 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEric J. Michaud
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Mar 31, 2024
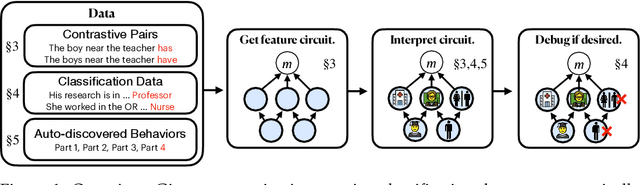

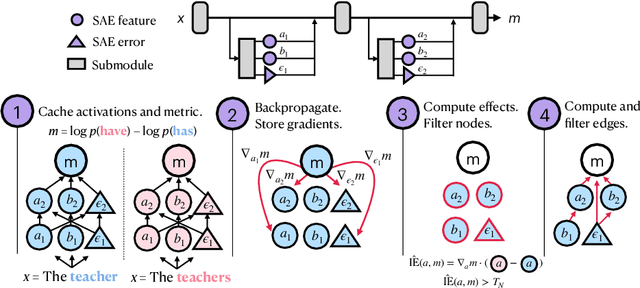
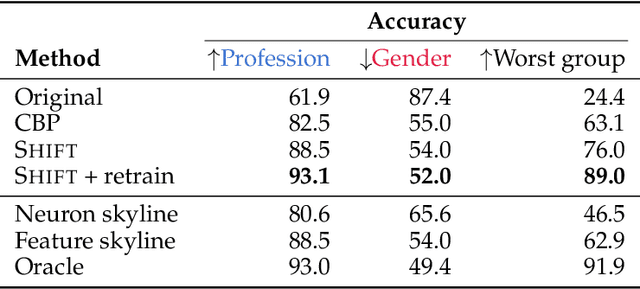
We introduce methods for discovering and applying sparse feature circuits. These are causally implicated subnetworks of human-interpretable features for explaining language model behaviors. Circuits identified in prior work consist of polysemantic and difficult-to-interpret units like attention heads or neurons, rendering them unsuitable for many downstream applications. In contrast, sparse feature circuits enable detailed understanding of unanticipated mechanisms. Because they are based on fine-grained units, sparse feature circuits are useful for downstream tasks: We introduce SHIFT, where we improve the generalization of a classifier by ablating features that a human judges to be task-irrelevant. Finally, we demonstrate an entirely unsupervised and scalable interpretability pipeline by discovering thousands of sparse feature circuits for automatically discovered model behaviors.
Opening the AI black box: program synthesis via mechanistic interpretability
Feb 07, 2024We present MIPS, a novel method for program synthesis based on automated mechanistic interpretability of neural networks trained to perform the desired task, auto-distilling the learned algorithm into Python code. We test MIPS on a benchmark of 62 algorithmic tasks that can be learned by an RNN and find it highly complementary to GPT-4: MIPS solves 32 of them, including 13 that are not solved by GPT-4 (which also solves 30). MIPS uses an integer autoencoder to convert the RNN into a finite state machine, then applies Boolean or integer symbolic regression to capture the learned algorithm. As opposed to large language models, this program synthesis technique makes no use of (and is therefore not limited by) human training data such as algorithms and code from GitHub. We discuss opportunities and challenges for scaling up this approach to make machine-learned models more interpretable and trustworthy.
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Jul 27, 2023
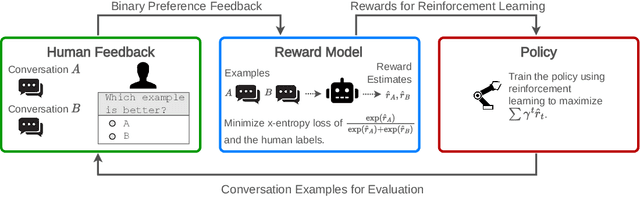
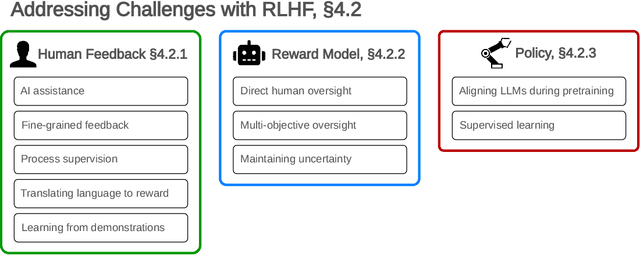
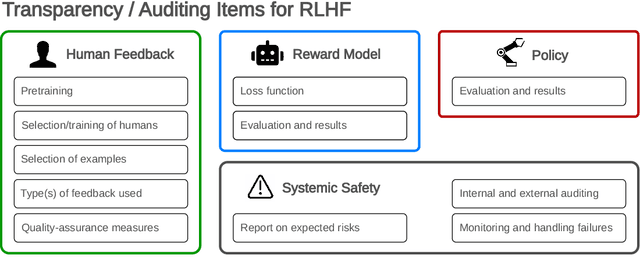
Reinforcement learning from human feedback (RLHF) is a technique for training AI systems to align with human goals. RLHF has emerged as the central method used to finetune state-of-the-art large language models (LLMs). Despite this popularity, there has been relatively little public work systematizing its flaws. In this paper, we (1) survey open problems and fundamental limitations of RLHF and related methods; (2) overview techniques to understand, improve, and complement RLHF in practice; and (3) propose auditing and disclosure standards to improve societal oversight of RLHF systems. Our work emphasizes the limitations of RLHF and highlights the importance of a multi-faceted approach to the development of safer AI systems.
The Quantization Model of Neural Scaling
Mar 23, 2023



We propose the $\textit{Quantization Model}$ of neural scaling laws, explaining both the observed power law dropoff of loss with model and data size, and also the sudden emergence of new capabilities with scale. We derive this model from what we call the $\textit{Quantization Hypothesis}$, where learned network capabilities are quantized into discrete chunks ($\textit{quanta}$). We show that when quanta are learned in order of decreasing use frequency, then a power law in use frequencies explains observed power law scaling of loss. We validate this prediction on toy datasets, then study how scaling curves decompose for large language models. Using language model internals, we auto-discover diverse model capabilities (quanta) and find tentative evidence that the distribution over corresponding subproblems in the prediction of natural text is compatible with the power law predicted from the neural scaling exponent as predicted from our theory.
Precision Machine Learning
Oct 24, 2022



We explore unique considerations involved in fitting ML models to data with very high precision, as is often required for science applications. We empirically compare various function approximation methods and study how they scale with increasing parameters and data. We find that neural networks can often outperform classical approximation methods on high-dimensional examples, by auto-discovering and exploiting modular structures therein. However, neural networks trained with common optimizers are less powerful for low-dimensional cases, which motivates us to study the unique properties of neural network loss landscapes and the corresponding optimization challenges that arise in the high precision regime. To address the optimization issue in low dimensions, we develop training tricks which enable us to train neural networks to extremely low loss, close to the limits allowed by numerical precision.
Omnigrok: Grokking Beyond Algorithmic Data
Oct 03, 2022



Grokking, the unusual phenomenon for algorithmic datasets where generalization happens long after overfitting the training data, has remained elusive. We aim to understand grokking by analyzing the loss landscapes of neural networks, identifying the mismatch between training and test losses as the cause for grokking. We refer to this as the "LU mechanism" because training and test losses (against model weight norm) typically resemble "L" and "U", respectively. This simple mechanism can nicely explain many aspects of grokking: data size dependence, weight decay dependence, the emergence of representations, etc. Guided by the intuitive picture, we are able to induce grokking on tasks involving images, language and molecules. In the reverse direction, we are able to eliminate grokking for algorithmic datasets. We attribute the dramatic nature of grokking for algorithmic datasets to representation learning.
Towards Understanding Grokking: An Effective Theory of Representation Learning
May 20, 2022



We aim to understand grokking, a phenomenon where models generalize long after overfitting their training set. We present both a microscopic analysis anchored by an effective theory and a macroscopic analysis of phase diagrams describing learning performance across hyperparameters. We find that generalization originates from structured representations whose training dynamics and dependence on training set size can be predicted by our effective theory in a toy setting. We observe empirically the presence of four learning phases: comprehension, grokking, memorization, and confusion. We find representation learning to occur only in a "Goldilocks zone" (including comprehension and grokking) between memorization and confusion. Compared to the comprehension phase, the grokking phase stays closer to the memorization phase, leading to delayed generalization. The Goldilocks phase is reminiscent of "intelligence from starvation" in Darwinian evolution, where resource limitations drive discovery of more efficient solutions. This study not only provides intuitive explanations of the origin of grokking, but also highlights the usefulness of physics-inspired tools, e.g., effective theories and phase diagrams, for understanding deep learning.
Understanding Learned Reward Functions
Dec 10, 2020



In many real-world tasks, it is not possible to procedurally specify an RL agent's reward function. In such cases, a reward function must instead be learned from interacting with and observing humans. However, current techniques for reward learning may fail to produce reward functions which accurately reflect user preferences. Absent significant advances in reward learning, it is thus important to be able to audit learned reward functions to verify whether they truly capture user preferences. In this paper, we investigate techniques for interpreting learned reward functions. In particular, we apply saliency methods to identify failure modes and predict the robustness of reward functions. We find that learned reward functions often implement surprising algorithms that rely on contingent aspects of the environment. We also discover that existing interpretability techniques often attend to irrelevant changes in reward output, suggesting that reward interpretability may need significantly different methods from policy interpretability.
Examining the causal structures of deep neural networks using information theory
Oct 26, 2020



Deep Neural Networks (DNNs) are often examined at the level of their response to input, such as analyzing the mutual information between nodes and data sets. Yet DNNs can also be examined at the level of causation, exploring "what does what" within the layers of the network itself. Historically, analyzing the causal structure of DNNs has received less attention than understanding their responses to input. Yet definitionally, generalizability must be a function of a DNN's causal structure since it reflects how the DNN responds to unseen or even not-yet-defined future inputs. Here, we introduce a suite of metrics based on information theory to quantify and track changes in the causal structure of DNNs during training. Specifically, we introduce the effective information (EI) of a feedforward DNN, which is the mutual information between layer input and output following a maximum-entropy perturbation. The EI can be used to assess the degree of causal influence nodes and edges have over their downstream targets in each layer. We show that the EI can be further decomposed in order to examine the sensitivity of a layer (measured by how well edges transmit perturbations) and the degeneracy of a layer (measured by how edge overlap interferes with transmission), along with estimates of the amount of integrated information of a layer. Together, these properties define where each layer lies in the "causal plane" which can be used to visualize how layer connectivity becomes more sensitive or degenerate over time, and how integration changes during training, revealing how the layer-by-layer causal structure differentiates. These results may help in understanding the generalization capabilities of DNNs and provide foundational tools for making DNNs both more generalizable and more explainable.