 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeixuan Wang
Enhancing Human Experience in Human-Agent Collaboration: A Human-Centered Modeling Approach Based on Positive Human Gain
Jan 28, 2024
Existing game AI research mainly focuses on enhancing agents' abilities to win games, but this does not inherently make humans have a better experience when collaborating with these agents. For example, agents may dominate the collaboration and exhibit unintended or detrimental behaviors, leading to poor experiences for their human partners. In other words, most game AI agents are modeled in a "self-centered" manner. In this paper, we propose a "human-centered" modeling scheme for collaborative agents that aims to enhance the experience of humans. Specifically, we model the experience of humans as the goals they expect to achieve during the task. We expect that agents should learn to enhance the extent to which humans achieve these goals while maintaining agents' original abilities (e.g., winning games). To achieve this, we propose the Reinforcement Learning from Human Gain (RLHG) approach. The RLHG approach introduces a "baseline", which corresponds to the extent to which humans primitively achieve their goals, and encourages agents to learn behaviors that can effectively enhance humans in achieving their goals better. We evaluate the RLHG agent in the popular Multi-player Online Battle Arena (MOBA) game, Honor of Kings, by conducting real-world human-agent tests. Both objective performance and subjective preference results show that the RLHG agent provides participants better gaming experience.
Retrieval-augmented Multilingual Knowledge Editing
Dec 20, 2023Knowledge represented in Large Language Models (LLMs) is quite often incorrect and can also become obsolete over time. Updating knowledge via fine-tuning is computationally resource-hungry and not reliable, and so knowledge editing (KE) has developed as an effective and economical alternative to inject new knowledge or to fix factual errors in LLMs. Although there has been considerable interest in this area, current KE research exclusively focuses on the monolingual setting, typically in English. However, what happens if the new knowledge is supplied in one language, but we would like to query the LLM in a different language? To address the problem of multilingual knowledge editing, we propose Retrieval-augmented Multilingual Knowledge Editor (ReMaKE) to update new knowledge in LLMs. ReMaKE can perform model-agnostic knowledge editing in multilingual settings. ReMaKE concatenates the new knowledge retrieved from a multilingual knowledge base with prompts. Our experimental results show that ReMaKE outperforms baseline knowledge editing methods by a significant margin and is the first KE method to work in a multilingual setting. We provide our multilingual knowledge editing dataset (MzsRE) in 12 languages, which along with code, and additional project information is available at https://github.com/Vicky-Wil/ReMaKE.
Assessing the Reliability of Large Language Model Knowledge
Oct 15, 2023Large language models (LLMs) have been treated as knowledge bases due to their strong performance in knowledge probing tasks. LLMs are typically evaluated using accuracy, yet this metric does not capture the vulnerability of LLMs to hallucination-inducing factors like prompt and context variability. How do we evaluate the capabilities of LLMs to consistently produce factually correct answers? In this paper, we propose MOdel kNowledge relIabiliTy scORe (MONITOR), a novel metric designed to directly measure LLMs' factual reliability. MONITOR computes the distance between the probability distributions of a valid output and its counterparts produced by the same LLM probing the same fact using different styles of prompts and contexts.Experiments on a comprehensive range of 12 LLMs demonstrate the effectiveness of MONITOR in evaluating the factual reliability of LLMs while maintaining a low computational overhead. In addition, we release the FKTC (Factual Knowledge Test Corpus) test set, containing 210,158 prompts in total to foster research along this line (https://github.com/Vicky-Wil/MONITOR).
Hermes: Unlocking Security Analysis of Cellular Network Protocols by Synthesizing Finite State Machines from Natural Language Specifications
Oct 11, 2023



In this paper, we present Hermes, an end-to-end framework to automatically generate formal representations from natural language cellular specifications. We first develop a neural constituency parser, NEUTREX, to process transition-relevant texts and extract transition components (i.e., states, conditions, and actions). We also design a domain-specific language to translate these transition components to logical formulas by leveraging dependency parse trees. Finally, we compile these logical formulas to generate transitions and create the formal model as finite state machines. To demonstrate the effectiveness of Hermes, we evaluate it on 4G NAS, 5G NAS, and 5G RRC specifications and obtain an overall accuracy of 81-87%, which is a substantial improvement over the state-of-the-art. Our security analysis of the extracted models uncovers 3 new vulnerabilities and identifies 19 previous attacks in 4G and 5G specifications, and 7 deviations in commercial 4G basebands.
Evaluating the Efficacy of Length-Controllable Machine Translation
May 03, 2023
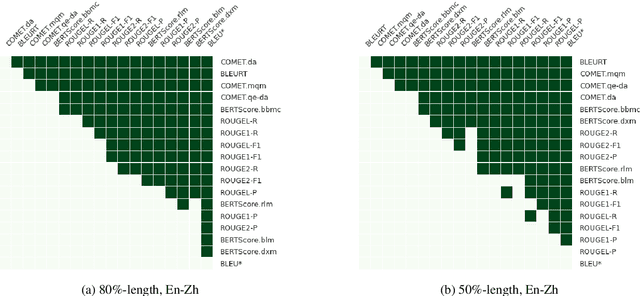
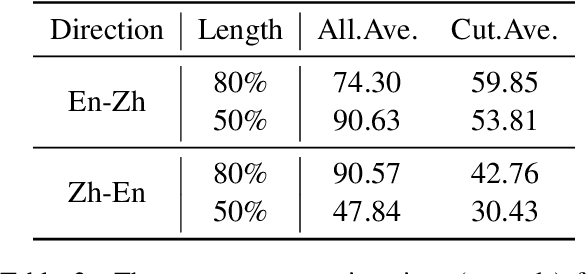
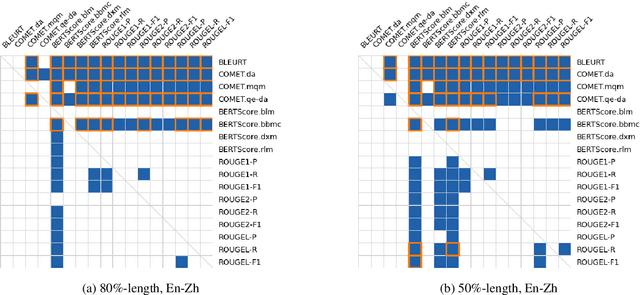
Length-controllable machine translation is a type of constrained translation. It aims to contain the original meaning as much as possible while controlling the length of the translation. We can use automatic summarization or machine translation evaluation metrics for length-controllable machine translation, but this is not necessarily suitable and accurate. This work is the first attempt to evaluate the automatic metrics for length-controllable machine translation tasks systematically. We conduct a rigorous human evaluation on two translation directions and evaluate 18 summarization or translation evaluation metrics. We find that BLEURT and COMET have the highest correlation with human evaluation and are most suitable as evaluation metrics for length-controllable machine translation.
Towards Effective and Interpretable Human-Agent Collaboration in MOBA Games: A Communication Perspective
Apr 23, 2023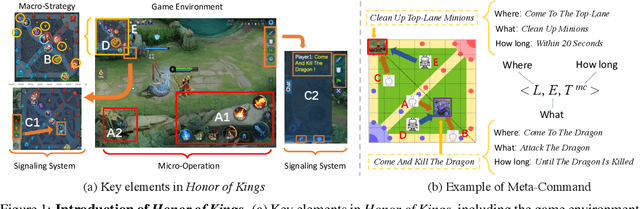

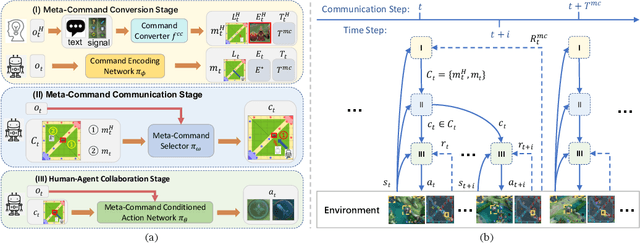
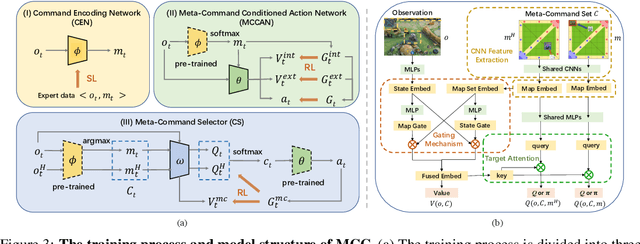
MOBA games, e.g., Dota2 and Honor of Kings, have been actively used as the testbed for the recent AI research on games, and various AI systems have been developed at the human level so far. However, these AI systems mainly focus on how to compete with humans, less on exploring how to collaborate with humans. To this end, this paper makes the first attempt to investigate human-agent collaboration in MOBA games. In this paper, we propose to enable humans and agents to collaborate through explicit communication by designing an efficient and interpretable Meta-Command Communication-based framework, dubbed MCC, for accomplishing effective human-agent collaboration in MOBA games. The MCC framework consists of two pivotal modules: 1) an interpretable communication protocol, i.e., the Meta-Command, to bridge the communication gap between humans and agents; 2) a meta-command value estimator, i.e., the Meta-Command Selector, to select a valuable meta-command for each agent to achieve effective human-agent collaboration. Experimental results in Honor of Kings demonstrate that MCC agents can collaborate reasonably well with human teammates and even generalize to collaborate with different levels and numbers of human teammates. Videos are available at https://sites.google.com/view/mcc-demo.
Learning Homographic Disambiguation Representation for Neural Machine Translation
Apr 13, 2023



Homographs, words with the same spelling but different meanings, remain challenging in Neural Machine Translation (NMT). While recent works leverage various word embedding approaches to differentiate word sense in NMT, they do not focus on the pivotal components in resolving ambiguities of homographs in NMT: the hidden states of an encoder. In this paper, we propose a novel approach to tackle homographic issues of NMT in the latent space. We first train an encoder (aka "HDR-encoder") to learn universal sentence representations in a natural language inference (NLI) task. We further fine-tune the encoder using homograph-based synset sentences from WordNet, enabling it to learn word-level homographic disambiguation representations (HDR). The pre-trained HDR-encoder is subsequently integrated with a transformer-based NMT in various schemes to improve translation accuracy. Experiments on four translation directions demonstrate the effectiveness of the proposed method in enhancing the performance of NMT systems in the BLEU scores (up to +2.3 compared to a solid baseline). The effects can be verified by other metrics (F1, precision, and recall) of translation accuracy in an additional disambiguation task. Visualization methods like heatmaps, T-SNE and translation examples are also utilized to demonstrate the effects of the proposed method.
Positively transitioned sentiment dialogue corpus for developing emotion-affective open-domain chatbots
Aug 10, 2022



In this paper, we describe a data enhancement method for developing Emily, an emotion-affective open-domain chatbot. The proposed method is based on explicitly modeling positively transitioned (PT) sentiment data from multi-turn dialogues. We construct a dialogue corpus with PT sentiment data and will release it for public use. By fine-tuning a pretrained dialogue model using the produced PT-enhanced dialogues, we are able to develop an emotion-affective open-domain chatbot exhibiting close-to-human performance in various emotion-affective metrics. We evaluate Emily against a few state-of-the-art (SOTA) open-domain chatbots and show the effectiveness of the proposed approach. The corpus is made publicly available.
Learning Diverse Policies in MOBA Games via Macro-Goals
Oct 27, 2021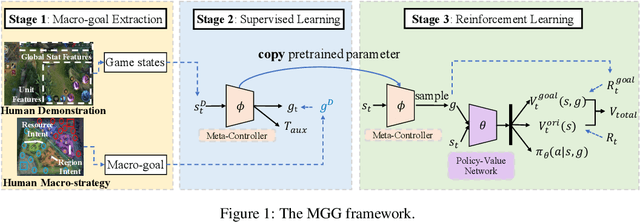
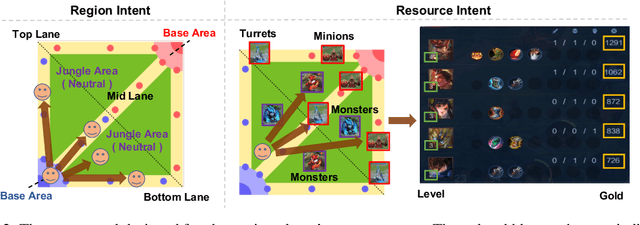
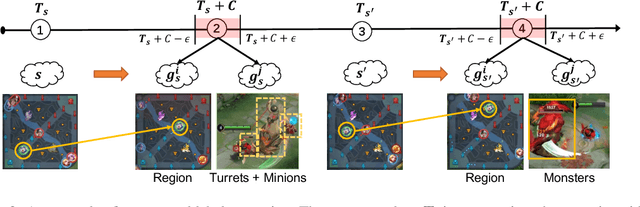
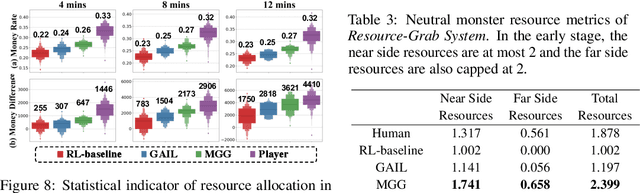
Recently, many researchers have made successful progress in building the AI systems for MOBA-game-playing with deep reinforcement learning, such as on Dota 2 and Honor of Kings. Even though these AI systems have achieved or even exceeded human-level performance, they still suffer from the lack of policy diversity. In this paper, we propose a novel Macro-Goals Guided framework, called MGG, to learn diverse policies in MOBA games. MGG abstracts strategies as macro-goals from human demonstrations and trains a Meta-Controller to predict these macro-goals. To enhance policy diversity, MGG samples macro-goals from the Meta-Controller prediction and guides the training process towards these goals. Experimental results on the typical MOBA game Honor of Kings demonstrate that MGG can execute diverse policies in different matches and lineups, and also outperform the state-of-the-art methods over 102 heroes.
Emily: Developing An Emotion-affective Open-Domain Chatbot with Knowledge Graph-based Persona
Sep 18, 2021



In this paper, we describe approaches for developing Emily, an emotion-affective open-domain chatbot. Emily can perceive a user's negative emotion state and offer supports by positively converting the user's emotion states. This is done by finetuning a pretrained dialogue model upon data capturing dialogue contexts and desirable emotion states transition across turns. Emily can differentiate a general open-domain dialogue utterance with questions relating to personal information. By leveraging a question-answering approach based on knowledge graphs to handle personal information, Emily maintains personality consistency. We evaluate Emily against a few state-of-the-art open-domain chatbots and show the effects of the proposed approaches in emotion affecting and addressing personality inconsistency.