 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiaming Zhang
GBEC: Geometry-Based Hand-Eye Calibration
Apr 08, 2024
Hand-eye calibration is the problem of solving the transformation from the end-effector of a robot to the sensor attached to it. Commonly employed techniques, such as AXXB or AXZB formulations, rely on regression methods that require collecting pose data from different robot configurations, which can produce low accuracy and repeatability. However, the derived transformation should solely depend on the geometry of the end-effector and the sensor attachment. We propose Geometry-Based End-Effector Calibration (GBEC) that enhances the repeatability and accuracy of the derived transformation compared to traditional hand-eye calibrations. To demonstrate improvements, we apply the approach to two different robot-assisted procedures: Transcranial Magnetic Stimulation (TMS) and femoroplasty. We also discuss the generalizability of GBEC for camera-in-hand and marker-in-hand sensor mounting methods. In the experiments, we perform GBEC between the robot end-effector and an optical tracker's rigid body marker attached to the TMS coil or femoroplasty drill guide. Previous research documents low repeatability and accuracy of the conventional methods for robot-assisted TMS hand-eye calibration. When compared to some existing methods, the proposed method relies solely on the geometry of the flange and the pose of the rigid-body marker, making it independent of workspace constraints or robot accuracy, without sacrificing the orthogonality of the rotation matrix. Our results validate the accuracy and applicability of the approach, providing a new and generalizable methodology for obtaining the transformation from the end-effector to a sensor.
Segment Any Medical Model Extended
Mar 26, 2024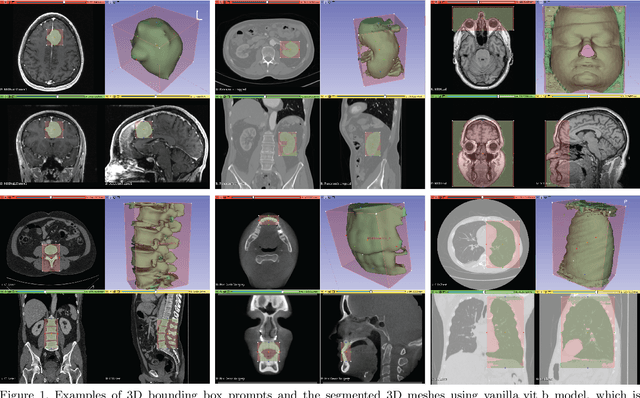

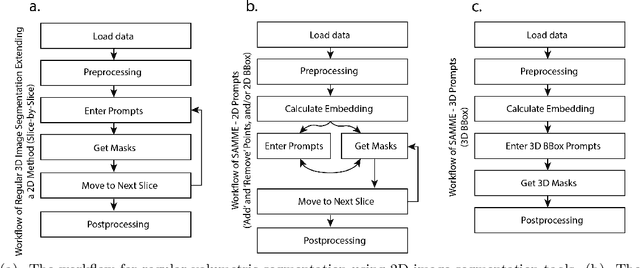
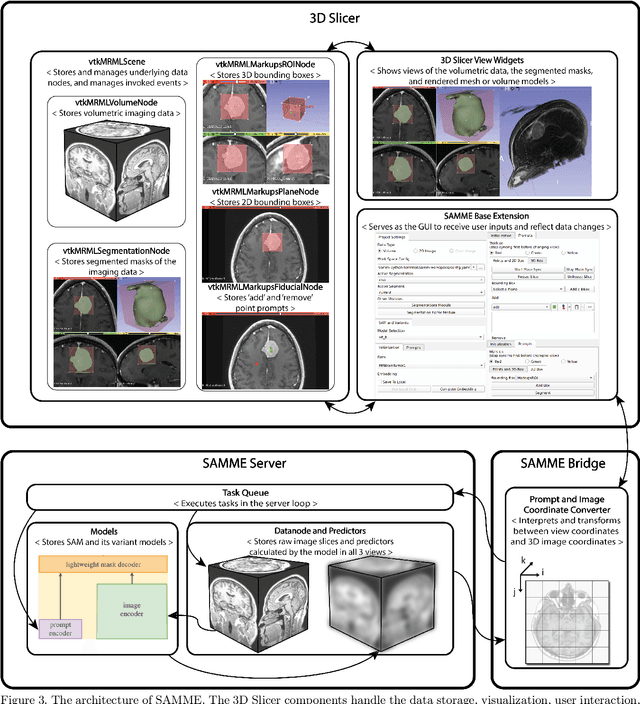
The Segment Anything Model (SAM) has drawn significant attention from researchers who work on medical image segmentation because of its generalizability. However, researchers have found that SAM may have limited performance on medical images compared to state-of-the-art non-foundation models. Regardless, the community sees potential in extending, fine-tuning, modifying, and evaluating SAM for analysis of medical imaging. An increasing number of works have been published focusing on the mentioned four directions, where variants of SAM are proposed. To this end, a unified platform helps push the boundary of the foundation model for medical images, facilitating the use, modification, and validation of SAM and its variants in medical image segmentation. In this work, we introduce SAMM Extended (SAMME), a platform that integrates new SAM variant models, adopts faster communication protocols, accommodates new interactive modes, and allows for fine-tuning of subcomponents of the models. These features can expand the potential of foundation models like SAM, and the results can be translated to applications such as image-guided therapy, mixed reality interaction, robotic navigation, and data augmentation.
Realtime Robust Shape Estimation of Deformable Linear Object
Mar 24, 2024Realtime shape estimation of continuum objects and manipulators is essential for developing accurate planning and control paradigms. The existing methods that create dense point clouds from camera images, and/or use distinguishable markers on a deformable body have limitations in realtime tracking of large continuum objects/manipulators. The physical occlusion of markers can often compromise accurate shape estimation. We propose a robust method to estimate the shape of linear deformable objects in realtime using scattered and unordered key points. By utilizing a robust probability-based labeling algorithm, our approach identifies the true order of the detected key points and then reconstructs the shape using piecewise spline interpolation. The approach only relies on knowing the number of the key points and the interval between two neighboring points. We demonstrate the robustness of the method when key points are partially occluded. The proposed method is also integrated into a simulation in Unity for tracking the shape of a cable with a length of 1m and a radius of 5mm. The simulation results show that our proposed approach achieves an average length error of 1.07% over the continuum's centerline and an average cross-section error of 2.11mm. The real-world experiments of tracking and estimating a heavy-load cable prove that the proposed approach is robust under occlusion and complex entanglement scenarios.
RoDLA: Benchmarking the Robustness of Document Layout Analysis Models
Mar 21, 2024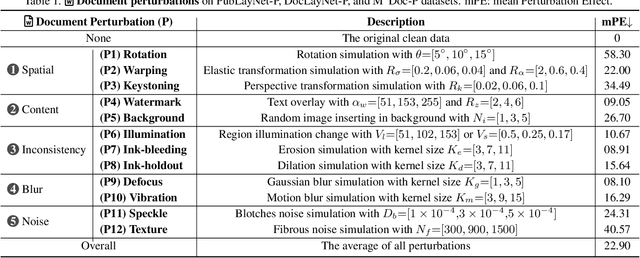


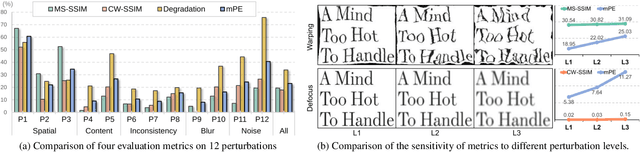
Before developing a Document Layout Analysis (DLA) model in real-world applications, conducting comprehensive robustness testing is essential. However, the robustness of DLA models remains underexplored in the literature. To address this, we are the first to introduce a robustness benchmark for DLA models, which includes 450K document images of three datasets. To cover realistic corruptions, we propose a perturbation taxonomy with 36 common document perturbations inspired by real-world document processing. Additionally, to better understand document perturbation impacts, we propose two metrics, Mean Perturbation Effect (mPE) for perturbation assessment and Mean Robustness Degradation (mRD) for robustness evaluation. Furthermore, we introduce a self-titled model, i.e., Robust Document Layout Analyzer (RoDLA), which improves attention mechanisms to boost extraction of robust features. Experiments on the proposed benchmarks (PubLayNet-P, DocLayNet-P, and M$^6$Doc-P) demonstrate that RoDLA obtains state-of-the-art mRD scores of 115.7, 135.4, and 150.4, respectively. Compared to previous methods, RoDLA achieves notable improvements in mAP of +3.8%, +7.1% and +12.1%, respectively.
Skeleton-Based Human Action Recognition with Noisy Labels
Mar 15, 2024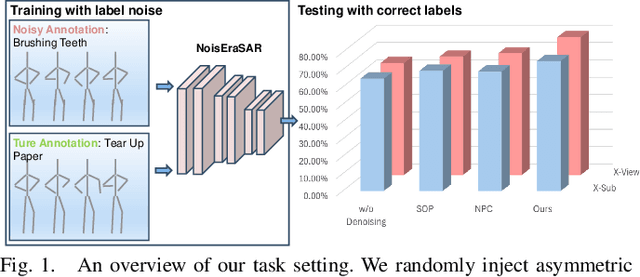
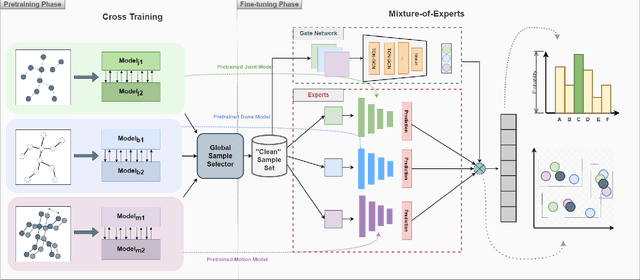
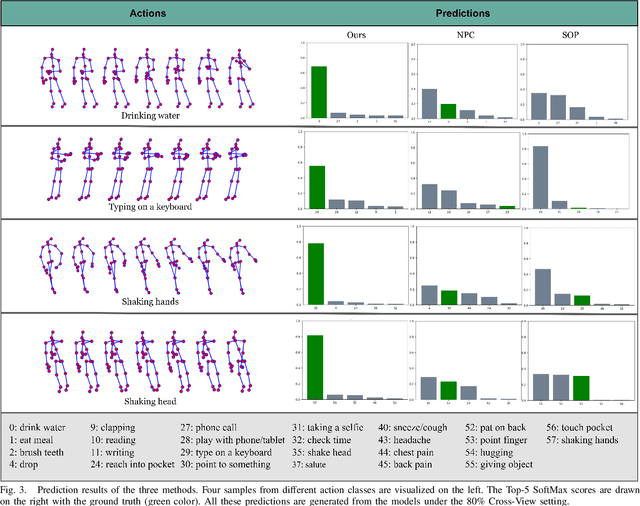
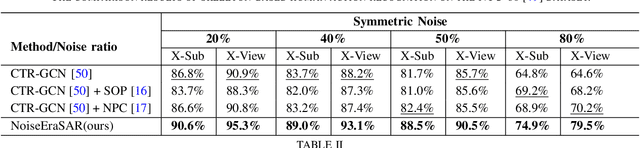
Understanding human actions from body poses is critical for assistive robots sharing space with humans in order to make informed and safe decisions about the next interaction. However, precise temporal localization and annotation of activity sequences is time-consuming and the resulting labels are often noisy. If not effectively addressed, label noise negatively affects the model's training, resulting in lower recognition quality. Despite its importance, addressing label noise for skeleton-based action recognition has been overlooked so far. In this study, we bridge this gap by implementing a framework that augments well-established skeleton-based human action recognition methods with label-denoising strategies from various research areas to serve as the initial benchmark. Observations reveal that these baselines yield only marginal performance when dealing with sparse skeleton data. Consequently, we introduce a novel methodology, NoiseEraSAR, which integrates global sample selection, co-teaching, and Cross-Modal Mixture-of-Experts (CM-MOE) strategies, aimed at mitigating the adverse impacts of label noise. Our proposed approach demonstrates better performance on the established benchmark, setting new state-of-the-art standards. The source code for this study will be made accessible at https://github.com/xuyizdby/NoiseEraSAR.
OccFiner: Offboard Occupancy Refinement with Hybrid Propagation
Mar 15, 2024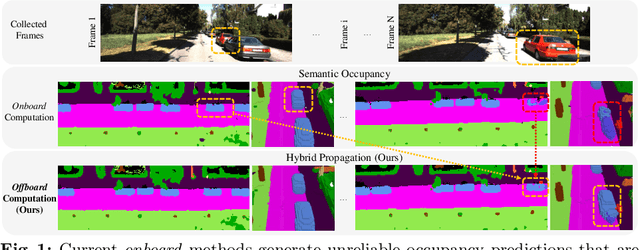
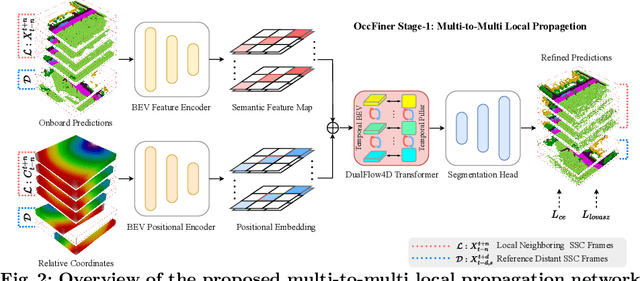
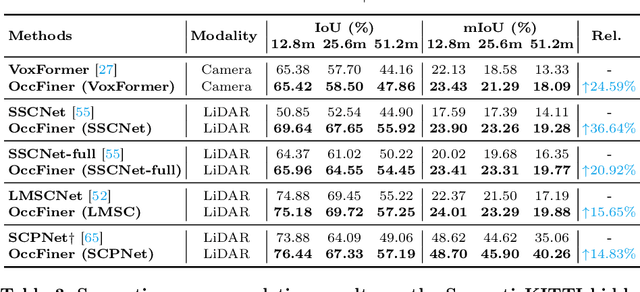
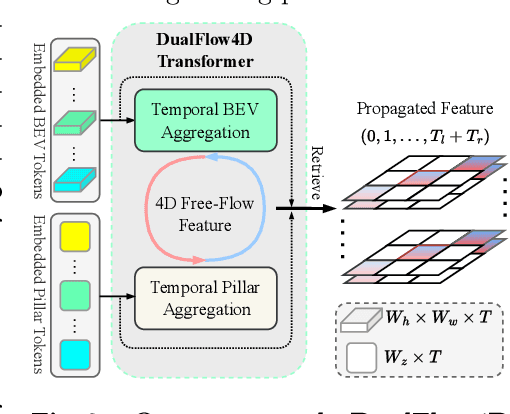
Vision-based occupancy prediction, also known as 3D Semantic Scene Completion (SSC), presents a significant challenge in computer vision. Previous methods, confined to onboard processing, struggle with simultaneous geometric and semantic estimation, continuity across varying viewpoints, and single-view occlusion. Our paper introduces OccFiner, a novel offboard framework designed to enhance the accuracy of vision-based occupancy predictions. OccFiner operates in two hybrid phases: 1) a multi-to-multi local propagation network that implicitly aligns and processes multiple local frames for correcting onboard model errors and consistently enhancing occupancy accuracy across all distances. 2) the region-centric global propagation, focuses on refining labels using explicit multi-view geometry and integrating sensor bias, especially to increase the accuracy of distant occupied voxels. Extensive experiments demonstrate that OccFiner improves both geometric and semantic accuracy across various types of coarse occupancy, setting a new state-of-the-art performance on the SemanticKITTI dataset. Notably, OccFiner elevates vision-based SSC models to a level even surpassing that of LiDAR-based onboard SSC models.
Large Language Model for Table Processing: A Survey
Feb 04, 2024Tables, typically two-dimensional and structured to store large amounts of data, are essential in daily activities like database queries, spreadsheet calculations, and generating reports from web tables. Automating these table-centric tasks with Large Language Models (LLMs) offers significant public benefits, garnering interest from academia and industry. This survey provides an extensive overview of table tasks, encompassing not only the traditional areas like table question answering (Table QA) and fact verification, but also newly emphasized aspects such as table manipulation and advanced table data analysis. Additionally, it goes beyond the early strategies of pre-training and fine-tuning small language models, to include recent paradigms in LLM usage. The focus here is particularly on instruction-tuning, prompting, and agent-based approaches within the realm of LLMs. Finally, we highlight several challenges, ranging from private deployment and efficient inference to the development of extensive benchmarks for table manipulation and advanced data analysis.
Fourier Prompt Tuning for Modality-Incomplete Scene Segmentation
Jan 30, 2024Integrating information from multiple modalities enhances the robustness of scene perception systems in autonomous vehicles, providing a more comprehensive and reliable sensory framework. However, the modality incompleteness in multi-modal segmentation remains under-explored. In this work, we establish a task called Modality-Incomplete Scene Segmentation (MISS), which encompasses both system-level modality absence and sensor-level modality errors. To avoid the predominant modality reliance in multi-modal fusion, we introduce a Missing-aware Modal Switch (MMS) strategy to proactively manage missing modalities during training. Utilizing bit-level batch-wise sampling enhances the model's performance in both complete and incomplete testing scenarios. Furthermore, we introduce the Fourier Prompt Tuning (FPT) method to incorporate representative spectral information into a limited number of learnable prompts that maintain robustness against all MISS scenarios. Akin to fine-tuning effects but with fewer tunable parameters (1.1%). Extensive experiments prove the efficacy of our proposed approach, showcasing an improvement of 5.84% mIoU over the prior state-of-the-art parameter-efficient methods in modality missing. The source code will be publicly available at https://github.com/RuipingL/MISS.
LF Tracy: A Unified Single-Pipeline Approach for Salient Object Detection in Light Field Cameras
Jan 30, 2024Leveraging the rich information extracted from light field (LF) cameras is instrumental for dense prediction tasks. However, adapting light field data to enhance Salient Object Detection (SOD) still follows the traditional RGB methods and remains under-explored in the community. Previous approaches predominantly employ a custom two-stream design to discover the implicit angular feature within light field cameras, leading to significant information isolation between different LF representations. In this study, we propose an efficient paradigm (LF Tracy) to address this limitation. We eschew the conventional specialized fusion and decoder architecture for a dual-stream backbone in favor of a unified, single-pipeline approach. This comprises firstly a simple yet effective data augmentation strategy called MixLD to bridge the connection of spatial, depth, and implicit angular information under different LF representations. A highly efficient information aggregation (IA) module is then introduced to boost asymmetric feature-wise information fusion. Owing to this innovative approach, our model surpasses the existing state-of-the-art methods, particularly demonstrating a 23% improvement over previous results on the latest large-scale PKU dataset. By utilizing only 28.9M parameters, the model achieves a 10% increase in accuracy with 3M additional parameters compared to its backbone using RGB images and an 86% rise to its backbone using LF images. The source code will be made publicly available at https://github.com/FeiBryantkit/LF-Tracy.
Navigating Open Set Scenarios for Skeleton-based Action Recognition
Dec 11, 2023In real-world scenarios, human actions often fall outside the distribution of training data, making it crucial for models to recognize known actions and reject unknown ones. However, using pure skeleton data in such open-set conditions poses challenges due to the lack of visual background cues and the distinct sparse structure of body pose sequences. In this paper, we tackle the unexplored Open-Set Skeleton-based Action Recognition (OS-SAR) task and formalize the benchmark on three skeleton-based datasets. We assess the performance of seven established open-set approaches on our task and identify their limits and critical generalization issues when dealing with skeleton information. To address these challenges, we propose a distance-based cross-modality ensemble method that leverages the cross-modal alignment of skeleton joints, bones, and velocities to achieve superior open-set recognition performance. We refer to the key idea as CrossMax - an approach that utilizes a novel cross-modality mean max discrepancy suppression mechanism to align latent spaces during training and a cross-modality distance-based logits refinement method during testing. CrossMax outperforms existing approaches and consistently yields state-of-the-art results across all datasets and backbones. The benchmark, code, and models will be released at https://github.com/KPeng9510/OS-SAR.