 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQiang Fu
Reaching Consensus in Cooperative Multi-Agent Reinforcement Learning with Goal Imagination
Mar 05, 2024
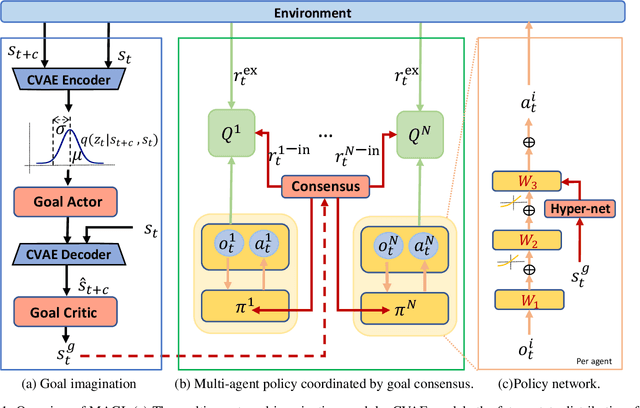
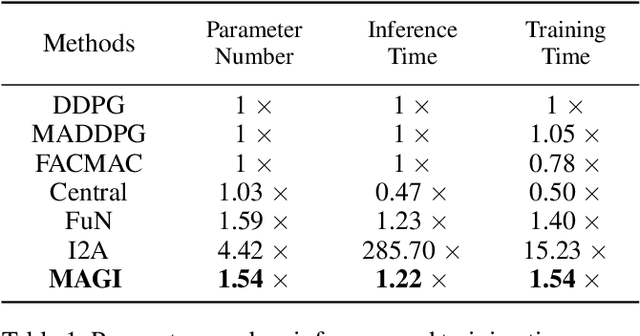
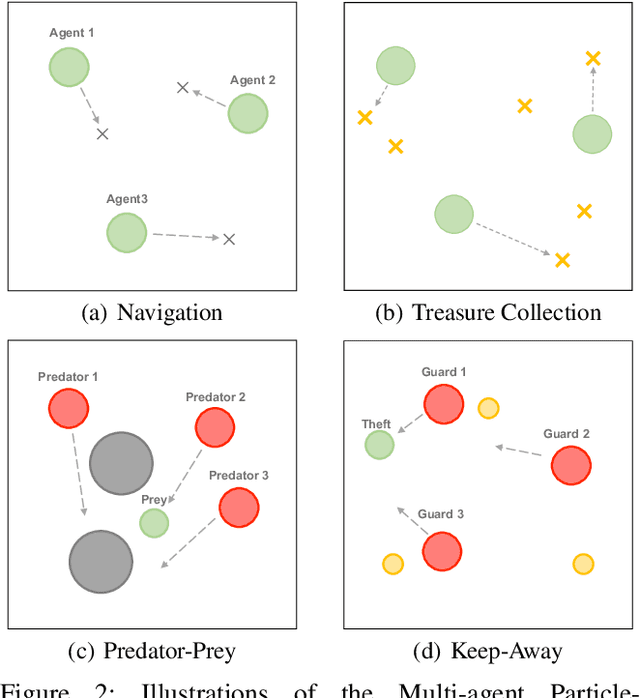

Reaching consensus is key to multi-agent coordination. To accomplish a cooperative task, agents need to coherently select optimal joint actions to maximize the team reward. However, current cooperative multi-agent reinforcement learning (MARL) methods usually do not explicitly take consensus into consideration, which may cause miscoordination problem. In this paper, we propose a model-based consensus mechanism to explicitly coordinate multiple agents. The proposed Multi-agent Goal Imagination (MAGI) framework guides agents to reach consensus with an Imagined common goal. The common goal is an achievable state with high value, which is obtained by sampling from the distribution of future states. We directly model this distribution with a self-supervised generative model, thus alleviating the "curse of dimensinality" problem induced by multi-agent multi-step policy rollout commonly used in model-based methods. We show that such efficient consensus mechanism can guide all agents cooperatively reaching valuable future states. Results on Multi-agent Particle-Environments and Google Research Football environment demonstrate the superiority of MAGI in both sample efficiency and performance.
Robust Wake Word Spotting With Frame-Level Cross-Modal Attention Based Audio-Visual Conformer
Mar 04, 2024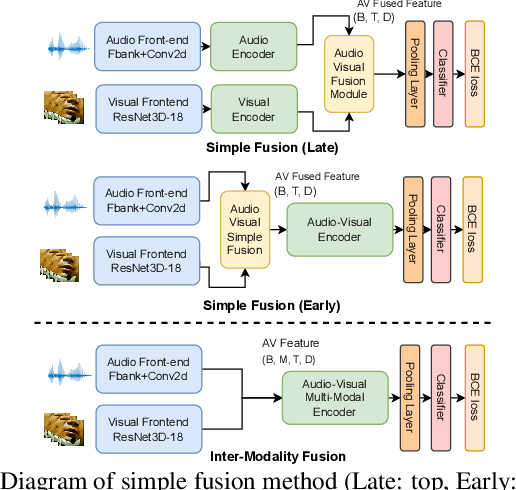
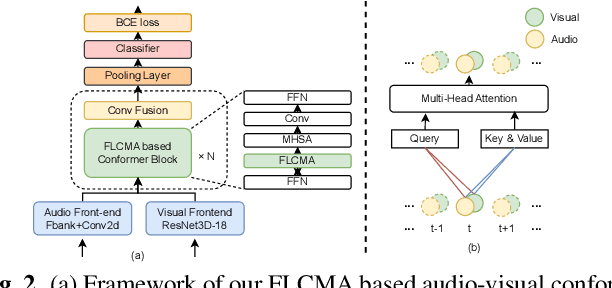
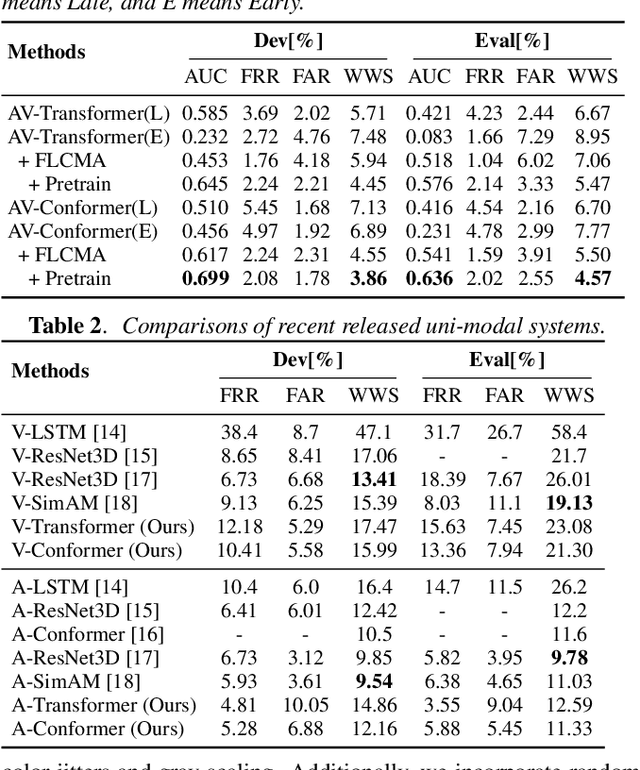
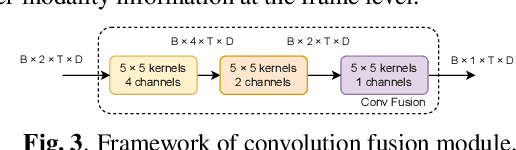
In recent years, neural network-based Wake Word Spotting achieves good performance on clean audio samples but struggles in noisy environments. Audio-Visual Wake Word Spotting (AVWWS) receives lots of attention because visual lip movement information is not affected by complex acoustic scenes. Previous works usually use simple addition or concatenation for multi-modal fusion. The inter-modal correlation remains relatively under-explored. In this paper, we propose a novel module called Frame-Level Cross-Modal Attention (FLCMA) to improve the performance of AVWWS systems. This module can help model multi-modal information at the frame-level through synchronous lip movements and speech signals. We train the end-to-end FLCMA based Audio-Visual Conformer and further improve the performance by fine-tuning pre-trained uni-modal models for the AVWWS task. The proposed system achieves a new state-of-the-art result (4.57% WWS score) on the far-field MISP dataset.
Guiding Large Language Models with Divide-and-Conquer Program for Discerning Problem Solving
Feb 08, 2024Foundation models, such as Large language Models (LLMs), have attracted significant amount of interest due to their large number of applications. Existing works show that appropriate prompt design, such as Chain-of-Thoughts, can unlock LLM's powerful capacity in diverse areas. However, when handling tasks involving repetitive sub-tasks and/or deceptive contents, such as arithmetic calculation and article-level fake news detection, existing prompting strategies either suffers from insufficient expressive power or intermediate errors triggered by hallucination. To make LLM more discerning to such intermediate errors, we propose to guide LLM with a Divide-and-Conquer program that simultaneously ensures superior expressive power and disentangles task decomposition, sub-task resolution, and resolution assembly process. Theoretic analysis reveals that our strategy can guide LLM to extend the expressive power of fixed-depth Transformer. Experiments indicate that our proposed method can achieve better performance than typical prompting strategies in tasks bothered by intermediate errors and deceptive contents, such as large integer multiplication, hallucination detection and misinformation detection.
Enhance Reasoning for Large Language Models in the Game Werewolf
Feb 04, 2024This paper presents an innovative framework that integrates Large Language Models (LLMs) with an external Thinker module to enhance the reasoning capabilities of LLM-based agents. Unlike augmenting LLMs with prompt engineering, Thinker directly harnesses knowledge from databases and employs various optimization techniques. The framework forms a reasoning hierarchy where LLMs handle intuitive System-1 tasks such as natural language processing, while the Thinker focuses on cognitive System-2 tasks that require complex logical analysis and domain-specific knowledge. Our framework is presented using a 9-player Werewolf game that demands dual-system reasoning. We introduce a communication protocol between LLMs and the Thinker, and train the Thinker using data from 18800 human sessions and reinforcement learning. Experiments demonstrate the framework's effectiveness in deductive reasoning, speech generation, and online game evaluation. Additionally, we fine-tune a 6B LLM to surpass GPT4 when integrated with the Thinker. This paper also contributes the largest dataset for social deduction games to date.
Affordable Generative Agents
Feb 03, 2024The emergence of large language models (LLMs) has significantly advanced the simulation of believable interactive agents. However, the substantial cost on maintaining the prolonged agent interactions poses challenge over the deployment of believable LLM-based agents. Therefore, in this paper, we develop Affordable Generative Agents (AGA), a framework for enabling the generation of believable and low-cost interactions on both agent-environment and inter-agents levels. Specifically, for agent-environment interactions, we substitute repetitive LLM inferences with learned policies; while for inter-agent interactions, we model the social relationships between agents and compress auxiliary dialogue information. Extensive experiments on multiple environments show the effectiveness and efficiency of our proposed framework. Also, we delve into the mechanisms of emergent believable behaviors lying in LLM agents, demonstrating that agents can only generate finite behaviors in fixed environments, based upon which, we understand ways to facilitate emergent interaction behaviors. Our code is publicly available at: \url{https://github.com/AffordableGenerativeAgents/Affordable-Generative-Agents}.
More Agents Is All You Need
Feb 03, 2024We find that, simply via a sampling-and-voting method, the performance of large language models (LLMs) scales with the number of agents instantiated. Also, this method is orthogonal to existing complicated methods to further enhance LLMs, while the degree of enhancement is correlated to the task difficulty. We conduct comprehensive experiments on a wide range of LLM benchmarks to verify the presence of our finding, and to study the properties that can facilitate its occurrence. Our code is publicly available at: \url{https://anonymous.4open.science/r/more_agent_is_all_you_need}.
Enhancing Human Experience in Human-Agent Collaboration: A Human-Centered Modeling Approach Based on Positive Human Gain
Jan 28, 2024Existing game AI research mainly focuses on enhancing agents' abilities to win games, but this does not inherently make humans have a better experience when collaborating with these agents. For example, agents may dominate the collaboration and exhibit unintended or detrimental behaviors, leading to poor experiences for their human partners. In other words, most game AI agents are modeled in a "self-centered" manner. In this paper, we propose a "human-centered" modeling scheme for collaborative agents that aims to enhance the experience of humans. Specifically, we model the experience of humans as the goals they expect to achieve during the task. We expect that agents should learn to enhance the extent to which humans achieve these goals while maintaining agents' original abilities (e.g., winning games). To achieve this, we propose the Reinforcement Learning from Human Gain (RLHG) approach. The RLHG approach introduces a "baseline", which corresponds to the extent to which humans primitively achieve their goals, and encourages agents to learn behaviors that can effectively enhance humans in achieving their goals better. We evaluate the RLHG agent in the popular Multi-player Online Battle Arena (MOBA) game, Honor of Kings, by conducting real-world human-agent tests. Both objective performance and subjective preference results show that the RLHG agent provides participants better gaming experience.
TAROT: A Hierarchical Framework with Multitask Co-Pretraining on Semi-Structured Data towards Effective Person-Job Fit
Jan 17, 2024Person-job fit is an essential part of online recruitment platforms in serving various downstream applications like Job Search and Candidate Recommendation. Recently, pretrained large language models have further enhanced the effectiveness by leveraging richer textual information in user profiles and job descriptions apart from user behavior features and job metadata. However, the general domain-oriented design struggles to capture the unique structural information within user profiles and job descriptions, leading to a loss of latent semantic correlations. We propose TAROT, a hierarchical multitask co-pretraining framework, to better utilize structural and semantic information for informative text embeddings. TAROT targets semi-structured text in profiles and jobs, and it is co-pretained with multi-grained pretraining tasks to constrain the acquired semantic information at each level. Experiments on a real-world LinkedIn dataset show significant performance improvements, proving its effectiveness in person-job fit tasks.
Mean-field underdamped Langevin dynamics and its spacetime discretization
Jan 17, 2024We propose a new method called the N-particle underdamped Langevin algorithm for optimizing a special class of non-linear functionals defined over the space of probability measures. Examples of problems with this formulation include training mean-field neural networks, maximum mean discrepancy minimization and kernel Stein discrepancy minimization. Our algorithm is based on a novel spacetime discretization of the mean-field underdamped Langevin dynamics, for which we provide a new, fast mixing guarantee. In addition, we demonstrate that our algorithm converges globally in total variation distance, bridging the theoretical gap between the dynamics and its practical implementation.