 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinsu Kim
Addressing Diverging Training Costs using Local Restoration for Precise Bird's Eye View Map Construction
May 02, 2024
Recent advancements in Bird's Eye View (BEV) fusion for map construction have demonstrated remarkable mapping of urban environments. However, their deep and bulky architecture incurs substantial amounts of backpropagation memory and computing latency. Consequently, the problem poses an unavoidable bottleneck in constructing high-resolution (HR) BEV maps, as their large-sized features cause significant increases in costs including GPU memory consumption and computing latency, named diverging training costs issue. Affected by the problem, most existing methods adopt low-resolution (LR) BEV and struggle to estimate the precise locations of urban scene components like road lanes, and sidewalks. As the imprecision leads to risky self-driving, the diverging training costs issue has to be resolved. In this paper, we address the issue with our novel Trumpet Neural Network (TNN) mechanism. The framework utilizes LR BEV space and outputs an up-sampled semantic BEV map to create a memory-efficient pipeline. To this end, we introduce Local Restoration of BEV representation. Specifically, the up-sampled BEV representation has severely aliased, blocky signals, and thick semantic labels. Our proposed Local Restoration restores the signals and thins (or narrows down) the width of the labels. Our extensive experiments show that the TNN mechanism provides a plug-and-play memory-efficient pipeline, thereby enabling the effective estimation of real-sized (or precise) semantic labels for BEV map construction.
Epistemology of Language Models: Do Language Models Have Holistic Knowledge?
Mar 19, 2024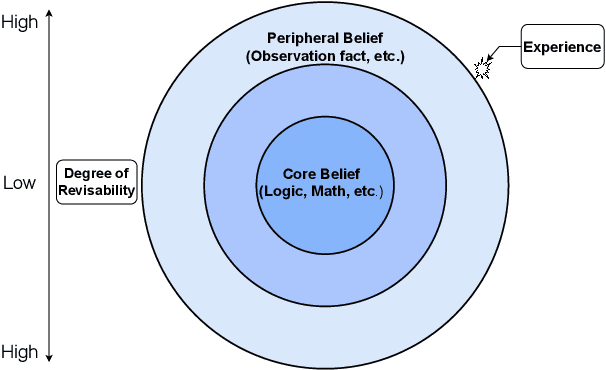
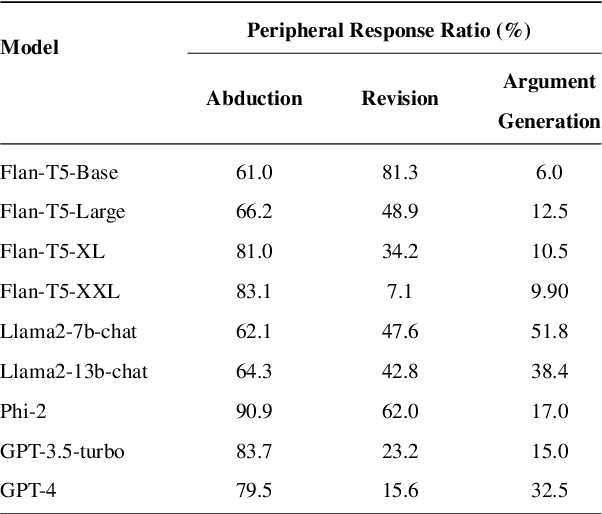
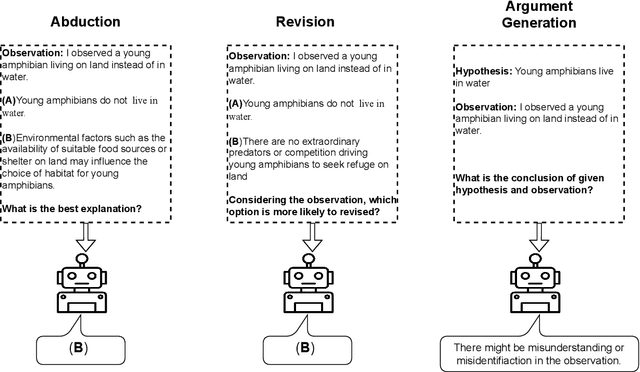
This paper investigates the inherent knowledge in language models from the perspective of epistemological holism. The purpose of this paper is to explore whether LLMs exhibit characteristics consistent with epistemological holism. These characteristics suggest that core knowledge, such as general scientific knowledge, each plays a specific role, serving as the foundation of our knowledge system and being difficult to revise. To assess these traits related to holism, we created a scientific reasoning dataset and examined the epistemology of language models through three tasks: Abduction, Revision, and Argument Generation. In the abduction task, the language models explained situations while avoiding revising the core knowledge. However, in other tasks, the language models were revealed not to distinguish between core and peripheral knowledge, showing an incomplete alignment with holistic knowledge principles.
Accelerating String-Key Learned Index Structures via Memoization-based Incremental Training
Mar 18, 2024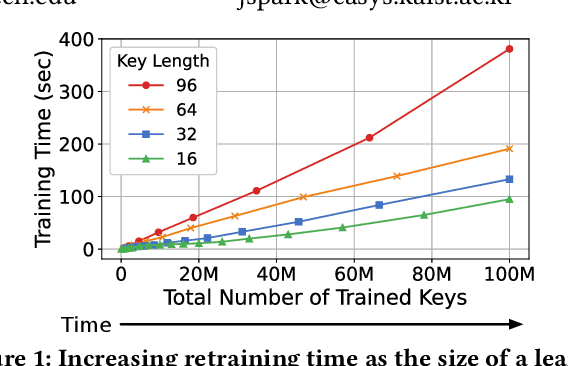
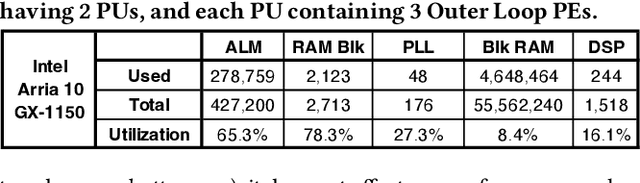
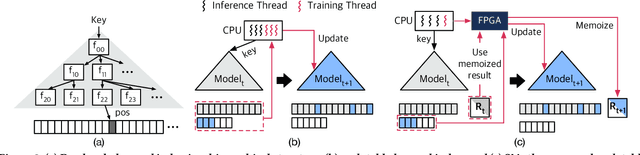
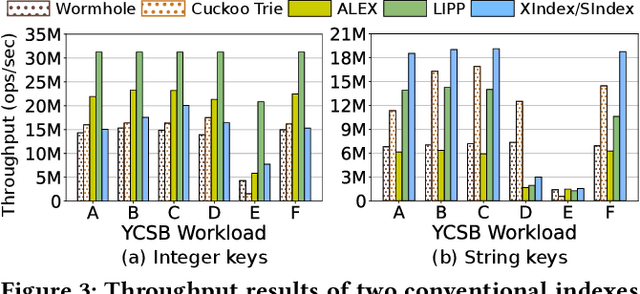
Learned indexes use machine learning models to learn the mappings between keys and their corresponding positions in key-value indexes. These indexes use the mapping information as training data. Learned indexes require frequent retrainings of their models to incorporate the changes introduced by update queries. To efficiently retrain the models, existing learned index systems often harness a linear algebraic QR factorization technique that performs matrix decomposition. This factorization approach processes all key-position pairs during each retraining, resulting in compute operations that grow linearly with the total number of keys and their lengths. Consequently, the retrainings create a severe performance bottleneck, especially for variable-length string keys, while the retrainings are crucial for maintaining high prediction accuracy and in turn, ensuring low query service latency. To address this performance problem, we develop an algorithm-hardware co-designed string-key learned index system, dubbed SIA. In designing SIA, we leverage a unique algorithmic property of the matrix decomposition-based training method. Exploiting the property, we develop a memoization-based incremental training scheme, which only requires computation over updated keys, while decomposition results of non-updated keys from previous computations can be reused. We further enhance SIA to offload a portion of this training process to an FPGA accelerator to not only relieve CPU resources for serving index queries (i.e., inference), but also accelerate the training itself. Our evaluation shows that compared to ALEX, LIPP, and SIndex, a state-of-the-art learned index systems, SIA-accelerated learned indexes offer 2.6x and 3.4x higher throughput on the two real-world benchmark suites, YCSB and Twitter cache trace, respectively.
Ant Colony Sampling with GFlowNets for Combinatorial Optimization
Mar 11, 2024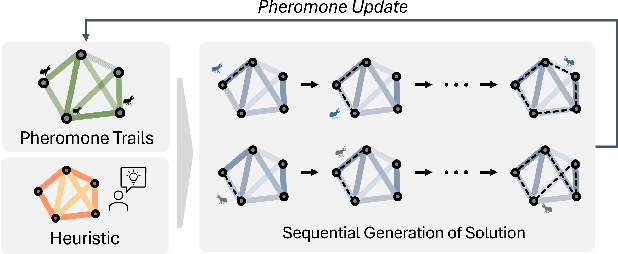
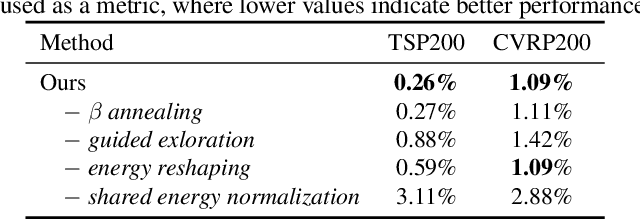
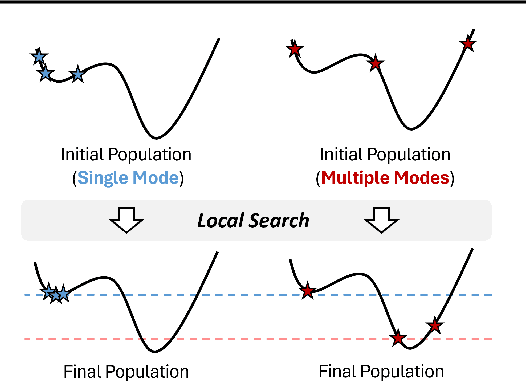
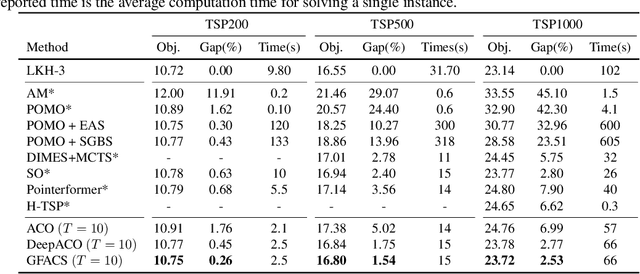
This paper introduces the Generative Flow Ant Colony Sampler (GFACS), a novel neural-guided meta-heuristic algorithm for combinatorial optimization. GFACS integrates generative flow networks (GFlowNets) with the ant colony optimization (ACO) methodology. GFlowNets, a generative model that learns a constructive policy in combinatorial spaces, enhance ACO by providing an informed prior distribution of decision variables conditioned on input graph instances. Furthermore, we introduce a novel combination of training tricks, including search-guided local exploration, energy normalization, and energy shaping to improve GFACS. Our experimental results demonstrate that GFACS outperforms baseline ACO algorithms in seven CO tasks and is competitive with problem-specific heuristics for vehicle routing problems. The source code is available at \url{https://github.com/ai4co/gfacs}.
TMT: Tri-Modal Translation between Speech, Image, and Text by Processing Different Modalities as Different Languages
Feb 25, 2024The capability to jointly process multi-modal information is becoming an essential task. However, the limited number of paired multi-modal data and the large computational requirements in multi-modal learning hinder the development. We propose a novel Tri-Modal Translation (TMT) model that translates between arbitrary modalities spanning speech, image, and text. We introduce a novel viewpoint, where we interpret different modalities as different languages, and treat multi-modal translation as a well-established machine translation problem. To this end, we tokenize speech and image data into discrete tokens, which provide a unified interface across modalities and significantly decrease the computational cost. In the proposed TMT, a multi-modal encoder-decoder conducts the core translation, whereas modality-specific processing is conducted only within the tokenization and detokenization stages. We evaluate the proposed TMT on all six modality translation tasks. TMT outperforms single model counterparts consistently, demonstrating that unifying tasks is beneficial not only for practicality but also for performance.
Where Visual Speech Meets Language: VSP-LLM Framework for Efficient and Context-Aware Visual Speech Processing
Feb 23, 2024In visual speech processing, context modeling capability is one of the most important requirements due to the ambiguous nature of lip movements. For example, homophenes, words that share identical lip movements but produce different sounds, can be distinguished by considering the context. In this paper, we propose a novel framework, namely Visual Speech Processing incorporated with LLMs (VSP-LLM), to maximize the context modeling ability by bringing the overwhelming power of LLMs. Specifically, VSP-LLM is designed to perform multi-tasks of visual speech recognition and translation, where the given instructions control the type of task. The input video is mapped to the input latent space of a LLM by employing a self-supervised visual speech model. Focused on the fact that there is redundant information in input frames, we propose a novel deduplication method that reduces the embedded visual features by employing visual speech units. Through the proposed deduplication and Low Rank Adaptors (LoRA), VSP-LLM can be trained in a computationally efficient manner. In the translation dataset, the MuAViC benchmark, we demonstrate that VSP-LLM can more effectively recognize and translate lip movements with just 15 hours of labeled data, compared to the recent translation model trained with 433 hours of labeld data.
On diffusion models for amortized inference: Benchmarking and improving stochastic control and sampling
Feb 13, 2024We study the problem of training diffusion models to sample from a distribution with a given unnormalized density or energy function. We benchmark several diffusion-structured inference methods, including simulation-based variational approaches and off-policy methods (continuous generative flow networks). Our results shed light on the relative advantages of existing algorithms while bringing into question some claims from past work. We also propose a novel exploration strategy for off-policy methods, based on local search in the target space with the use of a replay buffer, and show that it improves the quality of samples on a variety of target distributions. Our code for the sampling methods and benchmarks studied is made public at https://github.com/GFNOrg/gfn-diffusion as a base for future work on diffusion models for amortized inference.
Anfinsen Goes Neural: a Graphical Model for Conditional Antibody Design
Feb 08, 2024Antibody design plays a pivotal role in advancing therapeutics. Although deep learning has made rapid progress in this field, existing methods make limited use of general protein knowledge and assume a graphical model (GM) that violates empirical findings on proteins. To address these limitations, we present Anfinsen Goes Neural (AGN), a graphical model that uses a pre-trained protein language model (pLM) and encodes a seminal finding on proteins called Anfinsen's dogma. Our framework follows a two-step process of sequence generation with pLM and structure prediction with graph neural network (GNN). Experiments show that our approach outperforms state-of-the-art results on benchmark experiments. We also address a critical limitation of non-autoregressive models -- namely, that they tend to generate unrealistic sequences with overly repeating tokens. To resolve this, we introduce a composition-based regularization term to the cross-entropy objective that allows an efficient trade-off between high performance and low token repetition. We demonstrate that our approach establishes a Pareto frontier over the current state-of-the-art. Our code is available at https://github.com/lkny123/AGN.
Genetic-guided GFlowNets: Advancing in Practical Molecular Optimization Benchmark
Feb 05, 2024This paper proposes a novel variant of GFlowNet, genetic-guided GFlowNet (Genetic GFN), which integrates an iterative genetic search into GFlowNet. Genetic search effectively guides the GFlowNet to high-rewarded regions, addressing global over-exploration that results in training inefficiency and exploring limited regions. In addition, training strategies, such as rank-based replay training and unsupervised maximum likelihood pre-training, are further introduced to improve the sample efficiency of Genetic GFN. The proposed method shows a state-of-the-art score of 16.213, significantly outperforming the reported best score in the benchmark of 15.185, in practical molecular optimization (PMO), which is an official benchmark for sample-efficient molecular optimization. Remarkably, ours exceeds all baselines, including reinforcement learning, Bayesian optimization, generative models, GFlowNets, and genetic algorithms, in 14 out of 23 tasks.
Multilingual Visual Speech Recognition with a Single Model by Learning with Discrete Visual Speech Units
Jan 18, 2024This paper explores sentence-level Multilingual Visual Speech Recognition with a single model for the first time. As the massive multilingual modeling of visual data requires huge computational costs, we propose a novel strategy, processing with visual speech units. Motivated by the recent success of the audio speech unit, the proposed visual speech unit is obtained by discretizing the visual speech features extracted from the self-supervised visual speech model. To correctly capture multilingual visual speech, we first train the self-supervised visual speech model on 5,512 hours of multilingual audio-visual data. Through analysis, we verify that the visual speech units mainly contain viseme information while suppressing non-linguistic information. By using the visual speech units as the inputs of our system, we pre-train the model to predict corresponding text outputs on massive multilingual data constructed by merging several VSR databases. As both the inputs and outputs are discrete, we can greatly improve the training efficiency compared to the standard VSR training. Specifically, the input data size is reduced to 0.016% of the original video inputs. In order to complement the insufficient visual information in speech recognition, we apply curriculum learning where the inputs of the system begin with audio-visual speech units and gradually change to visual speech units. After pre-training, the model is finetuned on continuous features. We set new state-of-the-art multilingual VSR performances by achieving comparable performances to the previous language-specific VSR models, with a single trained model.