 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeqi Lin
Make Your LLM Fully Utilize the Context
Apr 26, 2024
While many contemporary large language models (LLMs) can process lengthy input, they still struggle to fully utilize information within the long context, known as the lost-in-the-middle challenge. We hypothesize that it stems from insufficient explicit supervision during the long-context training, which fails to emphasize that any position in a long context can hold crucial information. Based on this intuition, our study presents information-intensive (IN2) training, a purely data-driven solution to overcome lost-in-the-middle. Specifically, IN2 training leverages a synthesized long-context question-answer dataset, where the answer requires (1) fine-grained information awareness on a short segment (~128 tokens) within a synthesized long context (4K-32K tokens), and (2) the integration and reasoning of information from two or more short segments. Through applying this information-intensive training on Mistral-7B, we present FILM-7B (FILl-in-the-Middle). To thoroughly assess the ability of FILM-7B for utilizing long contexts, we design three probing tasks that encompass various context styles (document, code, and structured-data context) and information retrieval patterns (forward, backward, and bi-directional retrieval). The probing results demonstrate that FILM-7B can robustly retrieve information from different positions in its 32K context window. Beyond these probing tasks, FILM-7B significantly improves the performance on real-world long-context tasks (e.g., 23.5->26.9 F1 score on NarrativeQA), while maintaining a comparable performance on short-context tasks (e.g., 59.3->59.2 accuracy on MMLU). Github Link: https://github.com/microsoft/FILM.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
Compositional API Recommendation for Library-Oriented Code Generation
Feb 29, 2024Large language models (LLMs) have achieved exceptional performance in code generation. However, the performance remains unsatisfactory in generating library-oriented code, especially for the libraries not present in the training data of LLMs. Previous work utilizes API recommendation technology to help LLMs use libraries: it retrieves APIs related to the user requirements, then leverages them as context to prompt LLMs. However, developmental requirements can be coarse-grained, requiring a combination of multiple fine-grained APIs. This granularity inconsistency makes API recommendation a challenging task. To address this, we propose CAPIR (Compositional API Recommendation), which adopts a "divide-and-conquer" strategy to recommend APIs for coarse-grained requirements. Specifically, CAPIR employs an LLM-based Decomposer to break down a coarse-grained task description into several detailed subtasks. Then, CAPIR applies an embedding-based Retriever to identify relevant APIs corresponding to each subtask. Moreover, CAPIR leverages an LLM-based Reranker to filter out redundant APIs and provides the final recommendation. To facilitate the evaluation of API recommendation methods on coarse-grained requirements, we present two challenging benchmarks, RAPID (Recommend APIs based on Documentation) and LOCG (Library-Oriented Code Generation). Experimental results on these benchmarks, demonstrate the effectiveness of CAPIR in comparison to existing baselines. Specifically, on RAPID's Torchdata-AR dataset, compared to the state-of-the-art API recommendation approach, CAPIR improves recall@5 from 18.7% to 43.2% and precision@5 from 15.5% to 37.1%. On LOCG's Torchdata-Code dataset, compared to code generation without API recommendation, CAPIR improves pass@100 from 16.0% to 28.0%.
Learning From Mistakes Makes LLM Better Reasoner
Nov 14, 2023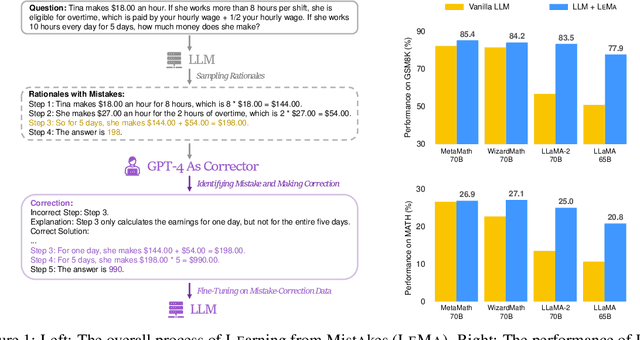
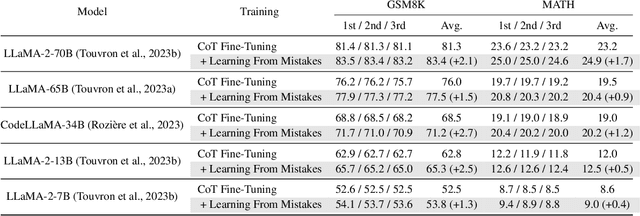
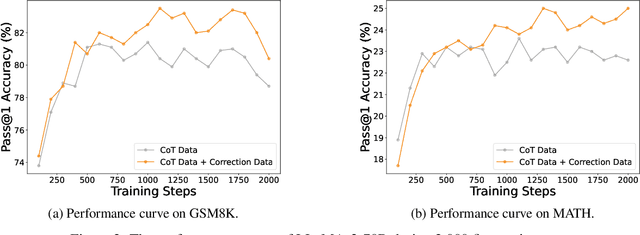
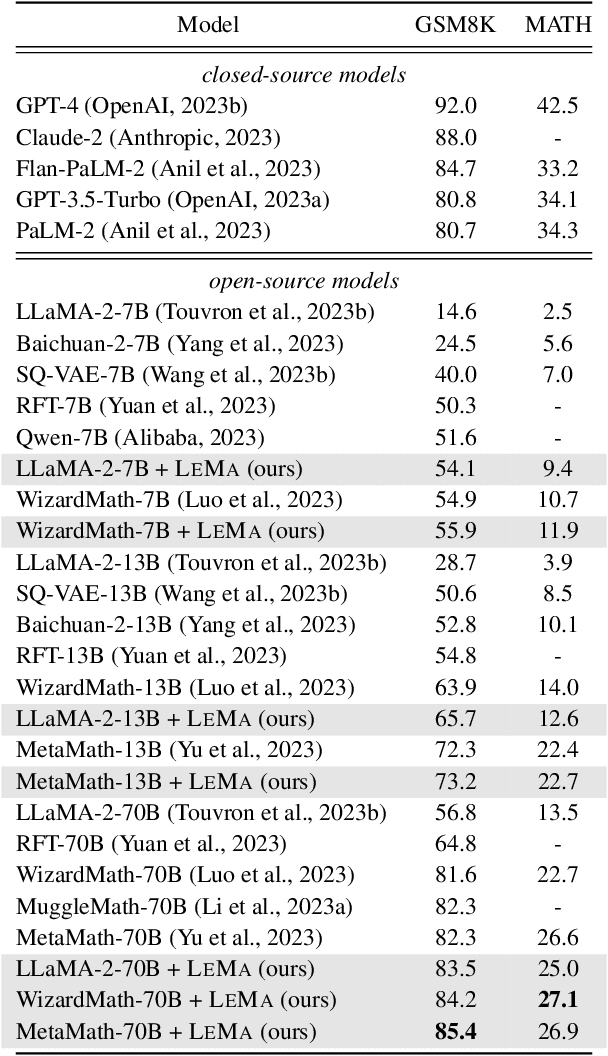
Large language models (LLMs) recently exhibited remarkable reasoning capabilities on solving math problems. To further improve this capability, this work proposes Learning from Mistakes (LeMa), akin to human learning processes. Consider a human student who failed to solve a math problem, he will learn from what mistake he has made and how to correct it. Mimicking this error-driven learning process, LeMa fine-tunes LLMs on mistake-correction data pairs generated by GPT-4. Specifically, we first collect inaccurate reasoning paths from various LLMs and then employ GPT-4 as a "corrector" to (1) identify the mistake step, (2) explain the reason for the mistake, and (3) correct the mistake and generate the final answer. Experimental results demonstrate the effectiveness of LeMa: across five backbone LLMs and two mathematical reasoning tasks, LeMa consistently improves the performance compared with fine-tuning on CoT data alone. Impressively, LeMa can also benefit specialized LLMs such as WizardMath and MetaMath, achieving 85.4% pass@1 accuracy on GSM8K and 27.1% on MATH. This surpasses the SOTA performance achieved by non-execution open-source models on these challenging tasks. Our code, data and models will be publicly available at https://github.com/microsoft/LEMA.
Skill-Based Few-Shot Selection for In-Context Learning
May 23, 2023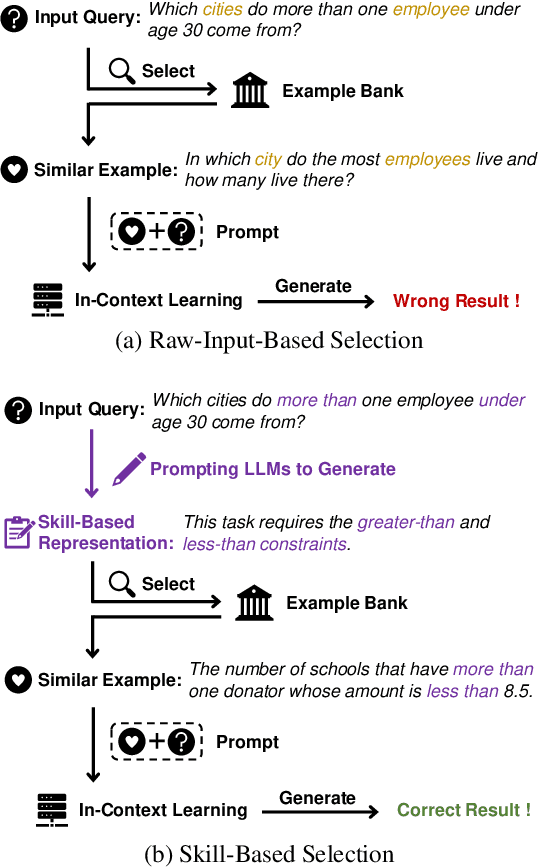



In-Context learning is the paradigm that adapts large language models to downstream tasks by providing a few examples. Few-shot selection -- selecting appropriate examples for each test instance separately -- is important for in-context learning. In this paper, we propose Skill-KNN, a skill-based few-shot selection method for in-context learning. The key advantages of Skill-KNN include: (1) it addresses the problem that existing methods based on pre-trained embeddings can be easily biased by surface natural language features that are not important for the target task; (2) it does not require training or fine-tuning of any models, making it suitable for frequently expanding or changing example banks. The key insight is to optimize the inputs fed into the embedding model, rather than tuning the model itself. Technically, Skill-KNN generates the skill-based representations for each test case and candidate example by utilizing a pre-processing few-shot prompting, thus eliminating unimportant surface features. Experimental results across four cross-domain semantic parsing tasks and four backbone models show that Skill-KNN significantly outperforms existing methods.
How Do In-Context Examples Affect Compositional Generalization?
May 08, 2023

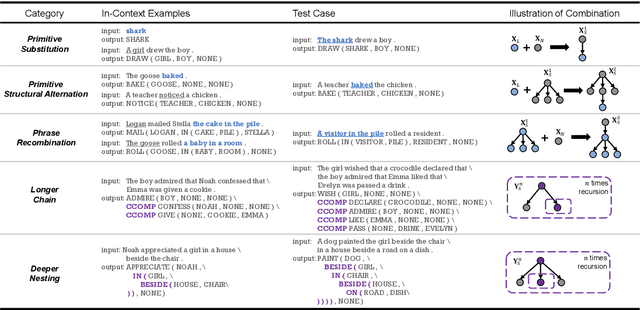

Compositional generalization--understanding unseen combinations of seen primitives--is an essential reasoning capability in human intelligence. The AI community mainly studies this capability by fine-tuning neural networks on lots of training samples, while it is still unclear whether and how in-context learning--the prevailing few-shot paradigm based on large language models--exhibits compositional generalization. In this paper, we present CoFe, a test suite to investigate in-context compositional generalization. We find that the compositional generalization performance can be easily affected by the selection of in-context examples, thus raising the research question what the key factors are to make good in-context examples for compositional generalization. We study three potential factors: similarity, diversity and complexity. Our systematic experiments indicate that in-context examples should be structurally similar to the test case, diverse from each other, and individually simple. Furthermore, two strong limitations are observed: in-context compositional generalization on fictional words is much weaker than that on commonly used ones; it is still critical that the in-context examples should cover required linguistic structures, even though the backbone model has been pre-trained on large corpus. We hope our analysis would facilitate the understanding and utilization of in-context learning paradigm.
Does Deep Learning Learn to Abstract? A Systematic Probing Framework
Feb 23, 2023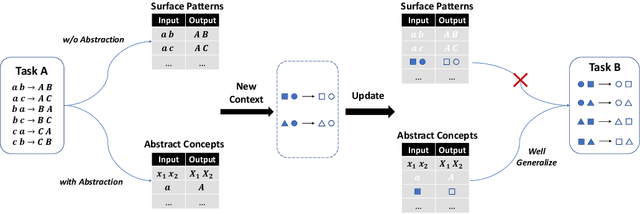

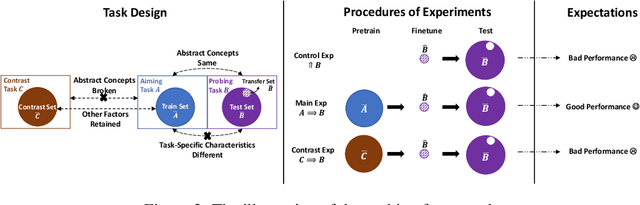

Abstraction is a desirable capability for deep learning models, which means to induce abstract concepts from concrete instances and flexibly apply them beyond the learning context. At the same time, there is a lack of clear understanding about both the presence and further characteristics of this capability in deep learning models. In this paper, we introduce a systematic probing framework to explore the abstraction capability of deep learning models from a transferability perspective. A set of controlled experiments are conducted based on this framework, providing strong evidence that two probed pre-trained language models (PLMs), T5 and GPT2, have the abstraction capability. We also conduct in-depth analysis, thus shedding further light: (1) the whole training phase exhibits a "memorize-then-abstract" two-stage process; (2) the learned abstract concepts are gathered in a few middle-layer attention heads, rather than being evenly distributed throughout the model; (3) the probed abstraction capabilities exhibit robustness against concept mutations, and are more robust to low-level/source-side mutations than high-level/target-side ones; (4) generic pre-training is critical to the emergence of abstraction capability, and PLMs exhibit better abstraction with larger model sizes and data scales.
When Language Model Meets Private Library
Oct 31, 2022



With the rapid development of pre-training techniques, a number of language models have been pre-trained on large-scale code corpora and perform well in code generation. In this paper, we investigate how to equip pre-trained language models with the ability of code generation for private libraries. In practice, it is common for programmers to write code using private libraries. However, this is a challenge for language models since they have never seen private APIs during training. Motivated by the fact that private libraries usually come with elaborate API documentation, we propose a novel framework with two modules: the APIRetriever finds useful APIs, and then the APICoder generates code using these APIs. For APIRetriever, we present a dense retrieval system and also design a friendly interaction to involve uses. For APICoder, we can directly use off-the-shelf language models, or continually pre-train the base model on a code corpus containing API information. Both modules are trained with data from public libraries and can be generalized to private ones. Furthermore, we craft three benchmarks for private libraries, named TorchDataEval, MonkeyEval, and BeatNumEval. Experimental results demonstrate the impressive performance of our framework.
CodeT: Code Generation with Generated Tests
Jul 21, 2022



Given a programming problem, pre-trained language models such as Codex have demonstrated the ability to generate multiple different code solutions via sampling. However, selecting a correct or best solution from those samples still remains a challenge. While an easy way to verify the correctness of a code solution is through executing test cases, producing high-quality test cases is prohibitively expensive. In this paper, we explore the use of pre-trained language models to automatically generate test cases, calling our method CodeT: Code generation with generated Tests. CodeT executes the code solutions using the generated test cases, and then chooses the best solution based on a dual execution agreement with both the generated test cases and other generated solutions. We evaluate CodeT on five different pre-trained models with both HumanEval and MBPP benchmarks. Extensive experimental results demonstrate CodeT can achieve significant, consistent, and surprising improvements over previous methods. For example, CodeT improves the pass@1 on HumanEval to 65.8%, an increase of absolute 18.8% on the code-davinci-002 model, and an absolute 20+% improvement over previous state-of-the-art results.
CERT: Continual Pre-Training on Sketches for Library-Oriented Code Generation
Jun 14, 2022



Code generation is a longstanding challenge, aiming to generate a code snippet based on a natural language description. Usually, expensive text-code paired data is essential for training a code generation model. Recently, thanks to the success of pre-training techniques, large language models are trained on large-scale unlabelled code corpora and perform well in code generation. In this paper, we investigate how to leverage an unlabelled code corpus to train a model for library-oriented code generation. Since it is a common practice for programmers to reuse third-party libraries, in which case the text-code paired data are harder to obtain due to the huge number of libraries. We observe that library-oriented code snippets are more likely to share similar code sketches. Hence, we present CERT with two steps: a sketcher generates the sketch, then a generator fills the details in the sketch. Both the sketcher and the generator are continually pre-trained upon a base model using unlabelled data. Furthermore, we craft two benchmarks named PandasEval and NumpyEval to evaluate library-oriented code generation. Experimental results demonstrate the impressive performance of CERT. For example, it surpasses the base model by an absolute 15.67% improvement in terms of pass@1 on PandasEval. Our work is available at https://github.com/microsoft/PyCodeGPT.