 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJunpeng Liu
VisualWebBench: How Far Have Multimodal LLMs Evolved in Web Page Understanding and Grounding?
Apr 09, 2024
Multimodal Large Language models (MLLMs) have shown promise in web-related tasks, but evaluating their performance in the web domain remains a challenge due to the lack of comprehensive benchmarks. Existing benchmarks are either designed for general multimodal tasks, failing to capture the unique characteristics of web pages, or focus on end-to-end web agent tasks, unable to measure fine-grained abilities such as OCR, understanding, and grounding. In this paper, we introduce \bench{}, a multimodal benchmark designed to assess the capabilities of MLLMs across a variety of web tasks. \bench{} consists of seven tasks, and comprises 1.5K human-curated instances from 139 real websites, covering 87 sub-domains. We evaluate 14 open-source MLLMs, Gemini Pro, Claude-3 series, and GPT-4V(ision) on \bench{}, revealing significant challenges and performance gaps. Further analysis highlights the limitations of current MLLMs, including inadequate grounding in text-rich environments and subpar performance with low-resolution image inputs. We believe \bench{} will serve as a valuable resource for the research community and contribute to the creation of more powerful and versatile MLLMs for web-related applications.
Topic-Aware Contrastive Learning for Abstractive Dialogue Summarization
Sep 10, 2021
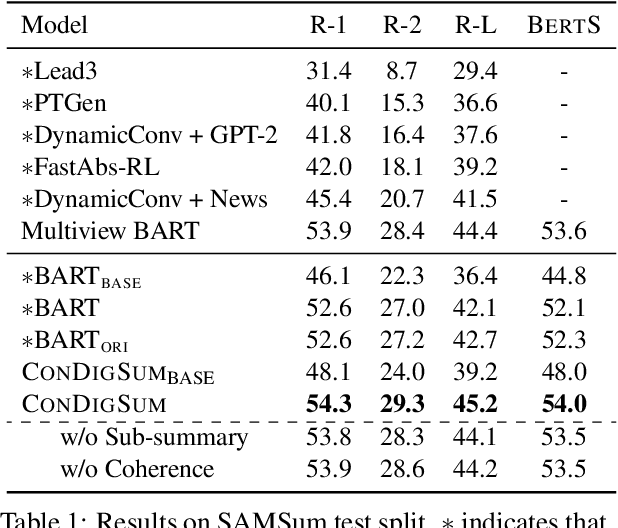
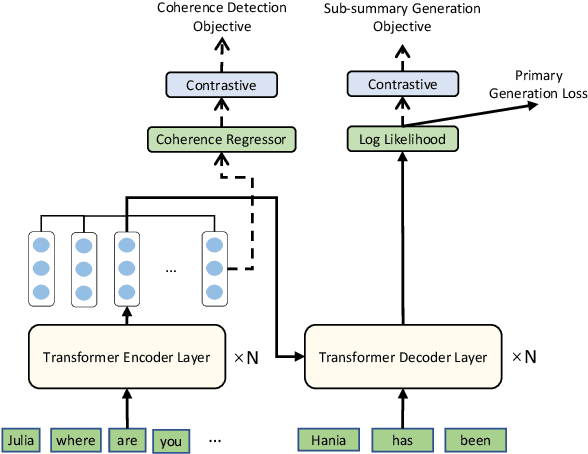
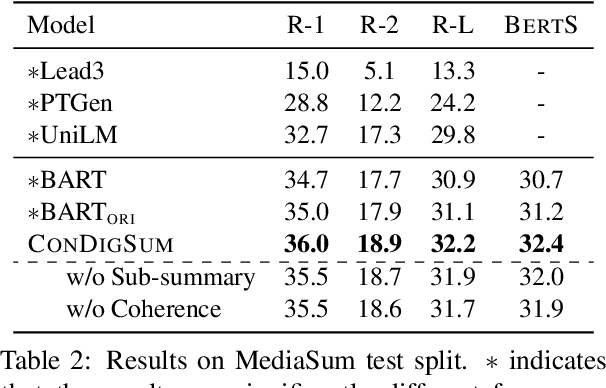
Unlike well-structured text, such as news reports and encyclopedia articles, dialogue content often comes from two or more interlocutors, exchanging information with each other. In such a scenario, the topic of a conversation can vary upon progression and the key information for a certain topic is often scattered across multiple utterances of different speakers, which poses challenges to abstractly summarize dialogues. To capture the various topic information of a conversation and outline salient facts for the captured topics, this work proposes two topic-aware contrastive learning objectives, namely coherence detection and sub-summary generation objectives, which are expected to implicitly model the topic change and handle information scattering challenges for the dialogue summarization task. The proposed contrastive objectives are framed as auxiliary tasks for the primary dialogue summarization task, united via an alternative parameter updating strategy. Extensive experiments on benchmark datasets demonstrate that the proposed simple method significantly outperforms strong baselines and achieves new state-of-the-art performance. The code and trained models are publicly available via \href{https://github.com/Junpliu/ConDigSum}{https://github.com/Junpliu/ConDigSum}.