 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJohan Obando-Ceron
In deep reinforcement learning, a pruned network is a good network
Feb 19, 2024
Recent work has shown that deep reinforcement learning agents have difficulty in effectively using their network parameters. We leverage prior insights into the advantages of sparse training techniques and demonstrate that gradual magnitude pruning enables agents to maximize parameter effectiveness. This results in networks that yield dramatic performance improvements over traditional networks and exhibit a type of "scaling law", using only a small fraction of the full network parameters.
Mixtures of Experts Unlock Parameter Scaling for Deep RL
Feb 13, 2024The recent rapid progress in (self) supervised learning models is in large part predicted by empirical scaling laws: a model's performance scales proportionally to its size. Analogous scaling laws remain elusive for reinforcement learning domains, however, where increasing the parameter count of a model often hurts its final performance. In this paper, we demonstrate that incorporating Mixture-of-Expert (MoE) modules, and in particular Soft MoEs (Puigcerver et al., 2023), into value-based networks results in more parameter-scalable models, evidenced by substantial performance increases across a variety of training regimes and model sizes. This work thus provides strong empirical evidence towards developing scaling laws for reinforcement learning.
Small batch deep reinforcement learning
Oct 05, 2023In value-based deep reinforcement learning with replay memories, the batch size parameter specifies how many transitions to sample for each gradient update. Although critical to the learning process, this value is typically not adjusted when proposing new algorithms. In this work we present a broad empirical study that suggests {\em reducing} the batch size can result in a number of significant performance gains; this is surprising, as the general tendency when training neural networks is towards larger batch sizes for improved performance. We complement our experimental findings with a set of empirical analyses towards better understanding this phenomenon.
Bigger, Better, Faster: Human-level Atari with human-level efficiency
Jun 09, 2023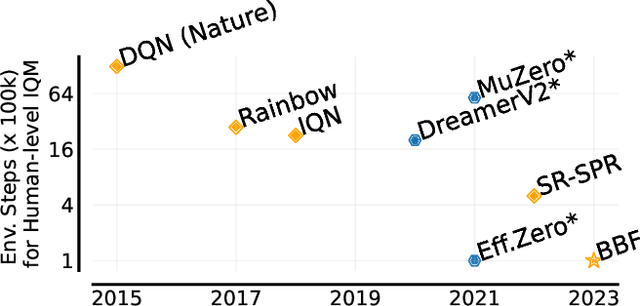
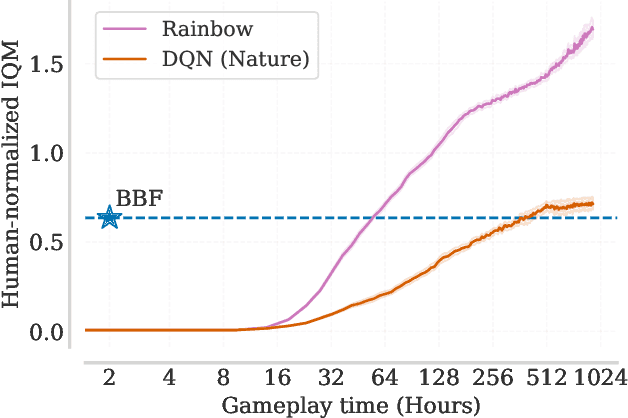
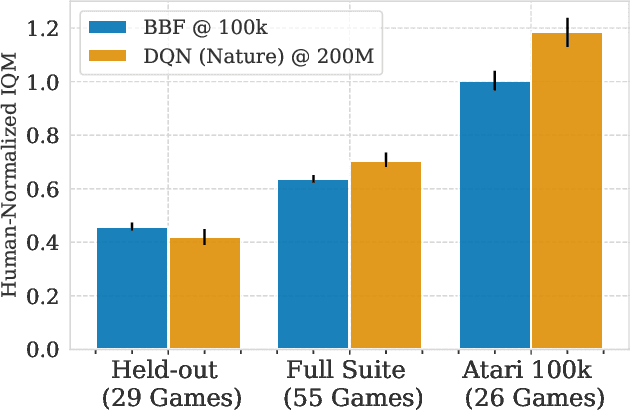
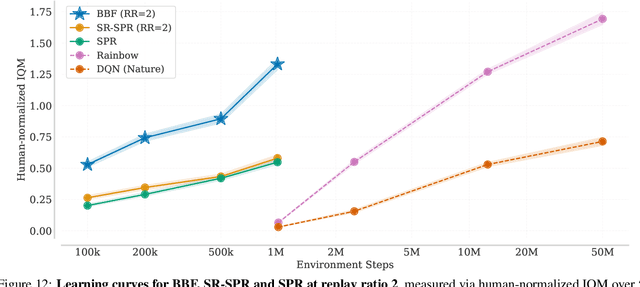
We introduce a value-based RL agent, which we call BBF, that achieves super-human performance in the Atari 100K benchmark. BBF relies on scaling the neural networks used for value estimation, as well as a number of other design choices that enable this scaling in a sample-efficient manner. We conduct extensive analyses of these design choices and provide insights for future work. We end with a discussion about updating the goalposts for sample-efficient RL research on the ALE. We make our code and data publicly available at https://github.com/google-research/google-research/tree/master/bigger_better_faster.
JaxPruner: A concise library for sparsity research
May 02, 2023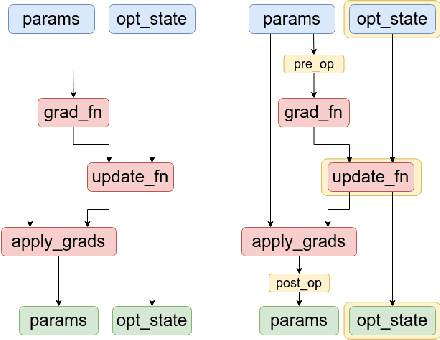
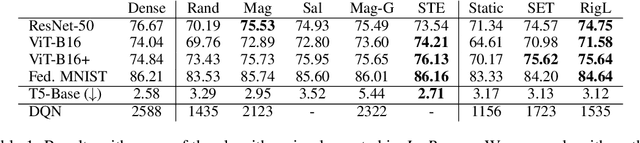
This paper introduces JaxPruner, an open-source JAX-based pruning and sparse training library for machine learning research. JaxPruner aims to accelerate research on sparse neural networks by providing concise implementations of popular pruning and sparse training algorithms with minimal memory and latency overhead. Algorithms implemented in JaxPruner use a common API and work seamlessly with the popular optimization library Optax, which, in turn, enables easy integration with existing JAX based libraries. We demonstrate this ease of integration by providing examples in four different codebases: Scenic, t5x, Dopamine and FedJAX and provide baseline experiments on popular benchmarks.