by-step generative process of an abstractive summary sentence from the source document. A Summarization Program contains one root node per summary sentence, and a distinct tree connects each summary sentence (root node) to the document sentences (leaf nodes) from which it is derived, with the connecting nodes containing intermediate generated sentences. Edges represent different modular operations involved in summarization such as sentence fusion, compression, and paraphrasing. We first propose an efficient best-first search method over neural modules, SP-Search that identifies SPs for human summaries by directly optimizing for ROUGE scores. Next, using these programs as automatic supervision, we propose seq2seq models that generate Summarization Programs, which are then executed to obtain final summaries. We demonstrate that SP-Search effectively represents the generative process behind human summaries using modules that are typically faithful to their intended behavior. We also conduct a simulation study to show that Summarization Programs improve the interpretability of summarization models by allowing humans to better simulate model reasoning. Summarization Programs constitute a promising step toward interpretable and modular abstractive summarization, a complex task previously addressed primarily through blackbox end-to-end neural systems. Our code is available at https://github.com/swarnaHub/SummarizationPrograms