 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZitong Yu
FusionMamba: Dynamic Feature Enhancement for Multimodal Image Fusion with Mamba
Apr 15, 2024
Multi-modal image fusion aims to combine information from different modes to create a single image with comprehensive information and detailed textures. However, fusion models based on convolutional neural networks encounter limitations in capturing global image features due to their focus on local convolution operations. Transformer-based models, while excelling in global feature modeling, confront computational challenges stemming from their quadratic complexity. Recently, the Selective Structured State Space Model has exhibited significant potential for long-range dependency modeling with linear complexity, offering a promising avenue to address the aforementioned dilemma. In this paper, we propose FusionMamba, a novel dynamic feature enhancement method for multimodal image fusion with Mamba. Specifically, we devise an improved efficient Mamba model for image fusion, integrating efficient visual state space model with dynamic convolution and channel attention. This refined model not only upholds the performance of Mamba and global modeling capability but also diminishes channel redundancy while enhancing local enhancement capability. Additionally, we devise a dynamic feature fusion module (DFFM) comprising two dynamic feature enhancement modules (DFEM) and a cross modality fusion mamba module (CMFM). The former serves for dynamic texture enhancement and dynamic difference perception, whereas the latter enhances correlation features between modes and suppresses redundant intermodal information. FusionMamba has yielded state-of-the-art (SOTA) performance across various multimodal medical image fusion tasks (CT-MRI, PET-MRI, SPECT-MRI), infrared and visible image fusion task (IR-VIS) and multimodal biomedical image fusion dataset (GFP-PC), which is proved that our model has generalization ability. The code for FusionMamba is available at https://github.com/millieXie/FusionMamba.
Multi-modal Document Presentation Attack Detection With Forensics Trace Disentanglement
Apr 10, 2024Document Presentation Attack Detection (DPAD) is an important measure in protecting the authenticity of a document image. However, recent DPAD methods demand additional resources, such as manual effort in collecting additional data or knowing the parameters of acquisition devices. This work proposes a DPAD method based on multi-modal disentangled traces (MMDT) without the above drawbacks. We first disentangle the recaptured traces by a self-supervised disentanglement and synthesis network to enhance the generalization capacity in document images with different contents and layouts. Then, unlike the existing DPAD approaches that rely only on data in the RGB domain, we propose to explicitly employ the disentangled recaptured traces as new modalities in the transformer backbone through adaptive multi-modal adapters to fuse RGB/trace features efficiently. Visualization of the disentangled traces confirms the effectiveness of the proposed method in different document contents. Extensive experiments on three benchmark datasets demonstrate the superiority of our MMDT method on representing forensic traces of recapturing distortion.
Safeguarding Medical Image Segmentation Datasets against Unauthorized Training via Contour- and Texture-Aware Perturbations
Mar 21, 2024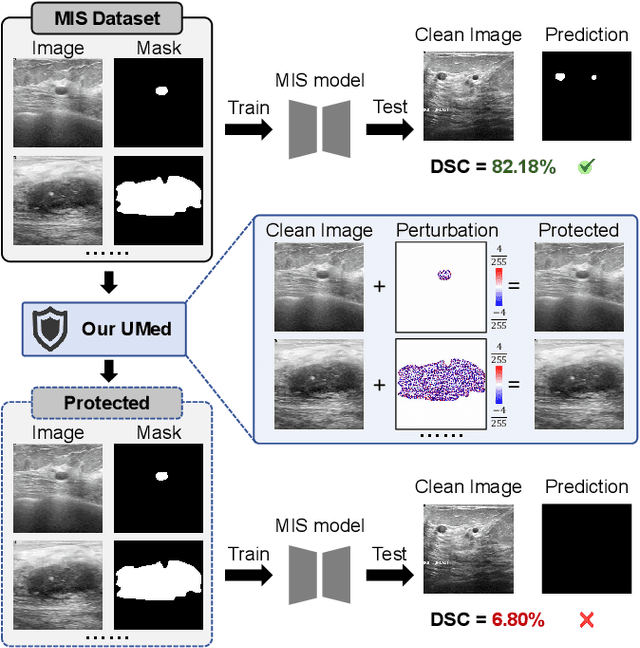
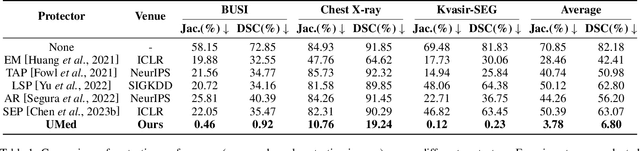
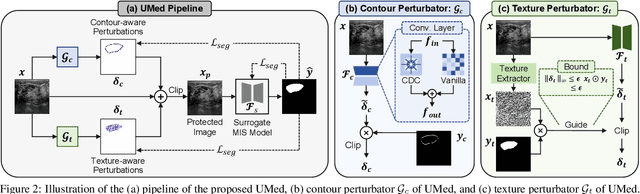
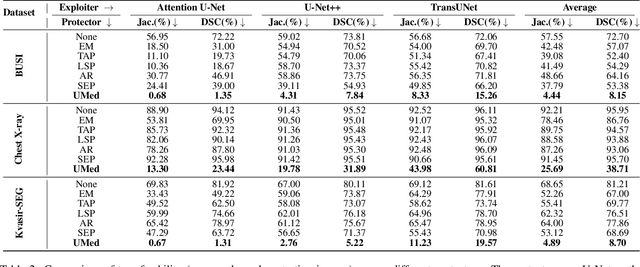
The widespread availability of publicly accessible medical images has significantly propelled advancements in various research and clinical fields. Nonetheless, concerns regarding unauthorized training of AI systems for commercial purposes and the duties of patient privacy protection have led numerous institutions to hesitate to share their images. This is particularly true for medical image segmentation (MIS) datasets, where the processes of collection and fine-grained annotation are time-intensive and laborious. Recently, Unlearnable Examples (UEs) methods have shown the potential to protect images by adding invisible shortcuts. These shortcuts can prevent unauthorized deep neural networks from generalizing. However, existing UEs are designed for natural image classification and fail to protect MIS datasets imperceptibly as their protective perturbations are less learnable than important prior knowledge in MIS, e.g., contour and texture features. To this end, we propose an Unlearnable Medical image generation method, termed UMed. UMed integrates the prior knowledge of MIS by injecting contour- and texture-aware perturbations to protect images. Given that our target is to only poison features critical to MIS, UMed requires only minimal perturbations within the ROI and its contour to achieve greater imperceptibility (average PSNR is 50.03) and protective performance (clean average DSC degrades from 82.18% to 6.80%).
Answering Diverse Questions via Text Attached with Key Audio-Visual Clues
Mar 11, 2024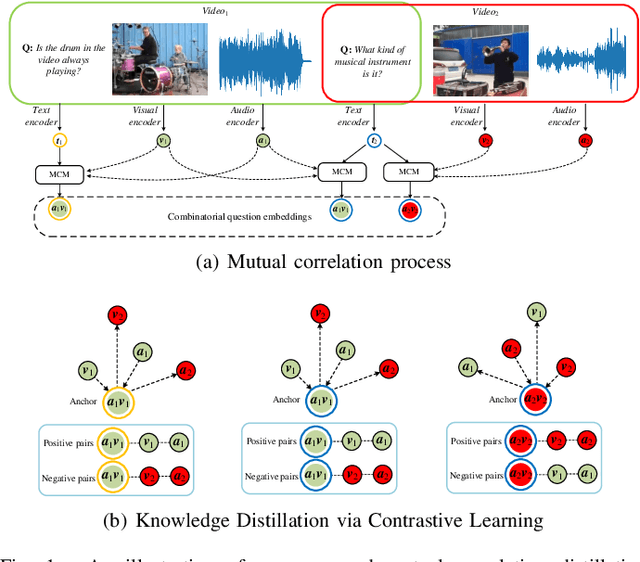
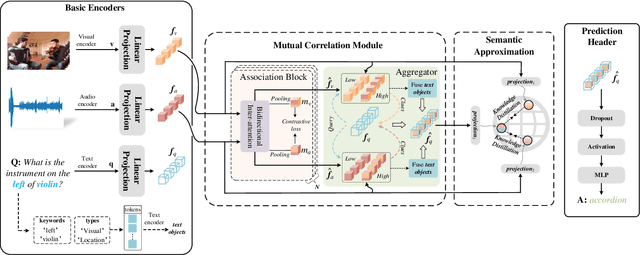
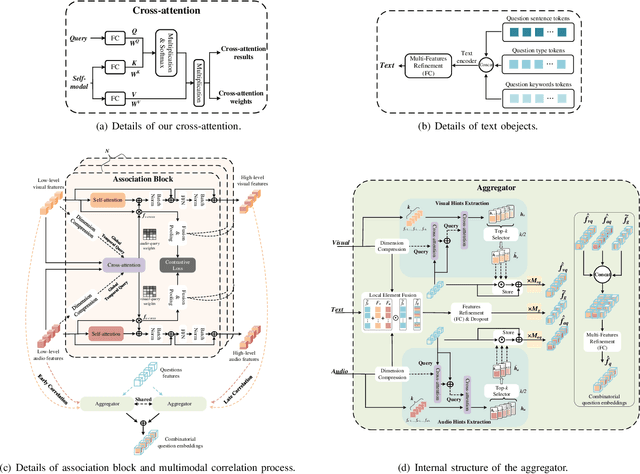
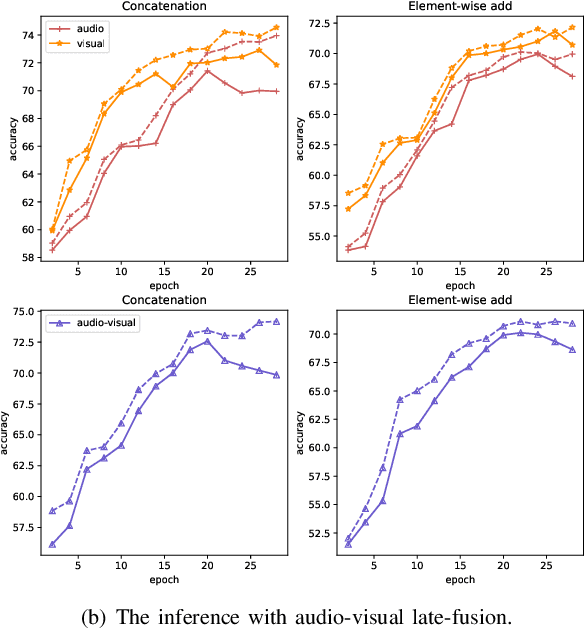
Audio-visual question answering (AVQA) requires reference to video content and auditory information, followed by correlating the question to predict the most precise answer. Although mining deeper layers of audio-visual information to interact with questions facilitates the multimodal fusion process, the redundancy of audio-visual parameters tends to reduce the generalization of the inference engine to multiple question-answer pairs in a single video. Indeed, the natural heterogeneous relationship between audiovisuals and text makes the perfect fusion challenging, to prevent high-level audio-visual semantics from weakening the network's adaptability to diverse question types, we propose a framework for performing mutual correlation distillation (MCD) to aid question inference. MCD is divided into three main steps: 1) firstly, the residual structure is utilized to enhance the audio-visual soft associations based on self-attention, then key local audio-visual features relevant to the question context are captured hierarchically by shared aggregators and coupled in the form of clues with specific question vectors. 2) Secondly, knowledge distillation is enforced to align audio-visual-text pairs in a shared latent space to narrow the cross-modal semantic gap. 3) And finally, the audio-visual dependencies are decoupled by discarding the decision-level integrations. We evaluate the proposed method on two publicly available datasets containing multiple question-and-answer pairs, i.e., Music-AVQA and AVQA. Experiments show that our method outperforms other state-of-the-art methods, and one interesting finding behind is that removing deep audio-visual features during inference can effectively mitigate overfitting. The source code is released at http://github.com/rikeilong/MCD-forAVQA.
GPT as Psychologist? Preliminary Evaluations for GPT-4V on Visual Affective Computing
Mar 09, 2024



Multimodal language models (MLMs) are designed to process and integrate information from multiple sources, such as text, speech, images, and videos. Despite its success in language understanding, it is critical to evaluate the performance of downstream tasks for better human-centric applications. This paper assesses the application of MLMs with 5 crucial abilities for affective computing, spanning from visual affective tasks and reasoning tasks. The results show that GPT4 has high accuracy in facial action unit recognition and micro-expression detection while its general facial expression recognition performance is not accurate. We also highlight the challenges of achieving fine-grained micro-expression recognition and the potential for further study and demonstrate the versatility and potential of GPT4 for handling advanced tasks in emotion recognition and related fields by integrating with task-related agents for more complex tasks, such as heart rate estimation through signal processing. In conclusion, this paper provides valuable insights into the potential applications and challenges of MLMs in human-centric computing. The interesting samples are available at \url{https://github.com/LuPaoPao/GPT4Affectivity}.
AUFormer: Vision Transformers are Parameter-Efficient Facial Action Unit Detectors
Mar 07, 2024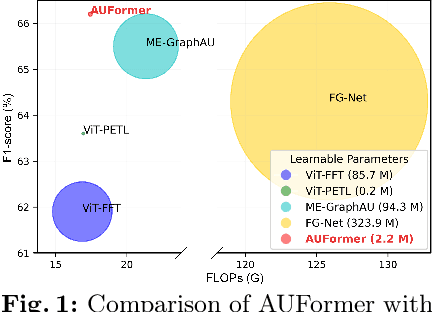
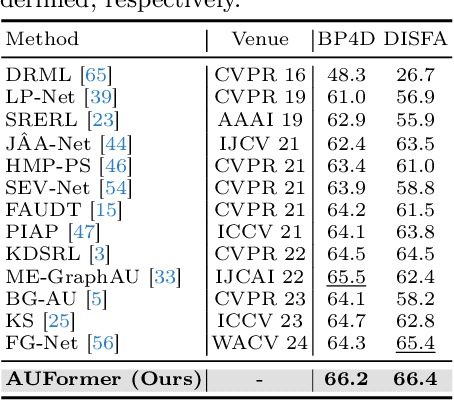
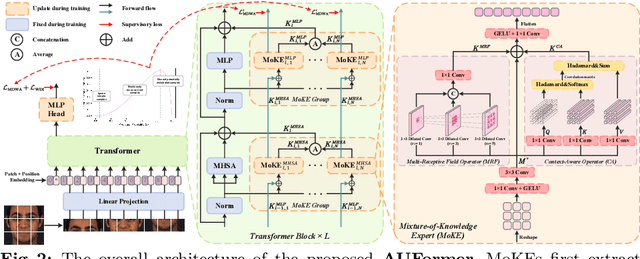
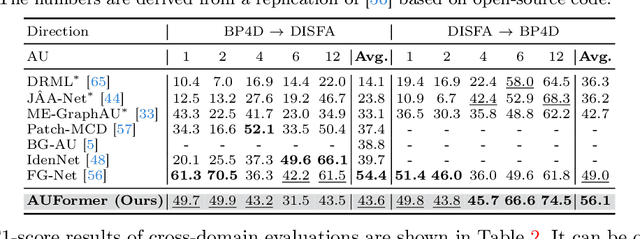
Facial Action Units (AU) is a vital concept in the realm of affective computing, and AU detection has always been a hot research topic. Existing methods suffer from overfitting issues due to the utilization of a large number of learnable parameters on scarce AU-annotated datasets or heavy reliance on substantial additional relevant data. Parameter-Efficient Transfer Learning (PETL) provides a promising paradigm to address these challenges, whereas its existing methods lack design for AU characteristics. Therefore, we innovatively investigate PETL paradigm to AU detection, introducing AUFormer and proposing a novel Mixture-of-Knowledge Expert (MoKE) collaboration mechanism. An individual MoKE specific to a certain AU with minimal learnable parameters first integrates personalized multi-scale and correlation knowledge. Then the MoKE collaborates with other MoKEs in the expert group to obtain aggregated information and inject it into the frozen Vision Transformer (ViT) to achieve parameter-efficient AU detection. Additionally, we design a Margin-truncated Difficulty-aware Weighted Asymmetric Loss (MDWA-Loss), which can encourage the model to focus more on activated AUs, differentiate the difficulty of unactivated AUs, and discard potential mislabeled samples. Extensive experiments from various perspectives, including within-domain, cross-domain, data efficiency, and micro-expression domain, demonstrate AUFormer's state-of-the-art performance and robust generalization abilities without relying on additional relevant data. The code for AUFormer is available at https://github.com/yuankaishen2001/AUFormer.
CAT: Enhancing Multimodal Large Language Model to Answer Questions in Dynamic Audio-Visual Scenarios
Mar 07, 2024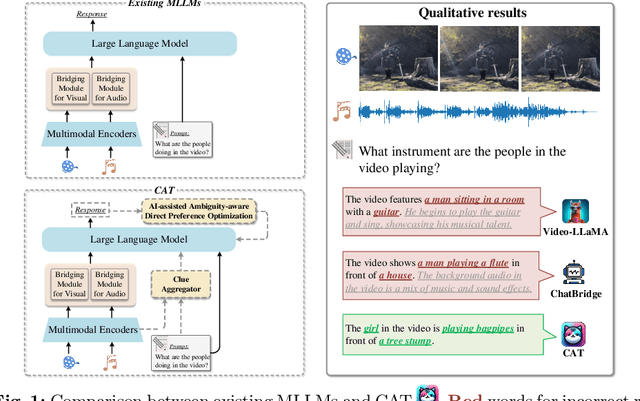
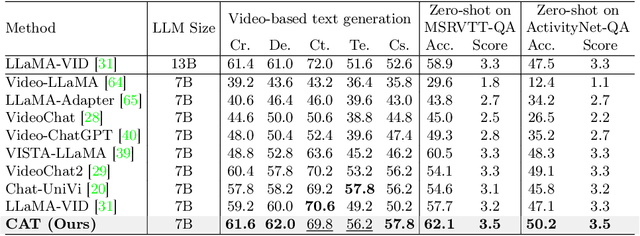
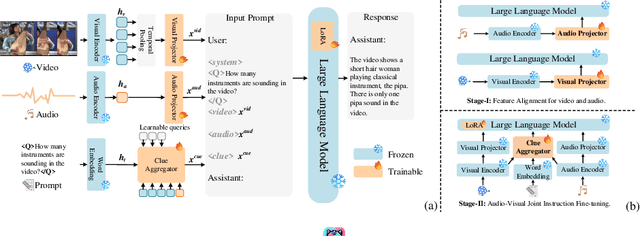
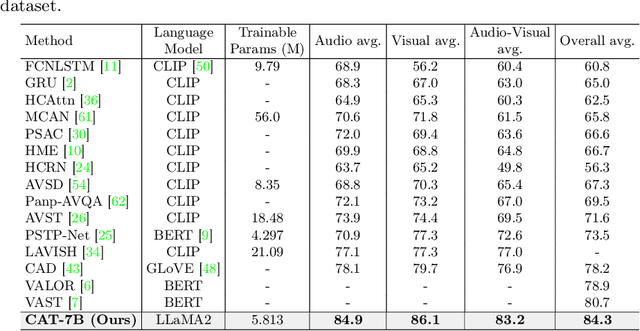
This paper focuses on the challenge of answering questions in scenarios that are composed of rich and complex dynamic audio-visual components. Although existing Multimodal Large Language Models (MLLMs) can respond to audio-visual content, these responses are sometimes ambiguous and fail to describe specific audio-visual events. To overcome this limitation, we introduce the CAT, which enhances MLLM in three ways: 1) besides straightforwardly bridging audio and video, we design a clue aggregator that aggregates question-related clues in dynamic audio-visual scenarios to enrich the detailed knowledge required for large language models. 2) CAT is trained on a mixed multimodal dataset, allowing direct application in audio-visual scenarios. Notably, we collect an audio-visual joint instruction dataset named AVinstruct, to further enhance the capacity of CAT to model cross-semantic correlations. 3) we propose AI-assisted ambiguity-aware direct preference optimization, a strategy specialized in retraining the model to favor the non-ambiguity response and improve the ability to localize specific audio-visual objects. Extensive experimental results demonstrate that CAT outperforms existing methods on multimodal tasks, especially in Audio-Visual Question Answering (AVQA) tasks. The codes and the collected instructions are released at https://github.com/rikeilong/Bay-CAT.
Suppress and Rebalance: Towards Generalized Multi-Modal Face Anti-Spoofing
Mar 05, 2024Face Anti-Spoofing (FAS) is crucial for securing face recognition systems against presentation attacks. With advancements in sensor manufacture and multi-modal learning techniques, many multi-modal FAS approaches have emerged. However, they face challenges in generalizing to unseen attacks and deployment conditions. These challenges arise from (1) modality unreliability, where some modality sensors like depth and infrared undergo significant domain shifts in varying environments, leading to the spread of unreliable information during cross-modal feature fusion, and (2) modality imbalance, where training overly relies on a dominant modality hinders the convergence of others, reducing effectiveness against attack types that are indistinguishable sorely using the dominant modality. To address modality unreliability, we propose the Uncertainty-Guided Cross-Adapter (U-Adapter) to recognize unreliably detected regions within each modality and suppress the impact of unreliable regions on other modalities. For modality imbalance, we propose a Rebalanced Modality Gradient Modulation (ReGrad) strategy to rebalance the convergence speed of all modalities by adaptively adjusting their gradients. Besides, we provide the first large-scale benchmark for evaluating multi-modal FAS performance under domain generalization scenarios. Extensive experiments demonstrate that our method outperforms state-of-the-art methods. Source code and protocols will be released on https://github.com/OMGGGGG/mmdg.
A Simple yet Effective Network based on Vision Transformer for Camouflaged Object and Salient Object Detection
Feb 29, 2024Camouflaged object detection (COD) and salient object detection (SOD) are two distinct yet closely-related computer vision tasks widely studied during the past decades. Though sharing the same purpose of segmenting an image into binary foreground and background regions, their distinction lies in the fact that COD focuses on concealed objects hidden in the image, while SOD concentrates on the most prominent objects in the image. Previous works achieved good performance by stacking various hand-designed modules and multi-scale features. However, these carefully-designed complex networks often performed well on one task but not on another. In this work, we propose a simple yet effective network (SENet) based on vision Transformer (ViT), by employing a simple design of an asymmetric ViT-based encoder-decoder structure, we yield competitive results on both tasks, exhibiting greater versatility than meticulously crafted ones. Furthermore, to enhance the Transformer's ability to model local information, which is important for pixel-level binary segmentation tasks, we propose a local information capture module (LICM). We also propose a dynamic weighted loss (DW loss) based on Binary Cross-Entropy (BCE) and Intersection over Union (IoU) loss, which guides the network to pay more attention to those smaller and more difficult-to-find target objects according to their size. Moreover, we explore the issue of joint training of SOD and COD, and propose a preliminary solution to the conflict in joint training, further improving the performance of SOD. Extensive experiments on multiple benchmark datasets demonstrate the effectiveness of our method. The code is available at https://github.com/linuxsino/SENet.