 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJinkyoo Park
Ensembling Prioritized Hybrid Policies for Multi-agent Pathfinding
Mar 12, 2024
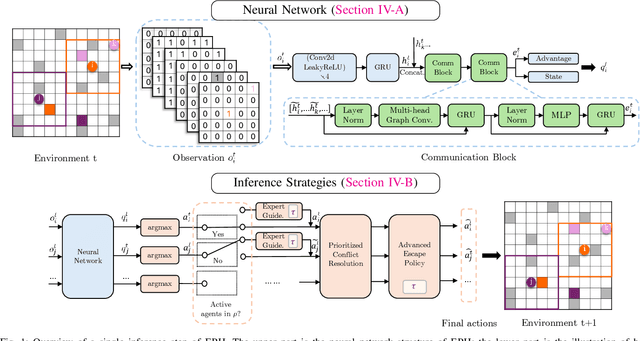
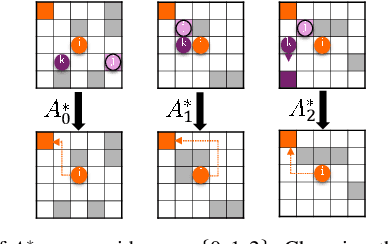
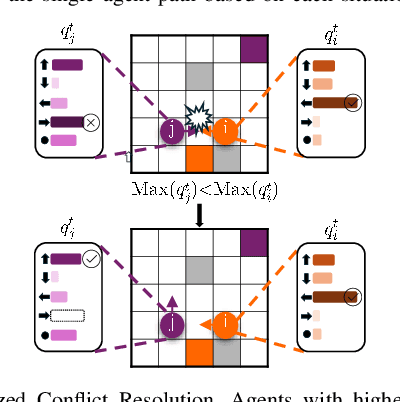
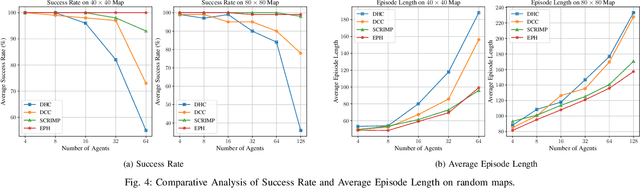
Multi-Agent Reinforcement Learning (MARL) based Multi-Agent Path Finding (MAPF) has recently gained attention due to its efficiency and scalability. Several MARL-MAPF methods choose to use communication to enrich the information one agent can perceive. However, existing works still struggle in structured environments with high obstacle density and a high number of agents. To further improve the performance of the communication-based MARL-MAPF solvers, we propose a new method, Ensembling Prioritized Hybrid Policies (EPH). We first propose a selective communication block to gather richer information for better agent coordination within multi-agent environments and train the model with a Q-learning-based algorithm. We further introduce three advanced inference strategies aimed at bolstering performance during the execution phase. First, we hybridize the neural policy with single-agent expert guidance for navigating conflict-free zones. Secondly, we propose Q value-based methods for prioritized resolution of conflicts as well as deadlock situations. Finally, we introduce a robust ensemble method that can efficiently collect the best out of multiple possible solutions. We empirically evaluate EPH in complex multi-agent environments and demonstrate competitive performance against state-of-the-art neural methods for MAPF.
Ant Colony Sampling with GFlowNets for Combinatorial Optimization
Mar 11, 2024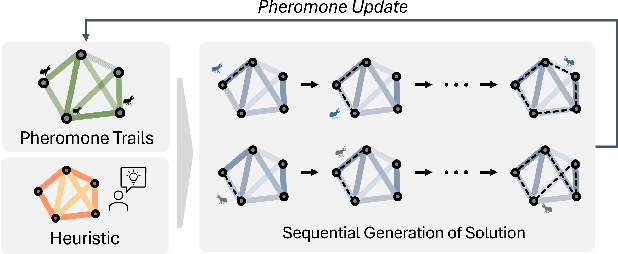
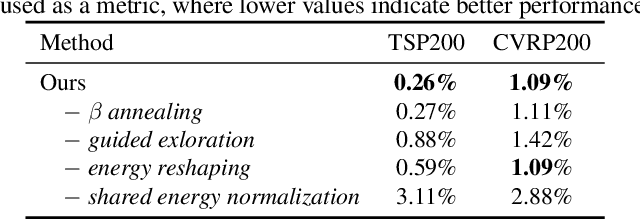
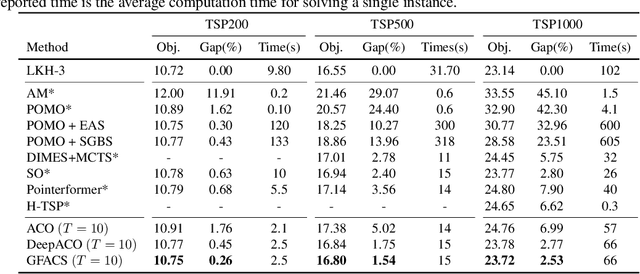
This paper introduces the Generative Flow Ant Colony Sampler (GFACS), a novel neural-guided meta-heuristic algorithm for combinatorial optimization. GFACS integrates generative flow networks (GFlowNets) with the ant colony optimization (ACO) methodology. GFlowNets, a generative model that learns a constructive policy in combinatorial spaces, enhance ACO by providing an informed prior distribution of decision variables conditioned on input graph instances. Furthermore, we introduce a novel combination of training tricks, including search-guided local exploration, energy normalization, and energy shaping to improve GFACS. Our experimental results demonstrate that GFACS outperforms baseline ACO algorithms in seven CO tasks and is competitive with problem-specific heuristics for vehicle routing problems. The source code is available at \url{https://github.com/ai4co/gfacs}.
ELA: Exploited Level Augmentation for Offline Learning in Zero-Sum Games
Feb 28, 2024Offline learning has become widely used due to its ability to derive effective policies from offline datasets gathered by expert demonstrators without interacting with the environment directly. Recent research has explored various ways to enhance offline learning efficiency by considering the characteristics (e.g., expertise level or multiple demonstrators) of the dataset. However, a different approach is necessary in the context of zero-sum games, where outcomes vary significantly based on the strategy of the opponent. In this study, we introduce a novel approach that uses unsupervised learning techniques to estimate the exploited level of each trajectory from the offline dataset of zero-sum games made by diverse demonstrators. Subsequently, we incorporate the estimated exploited level into the offline learning to maximize the influence of the dominant strategy. Our method enables interpretable exploited level estimation in multiple zero-sum games and effectively identifies dominant strategy data. Also, our exploited level augmented offline learning significantly enhances the original offline learning algorithms including imitation learning and offline reinforcement learning for zero-sum games.
HiMAP: Learning Heuristics-Informed Policies for Large-Scale Multi-Agent Pathfinding
Feb 23, 2024Large-scale multi-agent pathfinding (MAPF) presents significant challenges in several areas. As systems grow in complexity with a multitude of autonomous agents operating simultaneously, efficient and collision-free coordination becomes paramount. Traditional algorithms often fall short in scalability, especially in intricate scenarios. Reinforcement Learning (RL) has shown potential to address the intricacies of MAPF; however, it has also been shown to struggle with scalability, demanding intricate implementation, lengthy training, and often exhibiting unstable convergence, limiting its practical application. In this paper, we introduce Heuristics-Informed Multi-Agent Pathfinding (HiMAP), a novel scalable approach that employs imitation learning with heuristic guidance in a decentralized manner. We train on small-scale instances using a heuristic policy as a teacher that maps each single agent observation information to an action probability distribution. During pathfinding, we adopt several inference techniques to improve performance. With a simple training scheme and implementation, HiMAP demonstrates competitive results in terms of success rate and scalability in the field of imitation-learning-only MAPF, showing the potential of imitation-learning-only MAPF equipped with inference techniques.
Anfinsen Goes Neural: a Graphical Model for Conditional Antibody Design
Feb 08, 2024Antibody design plays a pivotal role in advancing therapeutics. Although deep learning has made rapid progress in this field, existing methods make limited use of general protein knowledge and assume a graphical model (GM) that violates empirical findings on proteins. To address these limitations, we present Anfinsen Goes Neural (AGN), a graphical model that uses a pre-trained protein language model (pLM) and encodes a seminal finding on proteins called Anfinsen's dogma. Our framework follows a two-step process of sequence generation with pLM and structure prediction with graph neural network (GNN). Experiments show that our approach outperforms state-of-the-art results on benchmark experiments. We also address a critical limitation of non-autoregressive models -- namely, that they tend to generate unrealistic sequences with overly repeating tokens. To resolve this, we introduce a composition-based regularization term to the cross-entropy objective that allows an efficient trade-off between high performance and low token repetition. We demonstrate that our approach establishes a Pareto frontier over the current state-of-the-art. Our code is available at https://github.com/lkny123/AGN.
Genetic-guided GFlowNets: Advancing in Practical Molecular Optimization Benchmark
Feb 05, 2024This paper proposes a novel variant of GFlowNet, genetic-guided GFlowNet (Genetic GFN), which integrates an iterative genetic search into GFlowNet. Genetic search effectively guides the GFlowNet to high-rewarded regions, addressing global over-exploration that results in training inefficiency and exploring limited regions. In addition, training strategies, such as rank-based replay training and unsupervised maximum likelihood pre-training, are further introduced to improve the sample efficiency of Genetic GFN. The proposed method shows a state-of-the-art score of 16.213, significantly outperforming the reported best score in the benchmark of 15.185, in practical molecular optimization (PMO), which is an official benchmark for sample-efficient molecular optimization. Remarkably, ours exceeds all baselines, including reinforcement learning, Bayesian optimization, generative models, GFlowNets, and genetic algorithms, in 14 out of 23 tasks.
Multi-Agent Dynamic Relational Reasoning for Social Robot Navigation
Jan 22, 2024Social robot navigation can be helpful in various contexts of daily life but requires safe human-robot interactions and efficient trajectory planning. While modeling pairwise relations has been widely studied in multi-agent interacting systems, the ability to capture larger-scale group-wise activities is limited. In this paper, we propose a systematic relational reasoning approach with explicit inference of the underlying dynamically evolving relational structures, and we demonstrate its effectiveness for multi-agent trajectory prediction and social robot navigation. In addition to the edges between pairs of nodes (i.e., agents), we propose to infer hyperedges that adaptively connect multiple nodes to enable group-wise reasoning in an unsupervised manner. Our approach infers dynamically evolving relation graphs and hypergraphs to capture the evolution of relations, which the trajectory predictor employs to generate future states. Meanwhile, we propose to regularize the sharpness and sparsity of the learned relations and the smoothness of the relation evolution, which proves to enhance training stability and model performance. The proposed approach is validated on synthetic crowd simulations and real-world benchmark datasets. Experiments demonstrate that the approach infers reasonable relations and achieves state-of-the-art prediction performance. In addition, we present a deep reinforcement learning (DRL) framework for social robot navigation, which incorporates relational reasoning and trajectory prediction systematically. In a group-based crowd simulation, our method outperforms the strongest baseline by a significant margin in terms of safety, efficiency, and social compliance in dense, interactive scenarios.
Interactive Autonomous Navigation with Internal State Inference and Interactivity Estimation
Nov 27, 2023Deep reinforcement learning (DRL) provides a promising way for intelligent agents (e.g., autonomous vehicles) to learn to navigate complex scenarios. However, DRL with neural networks as function approximators is typically considered a black box with little explainability and often suffers from suboptimal performance, especially for autonomous navigation in highly interactive multi-agent environments. To address these issues, we propose three auxiliary tasks with spatio-temporal relational reasoning and integrate them into the standard DRL framework, which improves the decision making performance and provides explainable intermediate indicators. We propose to explicitly infer the internal states (i.e., traits and intentions) of surrounding agents (e.g., human drivers) as well as to predict their future trajectories in the situations with and without the ego agent through counterfactual reasoning. These auxiliary tasks provide additional supervision signals to infer the behavior patterns of other interactive agents. Multiple variants of framework integration strategies are compared. We also employ a spatio-temporal graph neural network to encode relations between dynamic entities, which enhances both internal state inference and decision making of the ego agent. Moreover, we propose an interactivity estimation mechanism based on the difference between predicted trajectories in these two situations, which indicates the degree of influence of the ego agent on other agents. To validate the proposed method, we design an intersection driving simulator based on the Intelligent Intersection Driver Model (IIDM) that simulates vehicles and pedestrians. Our approach achieves robust and state-of-the-art performance in terms of standard evaluation metrics and provides explainable intermediate indicators (i.e., internal states, and interactivity scores) for decision making.
Learning Efficient Surrogate Dynamic Models with Graph Spline Networks
Oct 25, 2023While complex simulations of physical systems have been widely used in engineering and scientific computing, lowering their often prohibitive computational requirements has only recently been tackled by deep learning approaches. In this paper, we present GraphSplineNets, a novel deep-learning method to speed up the forecasting of physical systems by reducing the grid size and number of iteration steps of deep surrogate models. Our method uses two differentiable orthogonal spline collocation methods to efficiently predict response at any location in time and space. Additionally, we introduce an adaptive collocation strategy in space to prioritize sampling from the most important regions. GraphSplineNets improve the accuracy-speedup tradeoff in forecasting various dynamical systems with increasing complexity, including the heat equation, damped wave propagation, Navier-Stokes equations, and real-world ocean currents in both regular and irregular domains.
Genetic Algorithms with Neural Cost Predictor for Solving Hierarchical Vehicle Routing Problems
Oct 22, 2023When vehicle routing decisions are intertwined with higher-level decisions, the resulting optimization problems pose significant challenges for computation. Examples are the multi-depot vehicle routing problem (MDVRP), where customers are assigned to depots before delivery, and the capacitated location routing problem (CLRP), where the locations of depots should be determined first. A simple and straightforward approach for such hierarchical problems would be to separate the higher-level decisions from the complicated vehicle routing decisions. For each higher-level decision candidate, we may evaluate the underlying vehicle routing problems to assess the candidate. As this approach requires solving vehicle routing problems multiple times, it has been regarded as impractical in most cases. We propose a novel deep-learning-based approach called Genetic Algorithm with Neural Cost Predictor (GANCP) to tackle the challenge and simplify algorithm developments. For each higher-level decision candidate, we predict the objective function values of the underlying vehicle routing problems using a pre-trained graph neural network without actually solving the routing problems. In particular, our proposed neural network learns the objective values of the HGS-CVRP open-source package that solves capacitated vehicle routing problems. Our numerical experiments show that this simplified approach is effective and efficient in generating high-quality solutions for both MDVRP and CLRP and has the potential to expedite algorithm developments for complicated hierarchical problems. We provide computational results evaluated in the standard benchmark instances used in the literature.