 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSamuel Coward
JaxUED: A simple and useable UED library in Jax
Mar 19, 2024
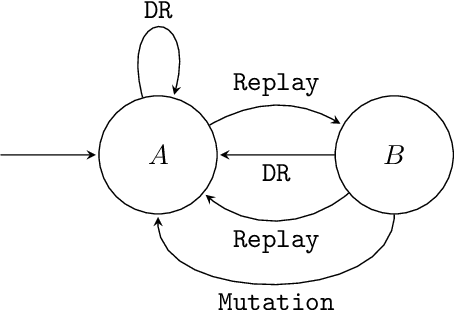
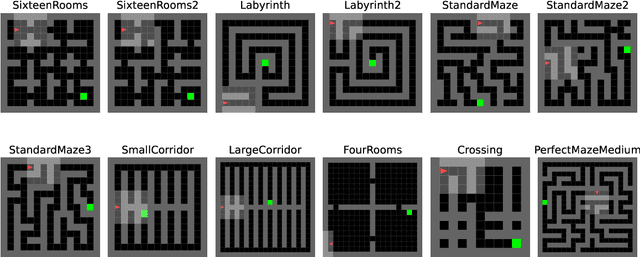

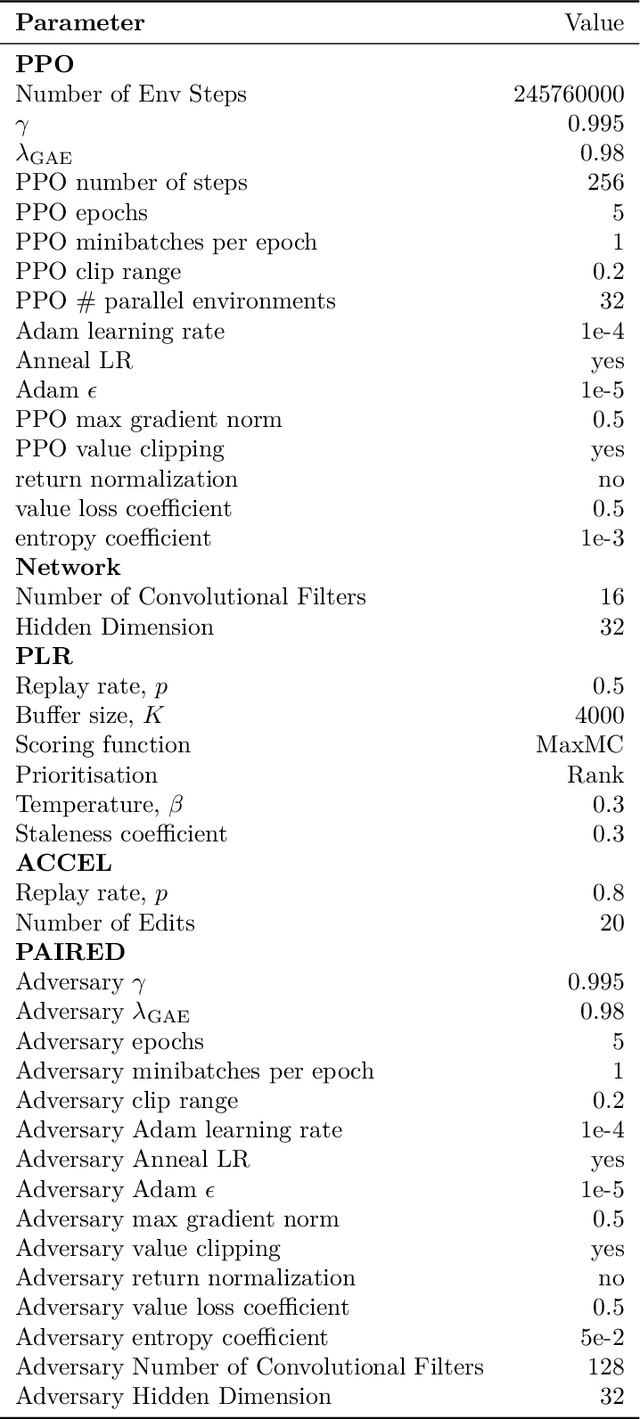
We present JaxUED, an open-source library providing minimal dependency implementations of modern Unsupervised Environment Design (UED) algorithms in Jax. JaxUED leverages hardware acceleration to obtain on the order of 100x speedups compared to prior, CPU-based implementations. Inspired by CleanRL, we provide fast, clear, understandable, and easily modifiable implementations, with the aim of accelerating research into UED. This paper describes our library and contains baseline results. Code can be found at https://github.com/DramaCow/jaxued.
Craftax: A Lightning-Fast Benchmark for Open-Ended Reinforcement Learning
Feb 26, 2024Benchmarks play a crucial role in the development and analysis of reinforcement learning (RL) algorithms. We identify that existing benchmarks used for research into open-ended learning fall into one of two categories. Either they are too slow for meaningful research to be performed without enormous computational resources, like Crafter, NetHack and Minecraft, or they are not complex enough to pose a significant challenge, like Minigrid and Procgen. To remedy this, we first present Craftax-Classic: a ground-up rewrite of Crafter in JAX that runs up to 250x faster than the Python-native original. A run of PPO using 1 billion environment interactions finishes in under an hour using only a single GPU and averages 90% of the optimal reward. To provide a more compelling challenge we present the main Craftax benchmark, a significant extension of the Crafter mechanics with elements inspired from NetHack. Solving Craftax requires deep exploration, long term planning and memory, as well as continual adaptation to novel situations as more of the world is discovered. We show that existing methods including global and episodic exploration, as well as unsupervised environment design fail to make material progress on the benchmark. We believe that Craftax can for the first time allow researchers to experiment in a complex, open-ended environment with limited computational resources.
Refining Minimax Regret for Unsupervised Environment Design
Feb 19, 2024In unsupervised environment design, reinforcement learning agents are trained on environment configurations (levels) generated by an adversary that maximises some objective. Regret is a commonly used objective that theoretically results in a minimax regret (MMR) policy with desirable robustness guarantees; in particular, the agent's maximum regret is bounded. However, once the agent reaches this regret bound on all levels, the adversary will only sample levels where regret cannot be further reduced. Although there are possible performance improvements to be made outside of these regret-maximising levels, learning stagnates. In this work, we introduce Bayesian level-perfect MMR (BLP), a refinement of the minimax regret objective that overcomes this limitation. We formally show that solving for this objective results in a subset of MMR policies, and that BLP policies act consistently with a Perfect Bayesian policy over all levels. We further introduce an algorithm, ReMiDi, that results in a BLP policy at convergence. We empirically demonstrate that training on levels from a minimax regret adversary causes learning to prematurely stagnate, but that ReMiDi continues learning.
SEER: Super-Optimization Explorer for HLS using E-graph Rewriting with MLIR
Aug 15, 2023High-level synthesis (HLS) is a process that automatically translates a software program in a high-level language into a low-level hardware description. However, the hardware designs produced by HLS tools still suffer from a significant performance gap compared to manual implementations. This is because the input HLS programs must still be written using hardware design principles. Existing techniques either leave the program source unchanged or perform a fixed sequence of source transformation passes, potentially missing opportunities to find the optimal design. We propose a super-optimization approach for HLS that automatically rewrites an arbitrary software program into efficient HLS code that can be used to generate an optimized hardware design. We developed a toolflow named SEER, based on the e-graph data structure, to efficiently explore equivalent implementations of a program at scale. SEER provides an extensible framework, orchestrating existing software compiler passes and hardware synthesis optimizers. Our work is the first attempt to exploit e-graph rewriting for large software compiler frameworks, such as MLIR. Across a set of open-source benchmarks, we show that SEER achieves up to 38x the performance within 1.4x the area of the original program. Via an Intel-provided case study, SEER demonstrates the potential to outperform manually optimized designs produced by hardware experts.
Abstract Interpretation on E-Graphs
Mar 17, 2022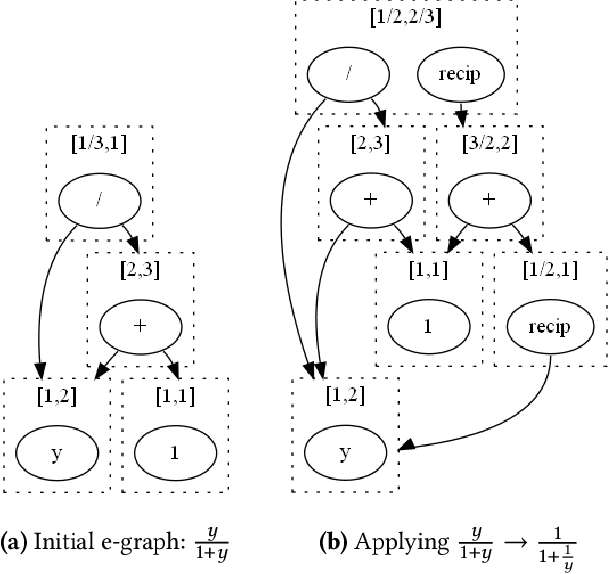

Recent e-graph applications have typically considered concrete semantics of expressions, where the notion of equivalence stems from concrete interpretation of expressions. However, equivalences that hold over one interpretation may not hold in an alternative interpretation. Such an observation can be exploited. We consider the application of abstract interpretation to e-graphs, and show that within an e-graph, the lattice meet operation associated with the abstract domain has a natural interpretation for an e-class, leading to improved precision in over-approximation. In this extended abstract, we use Interval Arithmetic (IA) to illustrate this point.
Attention-Based Clustering: Learning a Kernel from Context
Oct 02, 2020



In machine learning, no data point stands alone. We believe that context is an underappreciated concept in many machine learning methods. We propose Attention-Based Clustering (ABC), a neural architecture based on the attention mechanism, which is designed to learn latent representations that adapt to context within an input set, and which is inherently agnostic to input sizes and number of clusters. By learning a similarity kernel, our method directly combines with any out-of-the-box kernel-based clustering approach. We present competitive results for clustering Omniglot characters and include analytical evidence of the effectiveness of an attention-based approach for clustering.