 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChenjun Xiao
An MRP Formulation for Supervised Learning: Generalized Temporal Difference Learning Models
Apr 23, 2024
In traditional statistical learning, data points are usually assumed to be independently and identically distributed (i.i.d.) following an unknown probability distribution. This paper presents a contrasting viewpoint, perceiving data points as interconnected and employing a Markov reward process (MRP) for data modeling. We reformulate the typical supervised learning as an on-policy policy evaluation problem within reinforcement learning (RL), introducing a generalized temporal difference (TD) learning algorithm as a resolution. Theoretically, our analysis draws connections between the solutions of linear TD learning and ordinary least squares (OLS). We also show that under specific conditions, particularly when noises are correlated, the TD's solution proves to be a more effective estimator than OLS. Furthermore, we establish the convergence of our generalized TD algorithms under linear function approximation. Empirical studies verify our theoretical results, examine the vital design of our TD algorithm and show practical utility across various datasets, encompassing tasks such as regression and image classification with deep learning.
Provable Representation with Efficient Planning for Partially Observable Reinforcement Learning
Nov 20, 2023In real-world reinforcement learning problems, the state information is often only partially observable, which breaks the basic assumption in Markov decision processes, and thus, leads to inferior performances. Partially Observable Markov Decision Processes have been introduced to explicitly take the issue into account for learning, exploration, and planning, but presenting significant computational and statistical challenges. To address these difficulties, we exploit the representation view, which leads to a coherent design framework for a practically tractable reinforcement learning algorithm upon partial observations. We provide a theoretical analysis for justifying the statistical efficiency of the proposed algorithm. We also empirically demonstrate the proposed algorithm can surpass state-of-the-art performance with partial observations across various benchmarks, therefore, pushing reliable reinforcement learning towards more practical applications.
Rethinking Decision Transformer via Hierarchical Reinforcement Learning
Nov 01, 2023Decision Transformer (DT) is an innovative algorithm leveraging recent advances of the transformer architecture in reinforcement learning (RL). However, a notable limitation of DT is its reliance on recalling trajectories from datasets, losing the capability to seamlessly stitch sub-optimal trajectories together. In this work we introduce a general sequence modeling framework for studying sequential decision making through the lens of Hierarchical RL. At the time of making decisions, a high-level policy first proposes an ideal prompt for the current state, a low-level policy subsequently generates an action conditioned on the given prompt. We show DT emerges as a special case of this framework with certain choices of high-level and low-level policies, and discuss the potential failure of these choices. Inspired by these observations, we study how to jointly optimize the high-level and low-level policies to enable the stitching ability, which further leads to the development of new offline RL algorithms. Our empirical results clearly show that the proposed algorithms significantly surpass DT on several control and navigation benchmarks. We hope our contributions can inspire the integration of transformer architectures within the field of RL.
In-Sample Policy Iteration for Offline Reinforcement Learning
Jun 09, 2023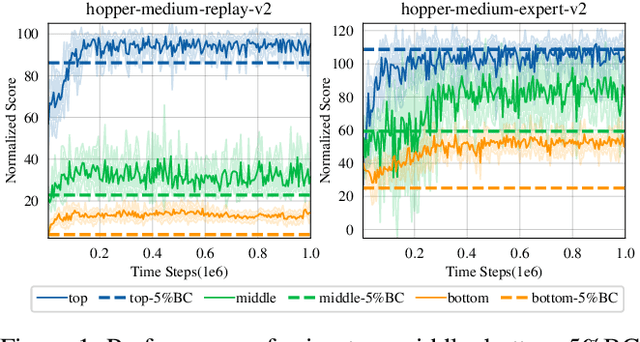



Offline reinforcement learning (RL) seeks to derive an effective control policy from previously collected data. To circumvent errors due to inadequate data coverage, behavior-regularized methods optimize the control policy while concurrently minimizing deviation from the data collection policy. Nevertheless, these methods often exhibit subpar practical performance, particularly when the offline dataset is collected by sub-optimal policies. In this paper, we propose a novel algorithm employing in-sample policy iteration that substantially enhances behavior-regularized methods in offline RL. The core insight is that by continuously refining the policy used for behavior regularization, in-sample policy iteration gradually improves itself while implicitly avoids querying out-of-sample actions to avert catastrophic learning failures. Our theoretical analysis verifies its ability to learn the in-sample optimal policy, exclusively utilizing actions well-covered by the dataset. Moreover, we propose competitive policy improvement, a technique applying two competitive policies, both of which are trained by iteratively improving over the best competitor. We show that this simple yet potent technique significantly enhances learning efficiency when function approximation is applied. Lastly, experimental results on the D4RL benchmark indicate that our algorithm outperforms previous state-of-the-art methods in most tasks.
Conditionally Optimistic Exploration for Cooperative Deep Multi-Agent Reinforcement Learning
Mar 16, 2023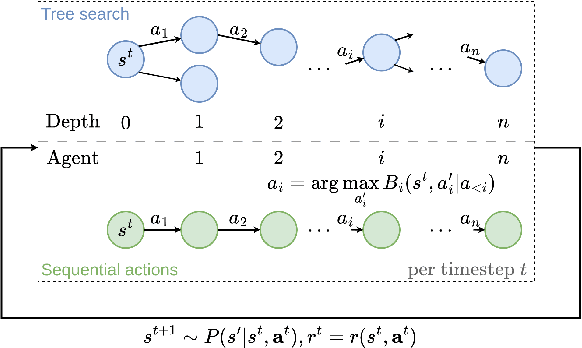


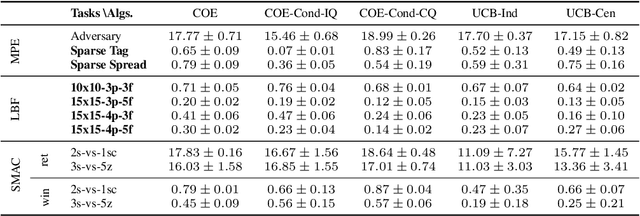
Efficient exploration is critical in cooperative deep Multi-Agent Reinforcement Learning (MARL). In this paper, we propose an exploration method that efficiently encourages cooperative exploration based on the idea of the theoretically justified tree search algorithm UCT (Upper Confidence bounds applied to Trees). The high-level intuition is that to perform optimism-based exploration, agents would achieve cooperative strategies if each agent's optimism estimate captures a structured dependency relationship with other agents. At each node (i.e., action) of the search tree, UCT performs optimism-based exploration using a bonus derived by conditioning on the visitation count of its parent node. We provide a perspective to view MARL as tree search iterations and develop a method called Conditionally Optimistic Exploration (COE). We assume agents take actions following a sequential order, and consider nodes at the same depth of the search tree as actions of one individual agent. COE computes each agent's state-action value estimate with an optimistic bonus derived from the visitation count of the state and joint actions taken by agents up to the current agent. COE is adaptable to any value decomposition method for centralized training with decentralized execution. Experiments across various cooperative MARL benchmarks show that COE outperforms current state-of-the-art exploration methods on hard-exploration tasks.
The In-Sample Softmax for Offline Reinforcement Learning
Feb 28, 2023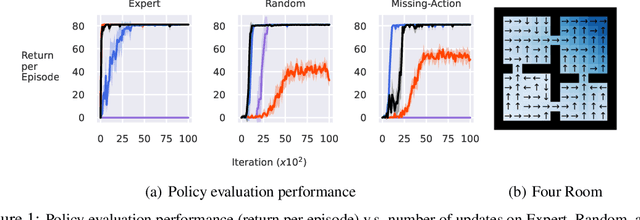
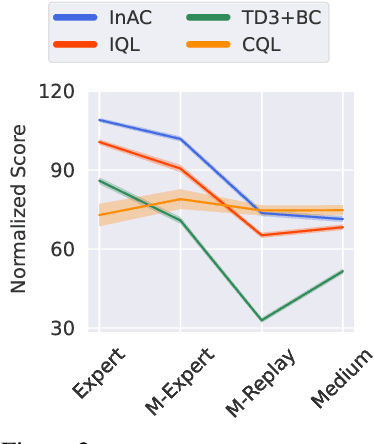
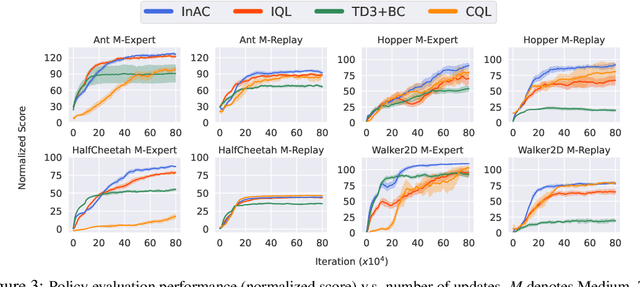
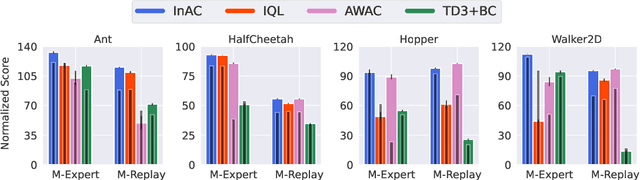
Reinforcement learning (RL) agents can leverage batches of previously collected data to extract a reasonable control policy. An emerging issue in this offline RL setting, however, is that the bootstrapping update underlying many of our methods suffers from insufficient action-coverage: standard max operator may select a maximal action that has not been seen in the dataset. Bootstrapping from these inaccurate values can lead to overestimation and even divergence. There are a growing number of methods that attempt to approximate an \emph{in-sample} max, that only uses actions well-covered by the dataset. We highlight a simple fact: it is more straightforward to approximate an in-sample \emph{softmax} using only actions in the dataset. We show that policy iteration based on the in-sample softmax converges, and that for decreasing temperatures it approaches the in-sample max. We derive an In-Sample Actor-Critic (AC), using this in-sample softmax, and show that it is consistently better or comparable to existing offline RL methods, and is also well-suited to fine-tuning.
Latent Variable Representation for Reinforcement Learning
Dec 17, 2022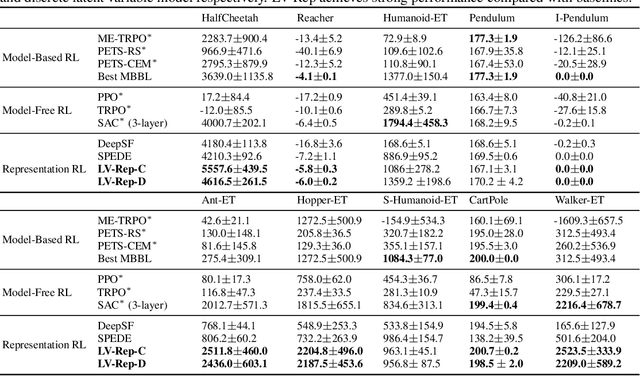


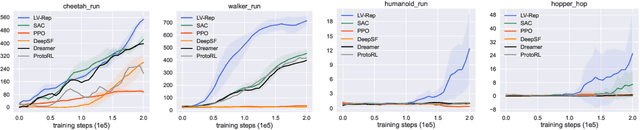
Deep latent variable models have achieved significant empirical successes in model-based reinforcement learning (RL) due to their expressiveness in modeling complex transition dynamics. On the other hand, it remains unclear theoretically and empirically how latent variable models may facilitate learning, planning, and exploration to improve the sample efficiency of RL. In this paper, we provide a representation view of the latent variable models for state-action value functions, which allows both tractable variational learning algorithm and effective implementation of the optimism/pessimism principle in the face of uncertainty for exploration. In particular, we propose a computationally efficient planning algorithm with UCB exploration by incorporating kernel embeddings of latent variable models. Theoretically, we establish the sample complexity of the proposed approach in the online and offline settings. Empirically, we demonstrate superior performance over current state-of-the-art algorithms across various benchmarks.
Understanding the Effect of Stochasticity in Policy Optimization
Oct 29, 2021

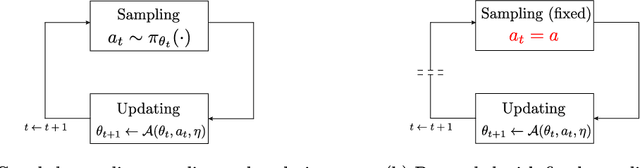
We study the effect of stochasticity in on-policy policy optimization, and make the following four contributions. First, we show that the preferability of optimization methods depends critically on whether stochastic versus exact gradients are used. In particular, unlike the true gradient setting, geometric information cannot be easily exploited in the stochastic case for accelerating policy optimization without detrimental consequences or impractical assumptions. Second, to explain these findings we introduce the concept of committal rate for stochastic policy optimization, and show that this can serve as a criterion for determining almost sure convergence to global optimality. Third, we show that in the absence of external oracle information, which allows an algorithm to determine the difference between optimal and sub-optimal actions given only on-policy samples, there is an inherent trade-off between exploiting geometry to accelerate convergence versus achieving optimality almost surely. That is, an uninformed algorithm either converges to a globally optimal policy with probability $1$ but at a rate no better than $O(1/t)$, or it achieves faster than $O(1/t)$ convergence but then must fail to converge to the globally optimal policy with some positive probability. Finally, we use the committal rate theory to explain why practical policy optimization methods are sensitive to random initialization, then develop an ensemble method that can be guaranteed to achieve near-optimal solutions with high probability.
On the Sample Complexity of Batch Reinforcement Learning with Policy-Induced Data
Jun 18, 2021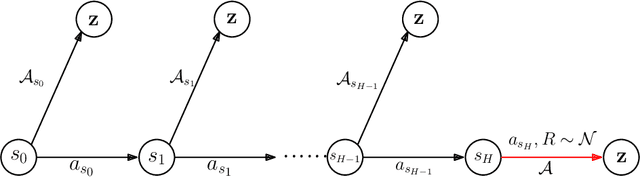
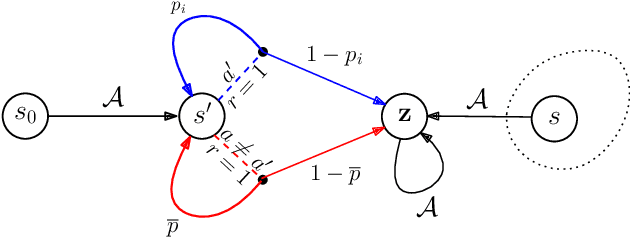
We study the fundamental question of the sample complexity of learning a good policy in finite Markov decision processes (MDPs) when the data available for learning is obtained by following a logging policy that must be chosen without knowledge of the underlying MDP. Our main results show that the sample complexity, the minimum number of transitions necessary and sufficient to obtain a good policy, is an exponential function of the relevant quantities when the planning horizon $H$ is finite. In particular, we prove that the sample complexity of obtaining $\epsilon$-optimal policies is at least $\Omega(\mathrm{A}^{\min(\mathrm{S}-1, H+1)})$ for $\gamma$-discounted problems, where $\mathrm{S}$ is the number of states, $\mathrm{A}$ is the number of actions, and $H$ is the effective horizon defined as $H=\lfloor \tfrac{\ln(1/\epsilon)}{\ln(1/\gamma)} \rfloor$; and it is at least $\Omega(\mathrm{A}^{\min(\mathrm{S}-1, H)}/\varepsilon^2)$ for finite horizon problems, where $H$ is the planning horizon of the problem. This lower bound is essentially matched by an upper bound. For the average-reward setting we show that there is no algorithm finding $\epsilon$-optimal policies with a finite amount of data.
On the Optimality of Batch Policy Optimization Algorithms
Apr 06, 2021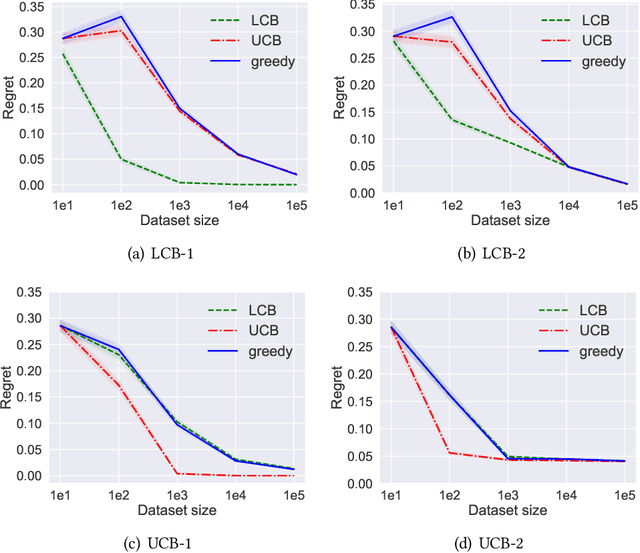
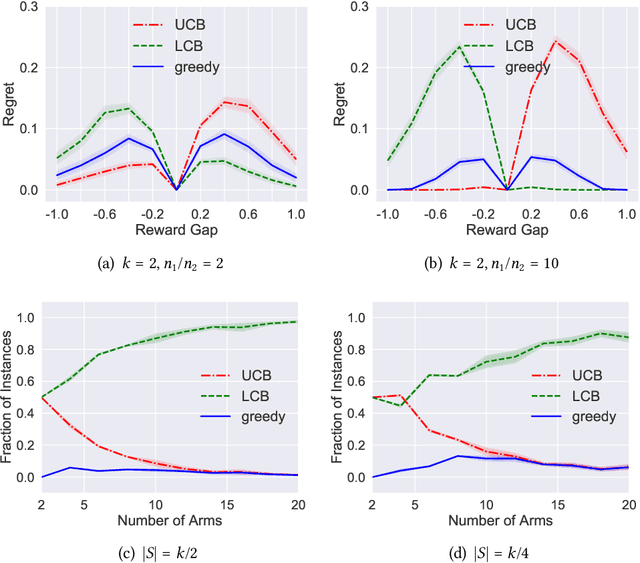
Batch policy optimization considers leveraging existing data for policy construction before interacting with an environment. Although interest in this problem has grown significantly in recent years, its theoretical foundations remain under-developed. To advance the understanding of this problem, we provide three results that characterize the limits and possibilities of batch policy optimization in the finite-armed stochastic bandit setting. First, we introduce a class of confidence-adjusted index algorithms that unifies optimistic and pessimistic principles in a common framework, which enables a general analysis. For this family, we show that any confidence-adjusted index algorithm is minimax optimal, whether it be optimistic, pessimistic or neutral. Our analysis reveals that instance-dependent optimality, commonly used to establish optimality of on-line stochastic bandit algorithms, cannot be achieved by any algorithm in the batch setting. In particular, for any algorithm that performs optimally in some environment, there exists another environment where the same algorithm suffers arbitrarily larger regret. Therefore, to establish a framework for distinguishing algorithms, we introduce a new weighted-minimax criterion that considers the inherent difficulty of optimal value prediction. We demonstrate how this criterion can be used to justify commonly used pessimistic principles for batch policy optimization.