 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaoran Wang
MIMIR: A Streamlined Platform for Personalized Agent Tuning in Domain Expertise
Apr 03, 2024
Recently, large language models (LLMs) have evolved into interactive agents, proficient in planning, tool use, and task execution across a wide variety of tasks. However, without specific agent tuning, open-source models like LLaMA currently struggle to match the efficiency of GPT- 4, particularly given the scarcity of agent-tuning datasets for fine-tuning. In response, we introduce \textsc{Mimir}: a streamlined platform offering a customizable pipeline that enables users to leverage both private knowledge and publicly available, legally compliant datasets at scale for \textbf{personalized agent tuning}. Additionally, \textsc{Mimir} supports the generation of general instruction-tuning datasets from the same input. This dual capability ensures that language agents developed through the platform possess both specific agent abilities and general competencies. \textsc{Mimir} integrates these features into a cohesive end-to-end platform, facilitating everything from the uploading of personalized files to one-click agent fine-tuning.
SGD: Street View Synthesis with Gaussian Splatting and Diffusion Prior
Mar 29, 2024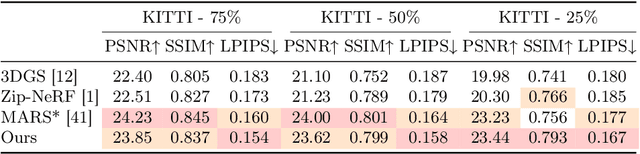

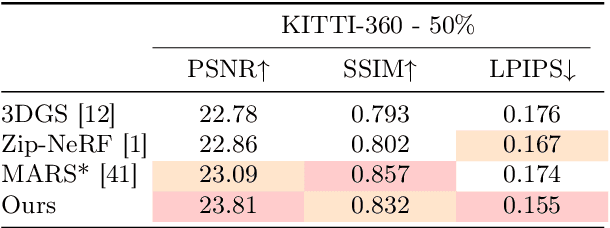
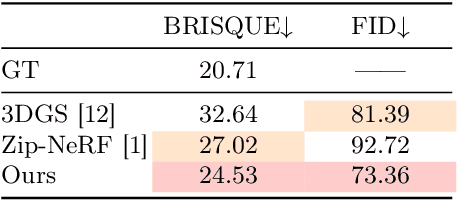
Novel View Synthesis (NVS) for street scenes play a critical role in the autonomous driving simulation. The current mainstream technique to achieve it is neural rendering, such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS). Although thrilling progress has been made, when handling street scenes, current methods struggle to maintain rendering quality at the viewpoint that deviates significantly from the training viewpoints. This issue stems from the sparse training views captured by a fixed camera on a moving vehicle. To tackle this problem, we propose a novel approach that enhances the capacity of 3DGS by leveraging prior from a Diffusion Model along with complementary multi-modal data. Specifically, we first fine-tune a Diffusion Model by adding images from adjacent frames as condition, meanwhile exploiting depth data from LiDAR point clouds to supply additional spatial information. Then we apply the Diffusion Model to regularize the 3DGS at unseen views during training. Experimental results validate the effectiveness of our method compared with current state-of-the-art models, and demonstrate its advance in rendering images from broader views.
CACA Agent: Capability Collaboration based AI Agent
Mar 22, 2024As AI Agents based on Large Language Models (LLMs) have shown potential in practical applications across various fields, how to quickly deploy an AI agent and how to conveniently expand the application scenario of AI agents has become a challenge. Previous studies mainly focused on implementing all the reasoning capabilities of AI agents within a single LLM, which often makes the model more complex and also reduces the extensibility of AI agent functionality. In this paper, we propose CACA Agent (Capability Collaboration based AI Agent), using an open architecture inspired by service computing. CACA Agent integrates a set of collaborative capabilities to implement AI Agents, not only reducing the dependence on a single LLM, but also enhancing the extensibility of both the planning abilities and the tools available to AI agents. Utilizing the proposed system, we present a demo to illustrate the operation and the application scenario extension of CACA Agent.
Safeguarding Medical Image Segmentation Datasets against Unauthorized Training via Contour- and Texture-Aware Perturbations
Mar 21, 2024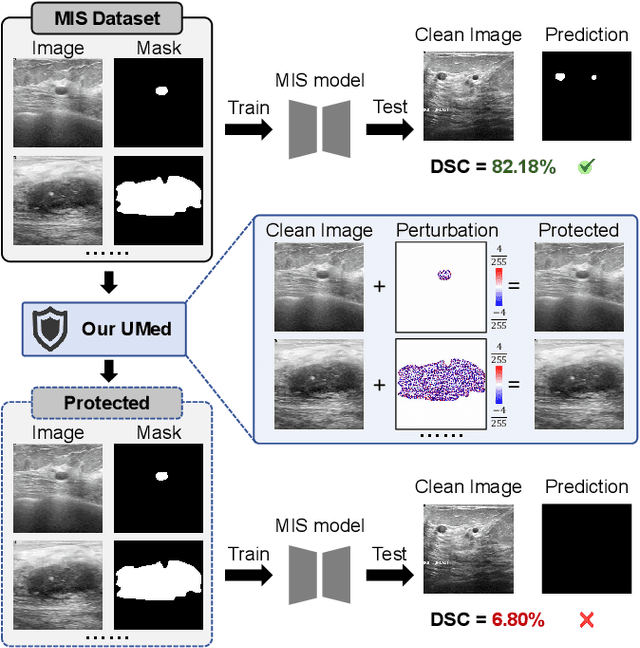
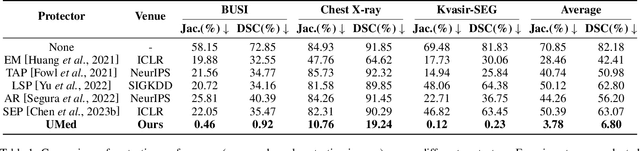
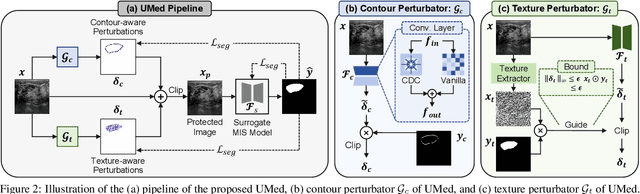
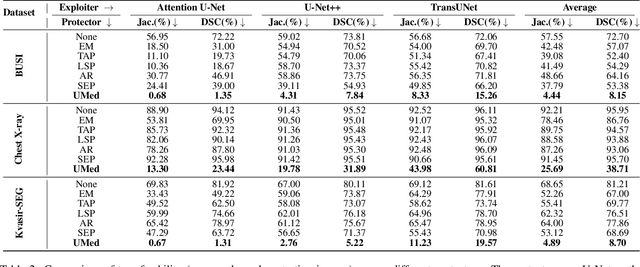
The widespread availability of publicly accessible medical images has significantly propelled advancements in various research and clinical fields. Nonetheless, concerns regarding unauthorized training of AI systems for commercial purposes and the duties of patient privacy protection have led numerous institutions to hesitate to share their images. This is particularly true for medical image segmentation (MIS) datasets, where the processes of collection and fine-grained annotation are time-intensive and laborious. Recently, Unlearnable Examples (UEs) methods have shown the potential to protect images by adding invisible shortcuts. These shortcuts can prevent unauthorized deep neural networks from generalizing. However, existing UEs are designed for natural image classification and fail to protect MIS datasets imperceptibly as their protective perturbations are less learnable than important prior knowledge in MIS, e.g., contour and texture features. To this end, we propose an Unlearnable Medical image generation method, termed UMed. UMed integrates the prior knowledge of MIS by injecting contour- and texture-aware perturbations to protect images. Given that our target is to only poison features critical to MIS, UMed requires only minimal perturbations within the ROI and its contour to achieve greater imperceptibility (average PSNR is 50.03) and protective performance (clean average DSC degrades from 82.18% to 6.80%).
A$^{3}$lign-DFER: Pioneering Comprehensive Dynamic Affective Alignment for Dynamic Facial Expression Recognition with CLIP
Mar 07, 2024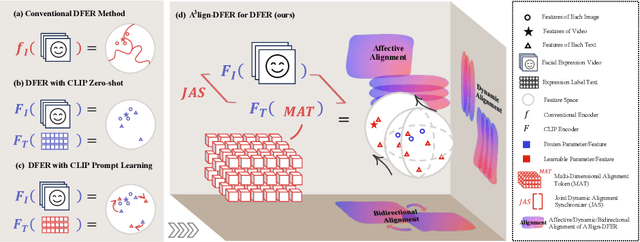
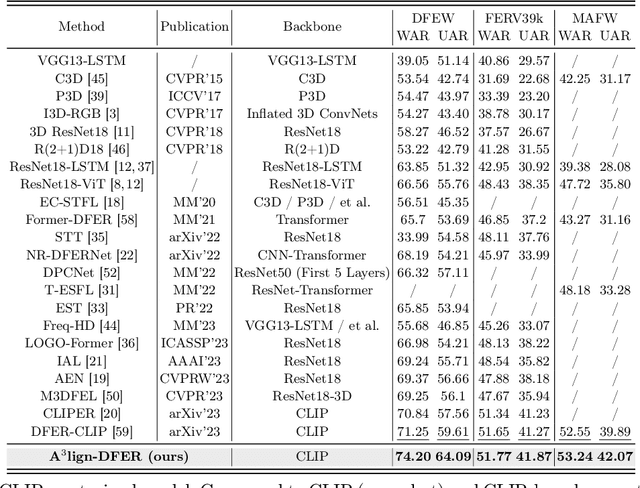
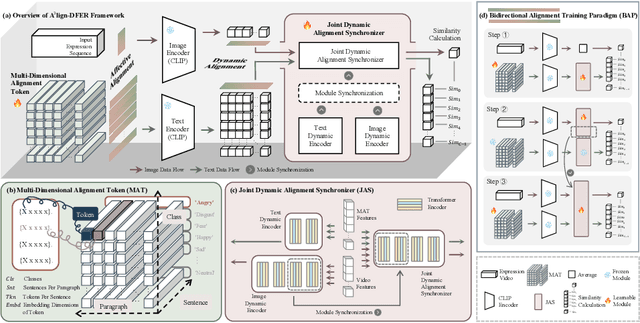
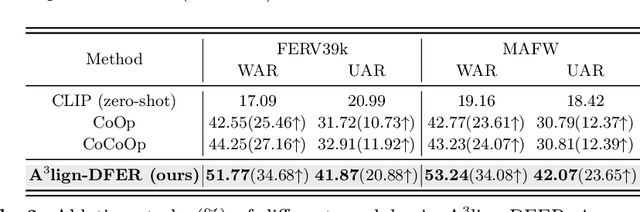
The performance of CLIP in dynamic facial expression recognition (DFER) task doesn't yield exceptional results as observed in other CLIP-based classification tasks. While CLIP's primary objective is to achieve alignment between images and text in the feature space, DFER poses challenges due to the abstract nature of text and the dynamic nature of video, making label representation limited and perfect alignment difficult. To address this issue, we have designed A$^{3}$lign-DFER, which introduces a new DFER labeling paradigm to comprehensively achieve alignment, thus enhancing CLIP's suitability for the DFER task. Specifically, our A$^{3}$lign-DFER method is designed with multiple modules that work together to obtain the most suitable expanded-dimensional embeddings for classification and to achieve alignment in three key aspects: affective, dynamic, and bidirectional. We replace the input label text with a learnable Multi-Dimensional Alignment Token (MAT), enabling alignment of text to facial expression video samples in both affective and dynamic dimensions. After CLIP feature extraction, we introduce the Joint Dynamic Alignment Synchronizer (JAS), further facilitating synchronization and alignment in the temporal dimension. Additionally, we implement a Bidirectional Alignment Training Paradigm (BAP) to ensure gradual and steady training of parameters for both modalities. Our insightful and concise A$^{3}$lign-DFER method achieves state-of-the-art results on multiple DFER datasets, including DFEW, FERV39k, and MAFW. Extensive ablation experiments and visualization studies demonstrate the effectiveness of A$^{3}$lign-DFER. The code will be available in the future.
Neural Field Classifiers via Target Encoding and Classification Loss
Mar 02, 2024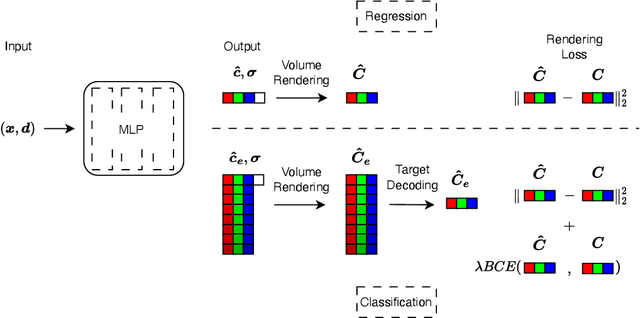
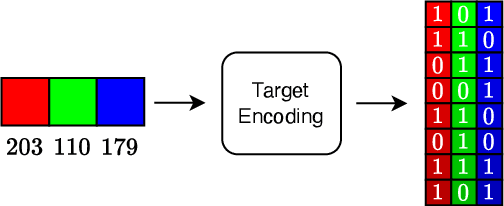

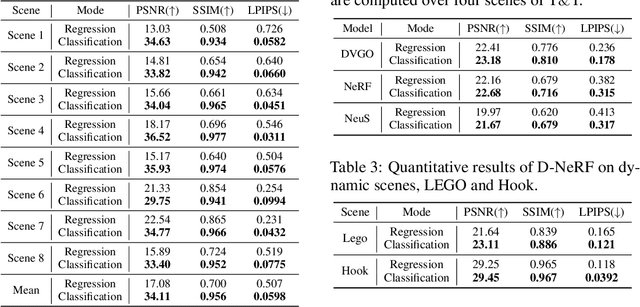
Neural field methods have seen great progress in various long-standing tasks in computer vision and computer graphics, including novel view synthesis and geometry reconstruction. As existing neural field methods try to predict some coordinate-based continuous target values, such as RGB for Neural Radiance Field (NeRF), all of these methods are regression models and are optimized by some regression loss. However, are regression models really better than classification models for neural field methods? In this work, we try to visit this very fundamental but overlooked question for neural fields from a machine learning perspective. We successfully propose a novel Neural Field Classifier (NFC) framework which formulates existing neural field methods as classification tasks rather than regression tasks. The proposed NFC can easily transform arbitrary Neural Field Regressor (NFR) into its classification variant via employing a novel Target Encoding module and optimizing a classification loss. By encoding a continuous regression target into a high-dimensional discrete encoding, we naturally formulate a multi-label classification task. Extensive experiments demonstrate the impressive effectiveness of NFC at the nearly free extra computational costs. Moreover, NFC also shows robustness to sparse inputs, corrupted images, and dynamic scenes.
TrustLLM: Trustworthiness in Large Language Models
Jan 25, 2024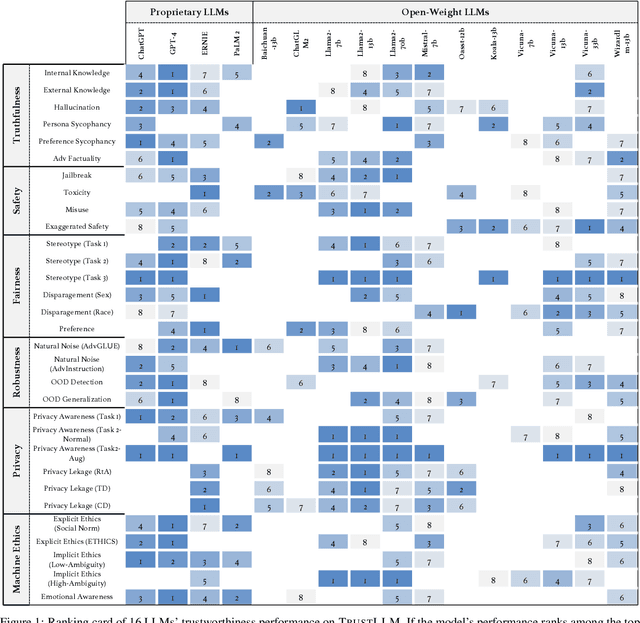


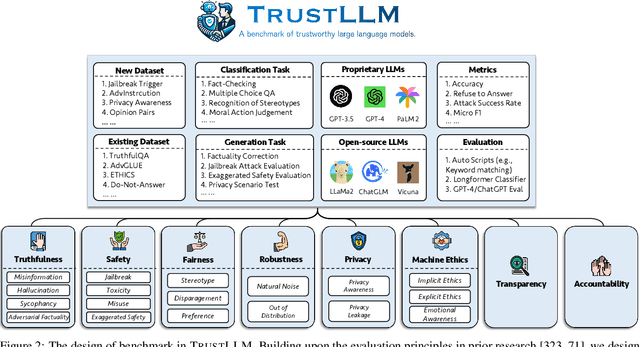
Large language models (LLMs), exemplified by ChatGPT, have gained considerable attention for their excellent natural language processing capabilities. Nonetheless, these LLMs present many challenges, particularly in the realm of trustworthiness. Therefore, ensuring the trustworthiness of LLMs emerges as an important topic. This paper introduces TrustLLM, a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. Our findings firstly show that in general trustworthiness and utility (i.e., functional effectiveness) are positively related. Secondly, our observations reveal that proprietary LLMs generally outperform most open-source counterparts in terms of trustworthiness, raising concerns about the potential risks of widely accessible open-source LLMs. However, a few open-source LLMs come very close to proprietary ones. Thirdly, it is important to note that some LLMs may be overly calibrated towards exhibiting trustworthiness, to the extent that they compromise their utility by mistakenly treating benign prompts as harmful and consequently not responding. Finally, we emphasize the importance of ensuring transparency not only in the models themselves but also in the technologies that underpin trustworthiness. Knowing the specific trustworthy technologies that have been employed is crucial for analyzing their effectiveness.
HiCAST: Highly Customized Arbitrary Style Transfer with Adapter Enhanced Diffusion Models
Jan 11, 2024The goal of Arbitrary Style Transfer (AST) is injecting the artistic features of a style reference into a given image/video. Existing methods usually focus on pursuing the balance between style and content, whereas ignoring the significant demand for flexible and customized stylization results and thereby limiting their practical application. To address this critical issue, a novel AST approach namely HiCAST is proposed, which is capable of explicitly customizing the stylization results according to various source of semantic clues. In the specific, our model is constructed based on Latent Diffusion Model (LDM) and elaborately designed to absorb content and style instance as conditions of LDM. It is characterized by introducing of \textit{Style Adapter}, which allows user to flexibly manipulate the output results by aligning multi-level style information and intrinsic knowledge in LDM. Lastly, we further extend our model to perform video AST. A novel learning objective is leveraged for video diffusion model training, which significantly improve cross-frame temporal consistency in the premise of maintaining stylization strength. Qualitative and quantitative comparisons as well as comprehensive user studies demonstrate that our HiCAST outperforms the existing SoTA methods in generating visually plausible stylization results.
Parallel Ranking of Ads and Creatives in Real-Time Advertising Systems
Dec 20, 2023"Creativity is the heart and soul of advertising services". Effective creatives can create a win-win scenario: advertisers can reach target users and achieve marketing objectives more effectively, users can more quickly find products of interest, and platforms can generate more advertising revenue. With the advent of AI-Generated Content, advertisers now can produce vast amounts of creative content at a minimal cost. The current challenge lies in how advertising systems can select the most pertinent creative in real-time for each user personally. Existing methods typically perform serial ranking of ads or creatives, limiting the creative module in terms of both effectiveness and efficiency. In this paper, we propose for the first time a novel architecture for online parallel estimation of ads and creatives ranking, as well as the corresponding offline joint optimization model. The online architecture enables sophisticated personalized creative modeling while reducing overall latency. The offline joint model for CTR estimation allows mutual awareness and collaborative optimization between ads and creatives. Additionally, we optimize the offline evaluation metrics for the implicit feedback sorting task involved in ad creative ranking. We conduct extensive experiments to compare ours with two state-of-the-art approaches. The results demonstrate the effectiveness of our approach in both offline evaluations and real-world advertising platforms online in terms of response time, CTR, and CPM.
RankDVQA-mini: Knowledge Distillation-Driven Deep Video Quality Assessment
Dec 14, 2023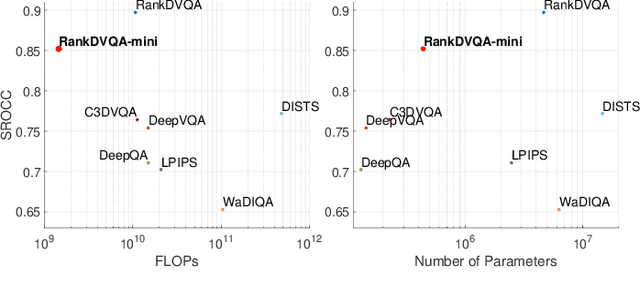
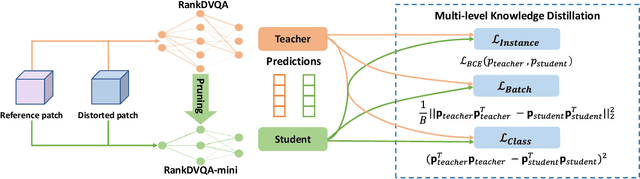
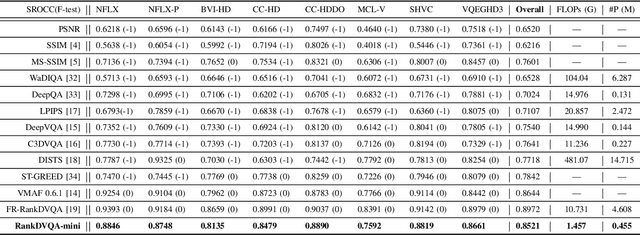
Deep learning-based video quality assessment (deep VQA) has demonstrated significant potential in surpassing conventional metrics, with promising improvements in terms of correlation with human perception. However, the practical deployment of such deep VQA models is often limited due to their high computational complexity and large memory requirements. To address this issue, we aim to significantly reduce the model size and runtime of one of the state-of-the-art deep VQA methods, RankDVQA, by employing a two-phase workflow that integrates pruning-driven model compression with multi-level knowledge distillation. The resulting lightweight quality metric, RankDVQA-mini, requires less than 10% of the model parameters compared to its full version (14% in terms of FLOPs), while still retaining a quality prediction performance that is superior to most existing deep VQA methods. The source code of the RankDVQA-mini has been released at https://chenfeng-bristol.github.io/RankDVQA-mini/ for public evaluation.