 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorby Rosset
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024
We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
Direct Nash Optimization: Teaching Language Models to Self-Improve with General Preferences
Apr 04, 2024This paper studies post-training large language models (LLMs) using preference feedback from a powerful oracle to help a model iteratively improve over itself. The typical approach for post-training LLMs involves Reinforcement Learning from Human Feedback (RLHF), which traditionally separates reward learning and subsequent policy optimization. However, such a reward maximization approach is limited by the nature of "point-wise" rewards (such as Bradley-Terry model), which fails to express complex intransitive or cyclic preference relations. While advances on RLHF show reward learning and policy optimization can be merged into a single contrastive objective for stability, they yet still remain tethered to the reward maximization framework. Recently, a new wave of research sidesteps the reward maximization presumptions in favor of directly optimizing over "pair-wise" or general preferences. In this paper, we introduce Direct Nash Optimization (DNO), a provable and scalable algorithm that marries the simplicity and stability of contrastive learning with theoretical generality from optimizing general preferences. Because DNO is a batched on-policy algorithm using a regression-based objective, its implementation is straightforward and efficient. Moreover, DNO enjoys monotonic improvement across iterations that help it improve even over a strong teacher (such as GPT-4). In our experiments, a resulting 7B parameter Orca-2.5 model aligned by DNO achieves the state-of-the-art win-rate against GPT-4-Turbo of 33% on AlpacaEval 2.0 (even after controlling for response length), an absolute gain of 26% (7% to 33%) over the initializing model. It outperforms models with far more parameters, including Mistral Large, Self-Rewarding LM (70B parameters), and older versions of GPT-4.
Researchy Questions: A Dataset of Multi-Perspective, Decompositional Questions for LLM Web Agents
Feb 27, 2024Existing question answering (QA) datasets are no longer challenging to most powerful Large Language Models (LLMs). Traditional QA benchmarks like TriviaQA, NaturalQuestions, ELI5 and HotpotQA mainly study ``known unknowns'' with clear indications of both what information is missing, and how to find it to answer the question. Hence, good performance on these benchmarks provides a false sense of security. A yet unmet need of the NLP community is a bank of non-factoid, multi-perspective questions involving a great deal of unclear information needs, i.e. ``unknown uknowns''. We claim we can find such questions in search engine logs, which is surprising because most question-intent queries are indeed factoid. We present Researchy Questions, a dataset of search engine queries tediously filtered to be non-factoid, ``decompositional'' and multi-perspective. We show that users spend a lot of ``effort'' on these questions in terms of signals like clicks and session length, and that they are also challenging for GPT-4. We also show that ``slow thinking'' answering techniques, like decomposition into sub-questions shows benefit over answering directly. We release $\sim$ 100k Researchy Questions, along with the Clueweb22 URLs that were clicked.
Orca-Math: Unlocking the potential of SLMs in Grade School Math
Feb 16, 2024Mathematical word problem-solving has long been recognized as a complex task for small language models (SLMs). A recent study hypothesized that the smallest model size, needed to achieve over 80% accuracy on the GSM8K benchmark, is 34 billion parameters. To reach this level of performance with smaller models, researcher often train SLMs to generate Python code or use tools to help avoid calculation errors. Additionally, they employ ensembling, where outputs of up to 100 model runs are combined to arrive at a more accurate result. Result selection is done using consensus, majority vote or a separate a verifier model used in conjunction with the SLM. Ensembling provides a substantial boost in accuracy but at a significant cost increase with multiple calls to the model (e.g., Phi-GSM uses top-48 to boost the performance from 68.2 to 81.5). In this work, we present Orca-Math, a 7-billion-parameter SLM based on the Mistral-7B, which achieves 86.81% on GSM8k without the need for multiple model calls or the use of verifiers, code execution or any other external tools. Our approach has the following key elements: (1) A high quality synthetic dataset of 200K math problems created using a multi-agent setup where agents collaborate to create the data, (2) An iterative learning techniques that enables the SLM to practice solving problems, receive feedback on its solutions and learn from preference pairs incorporating the SLM solutions and the feedback. When trained with Supervised Fine-Tuning alone, Orca-Math achieves 81.50% on GSM8k pass@1 metric. With iterative preference learning, Orca-Math achieves 86.81% pass@1. Orca-Math surpasses the performance of significantly larger models such as LLAMA-2-70B, WizardMath-70B, Gemini-Pro, ChatGPT-3.5. It also significantly outperforms other smaller models while using much smaller data (hundreds of thousands vs. millions of problems).
Axiomatic Preference Modeling for Longform Question Answering
Dec 02, 2023The remarkable abilities of large language models (LLMs) like GPT-4 partially stem from post-training processes like Reinforcement Learning from Human Feedback (RLHF) involving human preferences encoded in a reward model. However, these reward models (RMs) often lack direct knowledge of why, or under what principles, the preferences annotations were made. In this study, we identify principles that guide RMs to better align with human preferences, and then develop an axiomatic framework to generate a rich variety of preference signals to uphold them. We use these axiomatic signals to train a model for scoring answers to longform questions. Our approach yields a Preference Model with only about 220M parameters that agrees with gold human-annotated preference labels more often than GPT-4. The contributions of this work include: training a standalone preference model that can score human- and LLM-generated answers on the same scale; developing an axiomatic framework for generating training data pairs tailored to certain principles; and showing that a small amount of axiomatic signals can help small models outperform GPT-4 in preference scoring. We release our model on huggingface: https://huggingface.co/corbyrosset/axiomatic_preference_model
Orca 2: Teaching Small Language Models How to Reason
Nov 21, 2023Orca 1 learns from rich signals, such as explanation traces, allowing it to outperform conventional instruction-tuned models on benchmarks like BigBench Hard and AGIEval. In Orca 2, we continue exploring how improved training signals can enhance smaller LMs' reasoning abilities. Research on training small LMs has often relied on imitation learning to replicate the output of more capable models. We contend that excessive emphasis on imitation may restrict the potential of smaller models. We seek to teach small LMs to employ different solution strategies for different tasks, potentially different from the one used by the larger model. For example, while larger models might provide a direct answer to a complex task, smaller models may not have the same capacity. In Orca 2, we teach the model various reasoning techniques (step-by-step, recall then generate, recall-reason-generate, direct answer, etc.). More crucially, we aim to help the model learn to determine the most effective solution strategy for each task. We evaluate Orca 2 using a comprehensive set of 15 diverse benchmarks (corresponding to approximately 100 tasks and over 36,000 unique prompts). Orca 2 significantly surpasses models of similar size and attains performance levels similar or better to those of models 5-10x larger, as assessed on complex tasks that test advanced reasoning abilities in zero-shot settings. make Orca 2 weights publicly available at aka.ms/orca-lm to support research on the development, evaluation, and alignment of smaller LMs
Overview of the TREC 2023 Product Product Search Track
Nov 15, 2023This is the first year of the TREC Product search track. The focus this year was the creation of a reusable collection and evaluation of the impact of the use of metadata and multi-modal data on retrieval accuracy. This year we leverage the new product search corpus, which includes contextual metadata. Our analysis shows that in the product search domain, traditional retrieval systems are highly effective and commonly outperform general-purpose pretrained embedding models. Our analysis also evaluates the impact of using simplified and metadata-enhanced collections, finding no clear trend in the impact of the expanded collection. We also see some surprising outcomes; despite their widespread adoption and competitive performance on other tasks, we find single-stage dense retrieval runs can commonly be noncompetitive or generate low-quality results both in the zero-shot and fine-tuned domain.
Nugget 2D: Dynamic Contextual Compression for Scaling Decoder-only Language Models
Oct 03, 2023Standard Transformer-based language models (LMs) scale poorly to long contexts. We propose a solution based on dynamic contextual compression, which extends the Nugget approach of Qin & Van Durme (2023) from BERT-like frameworks to decoder-only LMs. Our method models history as compressed "nuggets" which are trained to allow for reconstruction, and it can be initialized with off-the-shelf models such as LLaMA. We demonstrate through experiments in language modeling, question answering, and summarization that Nugget2D retains capabilities in these tasks, while drastically reducing the overhead during decoding in terms of time and space. For example, in the experiments of autoencoding, Nugget2D can shrink context at a 20x compression ratio with a BLEU score of 98% for reconstruction, achieving nearly lossless encoding.
Contrastive Post-training Large Language Models on Data Curriculum
Oct 03, 2023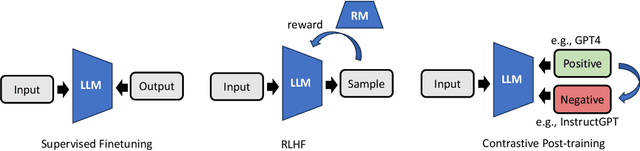


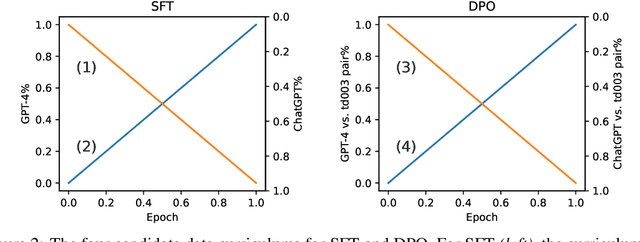
Alignment serves as an important step to steer large language models (LLMs) towards human preferences. In this paper, we explore contrastive post-training techniques for alignment by automatically constructing preference pairs from multiple models of varying strengths (e.g., InstructGPT, ChatGPT and GPT-4). We carefully compare the contrastive techniques of SLiC and DPO to SFT baselines and find that DPO provides a step-function improvement even after continueing SFT saturates. We also explore a data curriculum learning scheme for contrastive post-training, which starts by learning from "easier" pairs and transitioning to "harder" ones, which further improves alignment. Finally, we scale up our experiments to train with more data and larger models like Orca. Remarkably, contrastive post-training further improves the performance of Orca, already a state-of-the-art instruction learning model tuned with GPT-4 outputs, to exceed that of ChatGPT.
Zero-shot Clarifying Question Generation for Conversational Search
Feb 10, 2023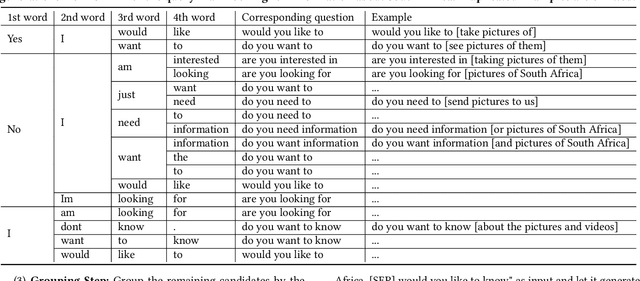
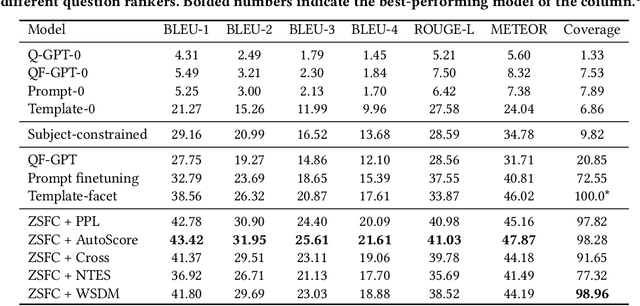
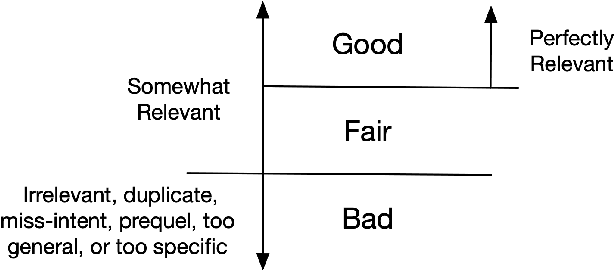
A long-standing challenge for search and conversational assistants is query intention detection in ambiguous queries. Asking clarifying questions in conversational search has been widely studied and considered an effective solution to resolve query ambiguity. Existing work have explored various approaches for clarifying question ranking and generation. However, due to the lack of real conversational search data, they have to use artificial datasets for training, which limits their generalizability to real-world search scenarios. As a result, the industry has shown reluctance to implement them in reality, further suspending the availability of real conversational search interaction data. The above dilemma can be formulated as a cold start problem of clarifying question generation and conversational search in general. Furthermore, even if we do have large-scale conversational logs, it is not realistic to gather training data that can comprehensively cover all possible queries and topics in open-domain search scenarios. The risk of fitting bias when training a clarifying question retrieval/generation model on incomprehensive dataset is thus another important challenge. In this work, we innovatively explore generating clarifying questions in a zero-shot setting to overcome the cold start problem and we propose a constrained clarifying question generation system which uses both question templates and query facets to guide the effective and precise question generation. The experiment results show that our method outperforms existing state-of-the-art zero-shot baselines by a large margin. Human annotations to our model outputs also indicate our method generates 25.2\% more natural questions, 18.1\% more useful questions, 6.1\% less unnatural and 4\% less useless questions.