 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlina Roitberg
Skeleton-Based Human Action Recognition with Noisy Labels
Mar 15, 2024
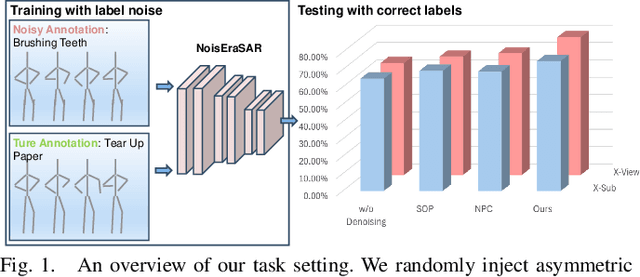
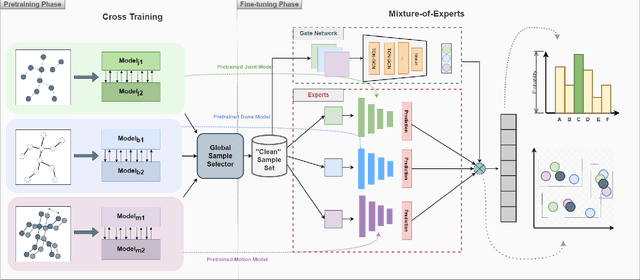
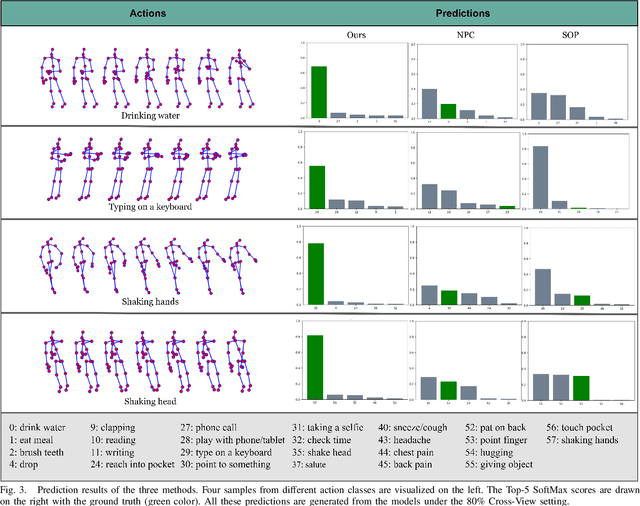
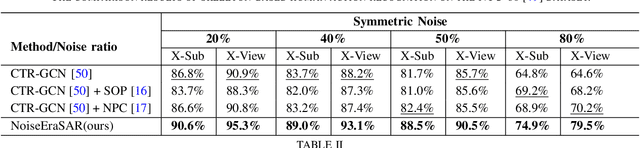
Understanding human actions from body poses is critical for assistive robots sharing space with humans in order to make informed and safe decisions about the next interaction. However, precise temporal localization and annotation of activity sequences is time-consuming and the resulting labels are often noisy. If not effectively addressed, label noise negatively affects the model's training, resulting in lower recognition quality. Despite its importance, addressing label noise for skeleton-based action recognition has been overlooked so far. In this study, we bridge this gap by implementing a framework that augments well-established skeleton-based human action recognition methods with label-denoising strategies from various research areas to serve as the initial benchmark. Observations reveal that these baselines yield only marginal performance when dealing with sparse skeleton data. Consequently, we introduce a novel methodology, NoiseEraSAR, which integrates global sample selection, co-teaching, and Cross-Modal Mixture-of-Experts (CM-MOE) strategies, aimed at mitigating the adverse impacts of label noise. Our proposed approach demonstrates better performance on the established benchmark, setting new state-of-the-art standards. The source code for this study will be made accessible at https://github.com/xuyizdby/NoiseEraSAR.
Navigating Open Set Scenarios for Skeleton-based Action Recognition
Dec 11, 2023In real-world scenarios, human actions often fall outside the distribution of training data, making it crucial for models to recognize known actions and reject unknown ones. However, using pure skeleton data in such open-set conditions poses challenges due to the lack of visual background cues and the distinct sparse structure of body pose sequences. In this paper, we tackle the unexplored Open-Set Skeleton-based Action Recognition (OS-SAR) task and formalize the benchmark on three skeleton-based datasets. We assess the performance of seven established open-set approaches on our task and identify their limits and critical generalization issues when dealing with skeleton information. To address these challenges, we propose a distance-based cross-modality ensemble method that leverages the cross-modal alignment of skeleton joints, bones, and velocities to achieve superior open-set recognition performance. We refer to the key idea as CrossMax - an approach that utilizes a novel cross-modality mean max discrepancy suppression mechanism to align latent spaces during training and a cross-modality distance-based logits refinement method during testing. CrossMax outperforms existing approaches and consistently yields state-of-the-art results across all datasets and backbones. The benchmark, code, and models will be released at https://github.com/KPeng9510/OS-SAR.
Quantized Distillation: Optimizing Driver Activity Recognition Models for Resource-Constrained Environments
Nov 10, 2023Deep learning-based models are at the forefront of most driver observation benchmarks due to their remarkable accuracies but are also associated with high computational costs. This is challenging, as resources are often limited in real-world driving scenarios. This paper introduces a lightweight framework for resource-efficient driver activity recognition. The framework enhances 3D MobileNet, a neural architecture optimized for speed in video classification, by incorporating knowledge distillation and model quantization to balance model accuracy and computational efficiency. Knowledge distillation helps maintain accuracy while reducing the model size by leveraging soft labels from a larger teacher model (I3D), instead of relying solely on original ground truth data. Model quantization significantly lowers memory and computation demands by using lower precision integers for model weights and activations. Extensive testing on a public dataset for in-vehicle monitoring during autonomous driving demonstrates that this new framework achieves a threefold reduction in model size and a 1.4-fold improvement in inference time, compared to an already optimized architecture. The code for this study is available at https://github.com/calvintanama/qd-driver-activity-reco.
Unveiling the Hidden Realm: Self-supervised Skeleton-based Action Recognition in Occluded Environments
Sep 21, 2023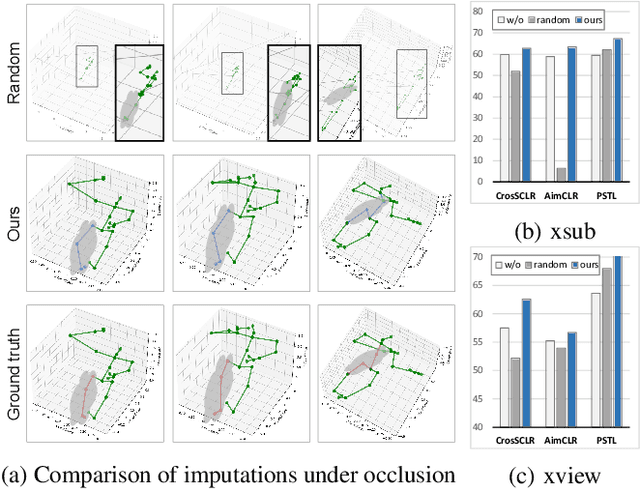

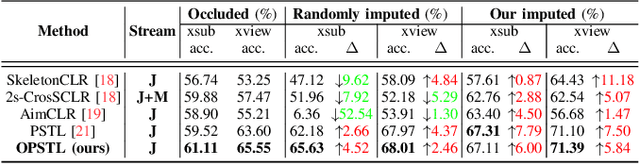

To integrate action recognition methods into autonomous robotic systems, it is crucial to consider adverse situations involving target occlusions. Such a scenario, despite its practical relevance, is rarely addressed in existing self-supervised skeleton-based action recognition methods. To empower robots with the capacity to address occlusion, we propose a simple and effective method. We first pre-train using occluded skeleton sequences, then use k-means clustering (KMeans) on sequence embeddings to group semantically similar samples. Next, we employ K-nearest-neighbor (KNN) to fill in missing skeleton data based on the closest sample neighbors. Imputing incomplete skeleton sequences to create relatively complete sequences as input provides significant benefits to existing skeleton-based self-supervised models. Meanwhile, building on the state-of-the-art Partial Spatio-Temporal Learning (PSTL), we introduce an Occluded Partial Spatio-Temporal Learning (OPSTL) framework. This enhancement utilizes Adaptive Spatial Masking (ASM) for better use of high-quality, intact skeletons. The effectiveness of our imputation methods is verified on the challenging occluded versions of the NTURGB+D 60 and NTURGB+D 120. The source code will be made publicly available at https://github.com/cyfml/OPSTL.
Elevating Skeleton-Based Action Recognition with Efficient Multi-Modality Self-Supervision
Sep 21, 2023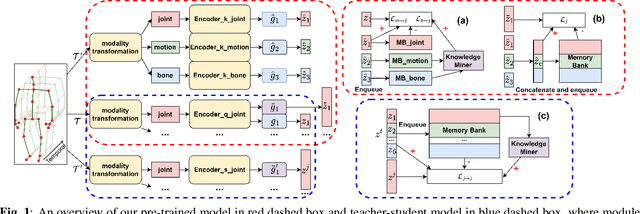

Self-supervised representation learning for human action recognition has developed rapidly in recent years. Most of the existing works are based on skeleton data while using a multi-modality setup. These works overlooked the differences in performance among modalities, which led to the propagation of erroneous knowledge between modalities while only three fundamental modalities, i.e., joints, bones, and motions are used, hence no additional modalities are explored. In this work, we first propose an Implicit Knowledge Exchange Module (IKEM) which alleviates the propagation of erroneous knowledge between low-performance modalities. Then, we further propose three new modalities to enrich the complementary information between modalities. Finally, to maintain efficiency when introducing new modalities, we propose a novel teacher-student framework to distill the knowledge from the secondary modalities into the mandatory modalities considering the relationship constrained by anchors, positives, and negatives, named relational cross-modality knowledge distillation. The experimental results demonstrate the effectiveness of our approach, unlocking the efficient use of skeleton-based multi-modality data. Source code will be made publicly available at https://github.com/desehuileng0o0/IKEM.
On Transferability of Driver Observation Models from Simulated to Real Environments in Autonomous Cars
Jul 31, 2023



For driver observation frameworks, clean datasets collected in controlled simulated environments often serve as the initial training ground. Yet, when deployed under real driving conditions, such simulator-trained models quickly face the problem of distributional shifts brought about by changing illumination, car model, variations in subject appearances, sensor discrepancies, and other environmental alterations. This paper investigates the viability of transferring video-based driver observation models from simulation to real-world scenarios in autonomous vehicles, given the frequent use of simulation data in this domain due to safety issues. To achieve this, we record a dataset featuring actual autonomous driving conditions and involving seven participants engaged in highly distracting secondary activities. To enable direct SIM to REAL transfer, our dataset was designed in accordance with an existing large-scale simulator dataset used as the training source. We utilize the Inflated 3D ConvNet (I3D) model, a popular choice for driver observation, with Gradient-weighted Class Activation Mapping (Grad-CAM) for detailed analysis of model decision-making. Though the simulator-based model clearly surpasses the random baseline, its recognition quality diminishes, with average accuracy dropping from 85.7% to 46.6%. We also observe strong variations across different behavior classes. This underscores the challenges of model transferability, facilitating our research of more robust driver observation systems capable of dealing with real driving conditions.
Line Graphics Digitization: A Step Towards Full Automation
Jul 05, 2023



The digitization of documents allows for wider accessibility and reproducibility. While automatic digitization of document layout and text content has been a long-standing focus of research, this problem in regard to graphical elements, such as statistical plots, has been under-explored. In this paper, we introduce the task of fine-grained visual understanding of mathematical graphics and present the Line Graphics (LG) dataset, which includes pixel-wise annotations of 5 coarse and 10 fine-grained categories. Our dataset covers 520 images of mathematical graphics collected from 450 documents from different disciplines. Our proposed dataset can support two different computer vision tasks, i.e., semantic segmentation and object detection. To benchmark our LG dataset, we explore 7 state-of-the-art models. To foster further research on the digitization of statistical graphs, we will make the dataset, code, and models publicly available to the community.
FeatFSDA: Towards Few-shot Domain Adaptation for Video-based Activity Recognition
May 15, 2023



Domain adaptation is essential for activity recognition, as common spatiotemporal architectures risk overfitting due to increased parameters arising from the temporal dimension. Unsupervised domain adaptation methods have been extensively studied, yet, they require large-scale unlabeled data from the target domain. In this work, we address few-shot domain adaptation for video-based activity recognition (FSDA-AR), which leverages a very small amount of labeled target videos to achieve effective adaptation. This setting is attractive and promising for applications, as it requires recording and labeling only a few, or even a single example per class in the target domain, which often includes activities that are rare yet crucial to recognize. We construct FSDA-AR benchmarks using five established datasets: UCF101, HMDB51, EPIC-KITCHEN, Sims4Action, and Toyota Smart Home. Our results demonstrate that FSDA-AR performs comparably to unsupervised domain adaptation with significantly fewer (yet labeled) target examples. We further propose a novel approach, FeatFSDA, to better leverage the few labeled target domain samples as knowledge guidance. FeatFSDA incorporates a latent space semantic adjacency loss, a domain prototypical similarity loss, and a graph-attentive-network-based edge dropout technique. Our approach achieves state-of-the-art performance on all datasets within our FSDA-AR benchmark. To encourage future research of few-shot domain adaptation for video-based activity recognition, we will release our benchmarks and code at https://github.com/KPeng9510/FeatFSDA.
AdaptiveClick: Clicks-aware Transformer with Adaptive Focal Loss for Interactive Image Segmentation
May 07, 2023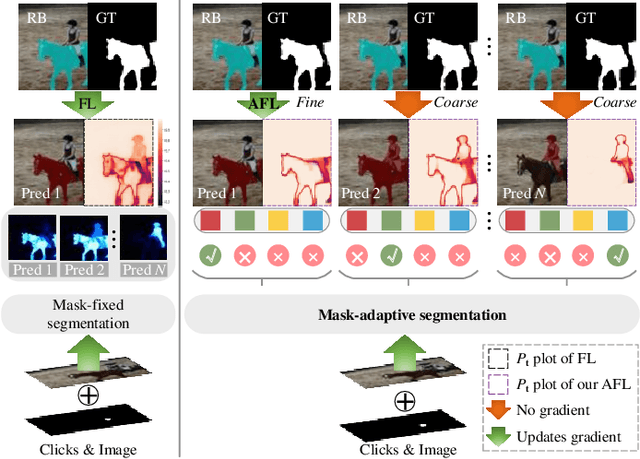
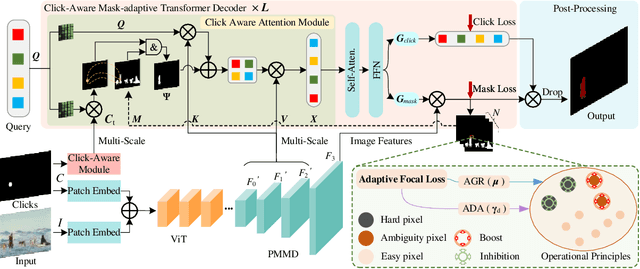

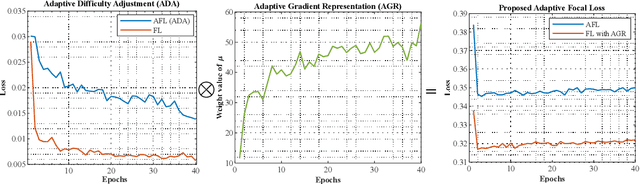
Interactive Image Segmentation (IIS) has emerged as a promising technique for decreasing annotation time. Substantial progress has been made in pre- and post-processing for IIS, but the critical issue of interaction ambiguity notably hindering segmentation quality, has been under-researched. To address this, we introduce AdaptiveClick -- a clicks-aware transformer incorporating an adaptive focal loss, which tackles annotation inconsistencies with tools for mask- and pixel-level ambiguity resolution. To the best of our knowledge, AdaptiveClick is the first transformer-based, mask-adaptive segmentation framework for IIS. The key ingredient of our method is the Clicks-aware Mask-adaptive Transformer Decoder (CAMD), which enhances the interaction between clicks and image features. Additionally, AdaptiveClick enables pixel-adaptive differentiation of hard and easy samples in the decision space, independent of their varying distributions. This is primarily achieved by optimizing a generalized Adaptive Focal Loss (AFL) with a theoretical guarantee, where two adaptive coefficients control the ratio of gradient values for hard and easy pixels. Our analysis reveals that the commonly used Focal and BCE losses can be considered special cases of the proposed AFL loss. With a plain ViT backbone, extensive experimental results on nine datasets demonstrate the superiority of AdaptiveClick compared to state-of-the-art methods. Code will be publicly available at https://github.com/lab206/AdaptiveClick.
FishDreamer: Towards Fisheye Semantic Completion via Unified Image Outpainting and Segmentation
Mar 24, 2023



This paper raises the new task of Fisheye Semantic Completion (FSC), where dense texture, structure, and semantics of a fisheye image are inferred even beyond the sensor field-of-view (FoV). Fisheye cameras have larger FoV than ordinary pinhole cameras, yet its unique special imaging model naturally leads to a blind area at the edge of the image plane. This is suboptimal for safety-critical applications since important perception tasks, such as semantic segmentation, become very challenging within the blind zone. Previous works considered the out-FoV outpainting and in-FoV segmentation separately. However, we observe that these two tasks are actually closely coupled. To jointly estimate the tightly intertwined complete fisheye image and scene semantics, we introduce the new FishDreamer which relies on successful ViTs enhanced with a novel Polar-aware Cross Attention module (PCA) to leverage dense context and guide semantically-consistent content generation while considering different polar distributions. In addition to the contribution of the novel task and architecture, we also derive Cityscapes-BF and KITTI360-BF datasets to facilitate training and evaluation of this new track. Our experiments demonstrate that the proposed FishDreamer outperforms methods solving each task in isolation and surpasses alternative approaches on the Fisheye Semantic Completion. Code and datasets will be available at https://github.com/MasterHow/FishDreamer.