 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXinji Mai
Adaptive Multi-modal Fusion of Spatially Variant Kernel Refinement with Diffusion Model for Blind Image Super-Resolution
Mar 09, 2024
Pre-trained diffusion models utilized for image generation encapsulate a substantial reservoir of a priori knowledge pertaining to intricate textures. Harnessing the potential of leveraging this a priori knowledge in the context of image super-resolution presents a compelling avenue. Nonetheless, prevailing diffusion-based methodologies presently overlook the constraints imposed by degradation information on the diffusion process. Furthermore, these methods fail to consider the spatial variability inherent in the estimated blur kernel, stemming from factors such as motion jitter and out-of-focus elements in open-environment scenarios. This oversight results in a notable deviation of the image super-resolution effect from fundamental realities. To address these concerns, we introduce a framework known as Adaptive Multi-modal Fusion of \textbf{S}patially Variant Kernel Refinement with Diffusion Model for Blind Image \textbf{S}uper-\textbf{R}esolution (SSR). Within the SSR framework, we propose a Spatially Variant Kernel Refinement (SVKR) module. SVKR estimates a Depth-Informed Kernel, which takes the depth information into account and is spatially variant. Additionally, SVKR enhance the accuracy of depth information acquired from LR images, allowing for mutual enhancement between the depth map and blur kernel estimates. Finally, we introduce the Adaptive Multi-Modal Fusion (AMF) module to align the information from three modalities: low-resolution images, depth maps, and blur kernels. This alignment can constrain the diffusion model to generate more authentic SR results. Quantitative and qualitative experiments affirm the superiority of our approach, while ablation experiments corroborate the effectiveness of the modules we have proposed.
A$^{3}$lign-DFER: Pioneering Comprehensive Dynamic Affective Alignment for Dynamic Facial Expression Recognition with CLIP
Mar 07, 2024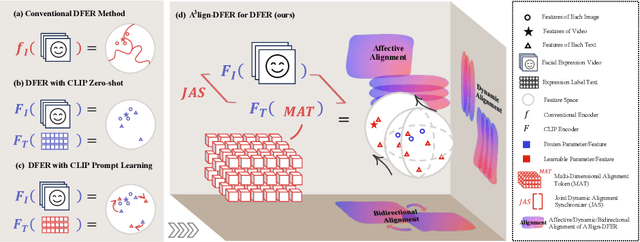
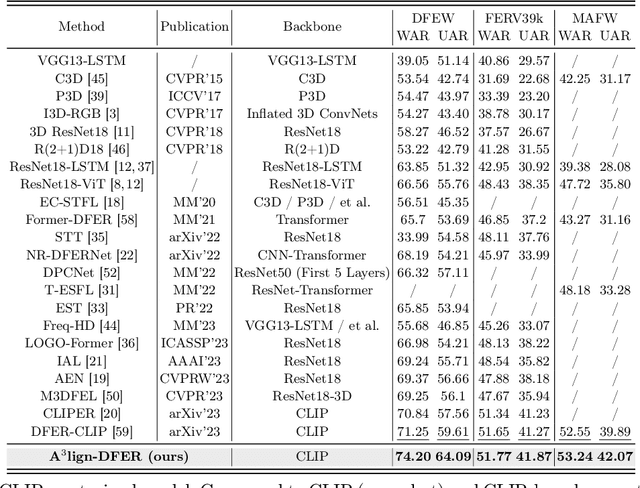
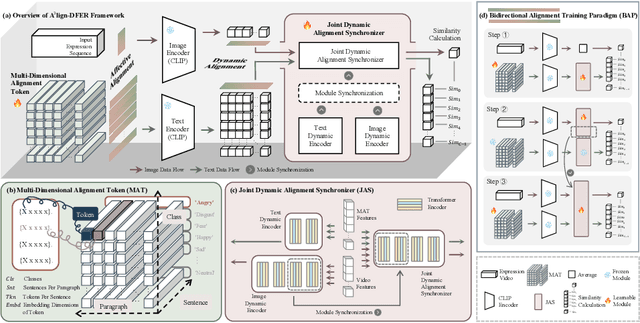
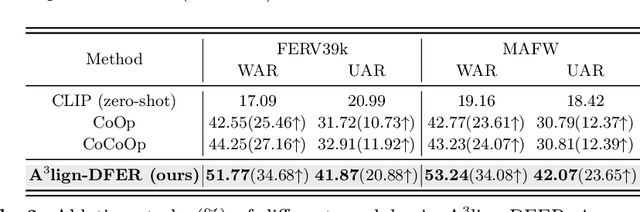
The performance of CLIP in dynamic facial expression recognition (DFER) task doesn't yield exceptional results as observed in other CLIP-based classification tasks. While CLIP's primary objective is to achieve alignment between images and text in the feature space, DFER poses challenges due to the abstract nature of text and the dynamic nature of video, making label representation limited and perfect alignment difficult. To address this issue, we have designed A$^{3}$lign-DFER, which introduces a new DFER labeling paradigm to comprehensively achieve alignment, thus enhancing CLIP's suitability for the DFER task. Specifically, our A$^{3}$lign-DFER method is designed with multiple modules that work together to obtain the most suitable expanded-dimensional embeddings for classification and to achieve alignment in three key aspects: affective, dynamic, and bidirectional. We replace the input label text with a learnable Multi-Dimensional Alignment Token (MAT), enabling alignment of text to facial expression video samples in both affective and dynamic dimensions. After CLIP feature extraction, we introduce the Joint Dynamic Alignment Synchronizer (JAS), further facilitating synchronization and alignment in the temporal dimension. Additionally, we implement a Bidirectional Alignment Training Paradigm (BAP) to ensure gradual and steady training of parameters for both modalities. Our insightful and concise A$^{3}$lign-DFER method achieves state-of-the-art results on multiple DFER datasets, including DFEW, FERV39k, and MAFW. Extensive ablation experiments and visualization studies demonstrate the effectiveness of A$^{3}$lign-DFER. The code will be available in the future.