 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhilip Torr
Energy-Latency Manipulation of Multi-modal Large Language Models via Verbose Samples
Apr 25, 2024
Despite the exceptional performance of multi-modal large language models (MLLMs), their deployment requires substantial computational resources. Once malicious users induce high energy consumption and latency time (energy-latency cost), it will exhaust computational resources and harm availability of service. In this paper, we investigate this vulnerability for MLLMs, particularly image-based and video-based ones, and aim to induce high energy-latency cost during inference by crafting an imperceptible perturbation. We find that high energy-latency cost can be manipulated by maximizing the length of generated sequences, which motivates us to propose verbose samples, including verbose images and videos. Concretely, two modality non-specific losses are proposed, including a loss to delay end-of-sequence (EOS) token and an uncertainty loss to increase the uncertainty over each generated token. In addition, improving diversity is important to encourage longer responses by increasing the complexity, which inspires the following modality specific loss. For verbose images, a token diversity loss is proposed to promote diverse hidden states. For verbose videos, a frame feature diversity loss is proposed to increase the feature diversity among frames. To balance these losses, we propose a temporal weight adjustment algorithm. Experiments demonstrate that our verbose samples can largely extend the length of generated sequences.
An MRP Formulation for Supervised Learning: Generalized Temporal Difference Learning Models
Apr 23, 2024In traditional statistical learning, data points are usually assumed to be independently and identically distributed (i.i.d.) following an unknown probability distribution. This paper presents a contrasting viewpoint, perceiving data points as interconnected and employing a Markov reward process (MRP) for data modeling. We reformulate the typical supervised learning as an on-policy policy evaluation problem within reinforcement learning (RL), introducing a generalized temporal difference (TD) learning algorithm as a resolution. Theoretically, our analysis draws connections between the solutions of linear TD learning and ordinary least squares (OLS). We also show that under specific conditions, particularly when noises are correlated, the TD's solution proves to be a more effective estimator than OLS. Furthermore, we establish the convergence of our generalized TD algorithms under linear function approximation. Empirical studies verify our theoretical results, examine the vital design of our TD algorithm and show practical utility across various datasets, encompassing tasks such as regression and image classification with deep learning.
kNN-CLIP: Retrieval Enables Training-Free Segmentation on Continually Expanding Large Vocabularies
Apr 15, 2024Rapid advancements in continual segmentation have yet to bridge the gap of scaling to large continually expanding vocabularies under compute-constrained scenarios. We discover that traditional continual training leads to catastrophic forgetting under compute constraints, unable to outperform zero-shot segmentation methods. We introduce a novel strategy for semantic and panoptic segmentation with zero forgetting, capable of adapting to continually growing vocabularies without the need for retraining or large memory costs. Our training-free approach, kNN-CLIP, leverages a database of instance embeddings to enable open-vocabulary segmentation approaches to continually expand their vocabulary on any given domain with a single-pass through data, while only storing embeddings minimizing both compute and memory costs. This method achieves state-of-the-art mIoU performance across large-vocabulary semantic and panoptic segmentation datasets. We hope kNN-CLIP represents a step forward in enabling more efficient and adaptable continual segmentation, paving the way for advances in real-world large-vocabulary continual segmentation methods.
Latent Guard: a Safety Framework for Text-to-image Generation
Apr 11, 2024With the ability to generate high-quality images, text-to-image (T2I) models can be exploited for creating inappropriate content. To prevent misuse, existing safety measures are either based on text blacklists, which can be easily circumvented, or harmful content classification, requiring large datasets for training and offering low flexibility. Hence, we propose Latent Guard, a framework designed to improve safety measures in text-to-image generation. Inspired by blacklist-based approaches, Latent Guard learns a latent space on top of the T2I model's text encoder, where it is possible to check the presence of harmful concepts in the input text embeddings. Our proposed framework is composed of a data generation pipeline specific to the task using large language models, ad-hoc architectural components, and a contrastive learning strategy to benefit from the generated data. The effectiveness of our method is verified on three datasets and against four baselines. Code and data will be shared at https://github.com/rt219/LatentGuard.
AnimateZoo: Zero-shot Video Generation of Cross-Species Animation via Subject Alignment
Apr 07, 2024Recent video editing advancements rely on accurate pose sequences to animate subjects. However, these efforts are not suitable for cross-species animation due to pose misalignment between species (for example, the poses of a cat differs greatly from that of a pig due to differences in body structure). In this paper, we present AnimateZoo, a zero-shot diffusion-based video generator to address this challenging cross-species animation issue, aiming to accurately produce animal animations while preserving the background. The key technique used in our AnimateZoo is subject alignment, which includes two steps. First, we improve appearance feature extraction by integrating a Laplacian detail booster and a prompt-tuning identity extractor. These components are specifically designed to capture essential appearance information, including identity and fine details. Second, we align shape features and address conflicts from differing subjects by introducing a scale-information remover. This ensures accurate cross-species animation. Moreover, we introduce two high-quality animal video datasets featuring a wide variety of species. Trained on these extensive datasets, our model is capable of generating videos characterized by accurate movements, consistent appearance, and high-fidelity frames, without the need for the pre-inference fine-tuning that prior arts required. Extensive experiments showcase the outstanding performance of our method in cross-species action following tasks, demonstrating exceptional shape adaptation capability. The project page is available at https://justinxu0.github.io/AnimateZoo/.
Red Teaming GPT-4V: Are GPT-4V Safe Against Uni/Multi-Modal Jailbreak Attacks?
Apr 04, 2024Various jailbreak attacks have been proposed to red-team Large Language Models (LLMs) and revealed the vulnerable safeguards of LLMs. Besides, some methods are not limited to the textual modality and extend the jailbreak attack to Multimodal Large Language Models (MLLMs) by perturbing the visual input. However, the absence of a universal evaluation benchmark complicates the performance reproduction and fair comparison. Besides, there is a lack of comprehensive evaluation of closed-source state-of-the-art (SOTA) models, especially MLLMs, such as GPT-4V. To address these issues, this work first builds a comprehensive jailbreak evaluation dataset with 1445 harmful questions covering 11 different safety policies. Based on this dataset, extensive red-teaming experiments are conducted on 11 different LLMs and MLLMs, including both SOTA proprietary models and open-source models. We then conduct a deep analysis of the evaluated results and find that (1) GPT4 and GPT-4V demonstrate better robustness against jailbreak attacks compared to open-source LLMs and MLLMs. (2) Llama2 and Qwen-VL-Chat are more robust compared to other open-source models. (3) The transferability of visual jailbreak methods is relatively limited compared to textual jailbreak methods. The dataset and code can be found here https://anonymous.4open.science/r/red_teaming_gpt4-C1CE/README.md .
Model-agnostic Origin Attribution of Generated Images with Few-shot Examples
Apr 03, 2024Recent progress in visual generative models enables the generation of high-quality images. To prevent the misuse of generated images, it is important to identify the origin model that generates them. In this work, we study the origin attribution of generated images in a practical setting where only a few images generated by a source model are available and the source model cannot be accessed. The goal is to check if a given image is generated by the source model. We first formulate this problem as a few-shot one-class classification task. To solve the task, we propose OCC-CLIP, a CLIP-based framework for few-shot one-class classification, enabling the identification of an image's source model, even among multiple candidates. Extensive experiments corresponding to various generative models verify the effectiveness of our OCC-CLIP framework. Furthermore, an experiment based on the recently released DALL-E 3 API verifies the real-world applicability of our solution.
DreamPolisher: Towards High-Quality Text-to-3D Generation via Geometric Diffusion
Mar 25, 2024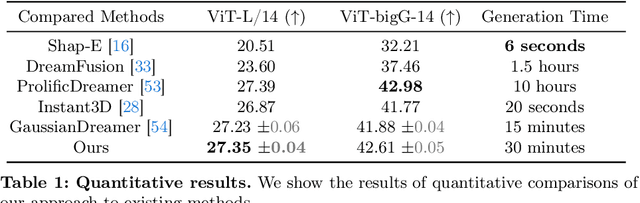

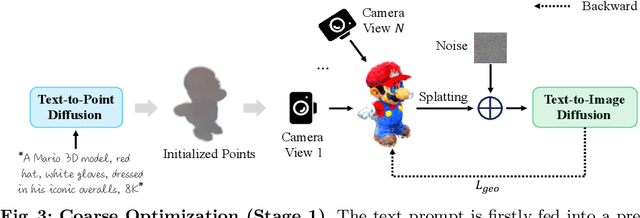

We present DreamPolisher, a novel Gaussian Splatting based method with geometric guidance, tailored to learn cross-view consistency and intricate detail from textual descriptions. While recent progress on text-to-3D generation methods have been promising, prevailing methods often fail to ensure view-consistency and textural richness. This problem becomes particularly noticeable for methods that work with text input alone. To address this, we propose a two-stage Gaussian Splatting based approach that enforces geometric consistency among views. Initially, a coarse 3D generation undergoes refinement via geometric optimization. Subsequently, we use a ControlNet driven refiner coupled with the geometric consistency term to improve both texture fidelity and overall consistency of the generated 3D asset. Empirical evaluations across diverse textual prompts spanning various object categories demonstrate the efficacy of DreamPolisher in generating consistent and realistic 3D objects, aligning closely with the semantics of the textual instructions.
RoDLA: Benchmarking the Robustness of Document Layout Analysis Models
Mar 21, 2024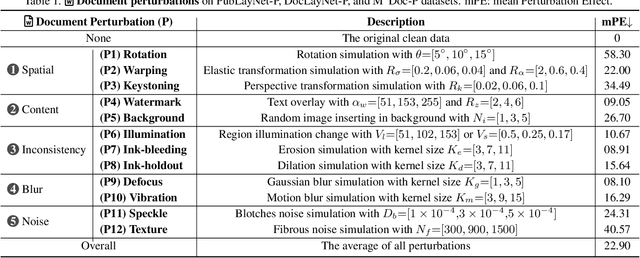


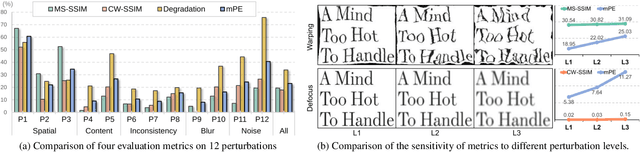
Before developing a Document Layout Analysis (DLA) model in real-world applications, conducting comprehensive robustness testing is essential. However, the robustness of DLA models remains underexplored in the literature. To address this, we are the first to introduce a robustness benchmark for DLA models, which includes 450K document images of three datasets. To cover realistic corruptions, we propose a perturbation taxonomy with 36 common document perturbations inspired by real-world document processing. Additionally, to better understand document perturbation impacts, we propose two metrics, Mean Perturbation Effect (mPE) for perturbation assessment and Mean Robustness Degradation (mRD) for robustness evaluation. Furthermore, we introduce a self-titled model, i.e., Robust Document Layout Analyzer (RoDLA), which improves attention mechanisms to boost extraction of robust features. Experiments on the proposed benchmarks (PubLayNet-P, DocLayNet-P, and M$^6$Doc-P) demonstrate that RoDLA obtains state-of-the-art mRD scores of 115.7, 135.4, and 150.4, respectively. Compared to previous methods, RoDLA achieves notable improvements in mAP of +3.8%, +7.1% and +12.1%, respectively.
On Pretraining Data Diversity for Self-Supervised Learning
Mar 20, 2024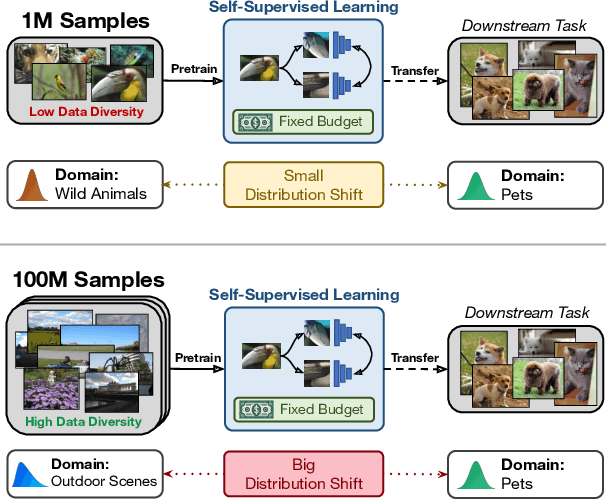


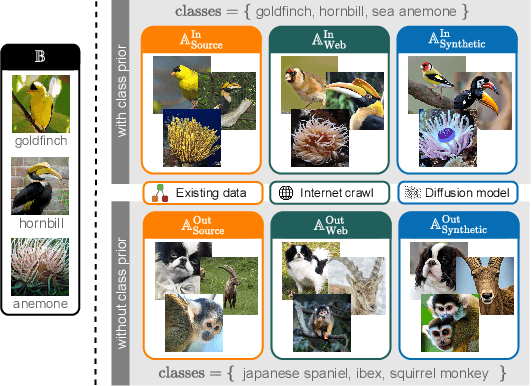
We explore the impact of training with more diverse datasets, characterized by the number of unique samples, on the performance of self-supervised learning (SSL) under a fixed computational budget. Our findings consistently demonstrate that increasing pretraining data diversity enhances SSL performance, albeit only when the distribution distance to the downstream data is minimal. Notably, even with an exceptionally large pretraining data diversity achieved through methods like web crawling or diffusion-generated data, among other ways, the distribution shift remains a challenge. Our experiments are comprehensive with seven SSL methods using large-scale datasets such as ImageNet and YFCC100M amounting to over 200 GPU days. Code and trained models will be available at https://github.com/hammoudhasan/DiversitySSL .