 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhiyong Li
DTCLMapper: Dual Temporal Consistent Learning for Vectorized HD Map Construction
May 09, 2024
Temporal information plays a pivotal role in Bird's-Eye-View (BEV) driving scene understanding, which can alleviate the visual information sparsity. However, the indiscriminate temporal fusion method will cause the barrier of feature redundancy when constructing vectorized High-Definition (HD) maps. In this paper, we revisit the temporal fusion of vectorized HD maps, focusing on temporal instance consistency and temporal map consistency learning. To improve the representation of instances in single-frame maps, we introduce a novel method, DTCLMapper. This approach uses a dual-stream temporal consistency learning module that combines instance embedding with geometry maps. In the instance embedding component, our approach integrates temporal Instance Consistency Learning (ICL), ensuring consistency from vector points and instance features aggregated from points. A vectorized points pre-selection module is employed to enhance the regression efficiency of vector points from each instance. Then aggregated instance features obtained from the vectorized points preselection module are grounded in contrastive learning to realize temporal consistency, where positive and negative samples are selected based on position and semantic information. The geometry mapping component introduces Map Consistency Learning (MCL) designed with self-supervised learning. The MCL enhances the generalization capability of our consistent learning approach by concentrating on the global location and distribution constraints of the instances. Extensive experiments on well-recognized benchmarks indicate that the proposed DTCLMapper achieves state-of-the-art performance in vectorized mapping tasks, reaching 61.9% and 65.1% mAP scores on the nuScenes and Argoverse datasets, respectively. The source code will be made publicly available at https://github.com/lynn-yu/DTCLMapper.
MambaMOS: LiDAR-based 3D Moving Object Segmentation with Motion-aware State Space Model
Apr 19, 2024LiDAR-based Moving Object Segmentation (MOS) aims to locate and segment moving objects in point clouds of the current scan using motion information from previous scans. Despite the promising results achieved by previous MOS methods, several key issues, such as the weak coupling of temporal and spatial information, still need further study. In this paper, we propose a novel LiDAR-based 3D Moving Object Segmentation with Motion-aware State Space Model, termed MambaMOS. Firstly, we develop a novel embedding module, the Time Clue Bootstrapping Embedding (TCBE), to enhance the coupling of temporal and spatial information in point clouds and alleviate the issue of overlooked temporal clues. Secondly, we introduce the Motion-aware State Space Model (MSSM) to endow the model with the capacity to understand the temporal correlations of the same object across different time steps. Specifically, MSSM emphasizes the motion states of the same object at different time steps through two distinct temporal modeling and correlation steps. We utilize an improved state space model to represent these motion differences, significantly modeling the motion states. Finally, extensive experiments on the SemanticKITTI-MOS and KITTI-Road benchmarks demonstrate that the proposed MambaMOS achieves state-of-the-art performance. The source code of this work will be made publicly available at https://github.com/Terminal-K/MambaMOS.
EchoTrack: Auditory Referring Multi-Object Tracking for Autonomous Driving
Feb 28, 2024This paper introduces the task of Auditory Referring Multi-Object Tracking (AR-MOT), which dynamically tracks specific objects in a video sequence based on audio expressions and appears as a challenging problem in autonomous driving. Due to the lack of semantic modeling capacity in audio and video, existing works have mainly focused on text-based multi-object tracking, which often comes at the cost of tracking quality, interaction efficiency, and even the safety of assistance systems, limiting the application of such methods in autonomous driving. In this paper, we delve into the problem of AR-MOT from the perspective of audio-video fusion and audio-video tracking. We put forward EchoTrack, an end-to-end AR-MOT framework with dual-stream vision transformers. The dual streams are intertwined with our Bidirectional Frequency-domain Cross-attention Fusion Module (Bi-FCFM), which bidirectionally fuses audio and video features from both frequency- and spatiotemporal domains. Moreover, we propose the Audio-visual Contrastive Tracking Learning (ACTL) regime to extract homogeneous semantic features between expressions and visual objects by learning homogeneous features between different audio and video objects effectively. Aside from the architectural design, we establish the first set of large-scale AR-MOT benchmarks, including Echo-KITTI, Echo-KITTI+, and Echo-BDD. Extensive experiments on the established benchmarks demonstrate the effectiveness of the proposed EchoTrack model and its components. The source code and datasets will be made publicly available at https://github.com/lab206/EchoTrack.
LF Tracy: A Unified Single-Pipeline Approach for Salient Object Detection in Light Field Cameras
Jan 30, 2024Leveraging the rich information extracted from light field (LF) cameras is instrumental for dense prediction tasks. However, adapting light field data to enhance Salient Object Detection (SOD) still follows the traditional RGB methods and remains under-explored in the community. Previous approaches predominantly employ a custom two-stream design to discover the implicit angular feature within light field cameras, leading to significant information isolation between different LF representations. In this study, we propose an efficient paradigm (LF Tracy) to address this limitation. We eschew the conventional specialized fusion and decoder architecture for a dual-stream backbone in favor of a unified, single-pipeline approach. This comprises firstly a simple yet effective data augmentation strategy called MixLD to bridge the connection of spatial, depth, and implicit angular information under different LF representations. A highly efficient information aggregation (IA) module is then introduced to boost asymmetric feature-wise information fusion. Owing to this innovative approach, our model surpasses the existing state-of-the-art methods, particularly demonstrating a 23% improvement over previous results on the latest large-scale PKU dataset. By utilizing only 28.9M parameters, the model achieves a 10% increase in accuracy with 3M additional parameters compared to its backbone using RGB images and an 86% rise to its backbone using LF images. The source code will be made publicly available at https://github.com/FeiBryantkit/LF-Tracy.
OriWheelBot: An origami-wheeled robot
Sep 29, 2023Origami-inspired robots with multiple advantages, such as being lightweight, requiring less assembly, and exhibiting exceptional deformability, have received substantial and sustained attention. However, the existing origami-inspired robots are usually of limited functionalities and developing feature-rich robots is very challenging. Here, we report an origami-wheeled robot (OriWheelBot) with variable width and outstanding sand walking versatility. The OriWheelBot's ability to adjust wheel width over obstacles is achieved by origami wheels made of Miura origami. An improved version, called iOriWheelBot, is also developed to automatically judge the width of the obstacles. Three actions, namely direct pass, variable width pass, and direct return, will be carried out depending on the width of the channel between the obstacles. We have identified two motion mechanisms, i.e., sand-digging and sand-pushing, with the latter being more conducive to walking on the sand. We have systematically examined numerous sand walking characteristics, including carrying loads, climbing a slope, walking on a slope, and navigating sand pits, small rocks, and sand traps. The OriWheelBot can change its width by 40%, has a loading-carrying ratio of 66.7% on flat sand and can climb a 17-degree sand incline. The OriWheelBot can be useful for planetary subsurface exploration and disaster area rescue.
S$^3$-MonoDETR: Supervised Shape&Scale-perceptive Deformable Transformer for Monocular 3D Object Detection
Sep 02, 2023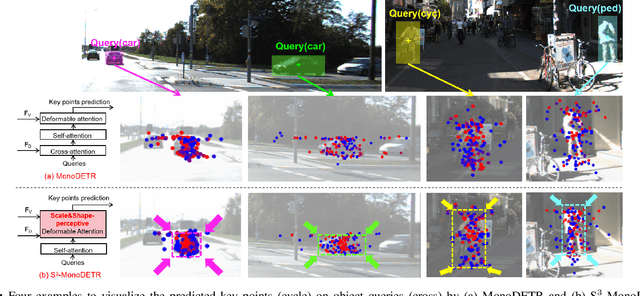
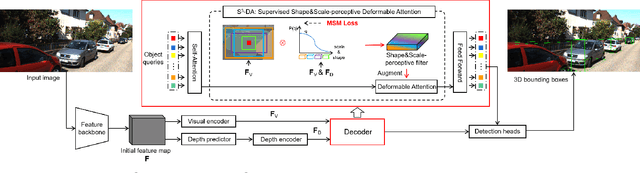
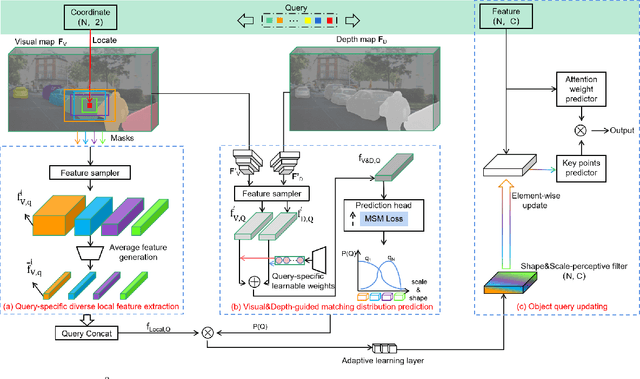
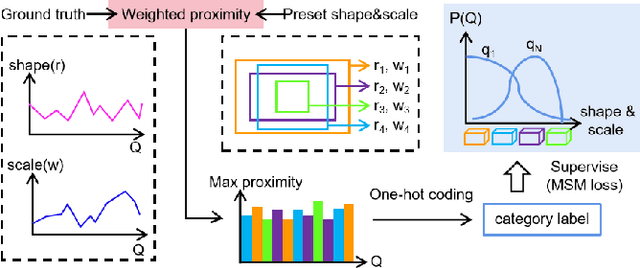
Recently, transformer-based methods have shown exceptional performance in monocular 3D object detection, which can predict 3D attributes from a single 2D image. These methods typically use visual and depth representations to generate query points on objects, whose quality plays a decisive role in the detection accuracy. However, current unsupervised attention mechanisms without any geometry appearance awareness in transformers are susceptible to producing noisy features for query points, which severely limits the network performance and also makes the model have a poor ability to detect multi-category objects in a single training process. To tackle this problem, this paper proposes a novel "Supervised Shape&Scale-perceptive Deformable Attention" (S$^3$-DA) module for monocular 3D object detection. Concretely, S$^3$-DA utilizes visual and depth features to generate diverse local features with various shapes and scales and predict the corresponding matching distribution simultaneously to impose valuable shape&scale perception for each query. Benefiting from this, S$^3$-DA effectively estimates receptive fields for query points belonging to any category, enabling them to generate robust query features. Besides, we propose a Multi-classification-based Shape$\&$Scale Matching (MSM) loss to supervise the above process. Extensive experiments on KITTI and Waymo Open datasets demonstrate that S$^3$-DA significantly improves the detection accuracy, yielding state-of-the-art performance of single-category and multi-category 3D object detection in a single training process compared to the existing approaches. The source code will be made publicly available at https://github.com/mikasa3lili/S3-MonoDETR.
EPCFormer: Expression Prompt Collaboration Transformer for Universal Referring Video Object Segmentation
Aug 08, 2023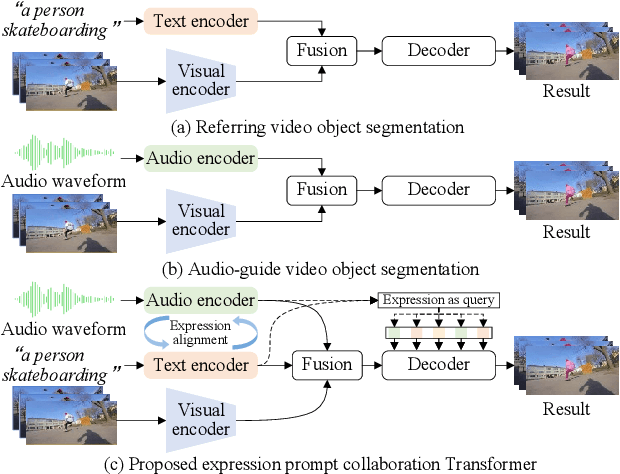
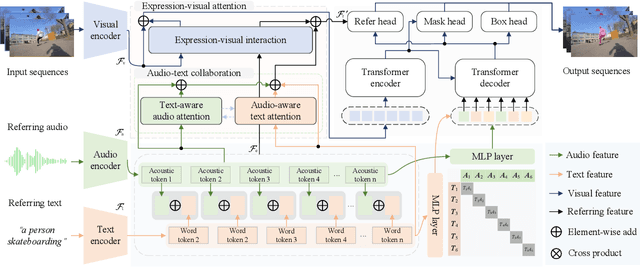
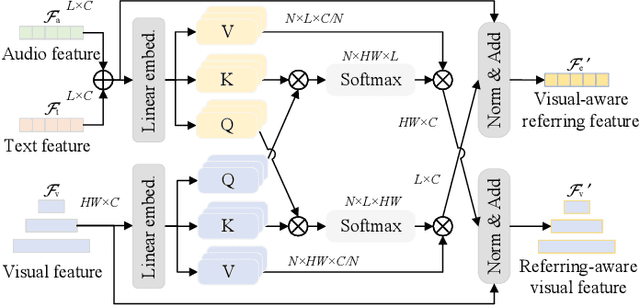
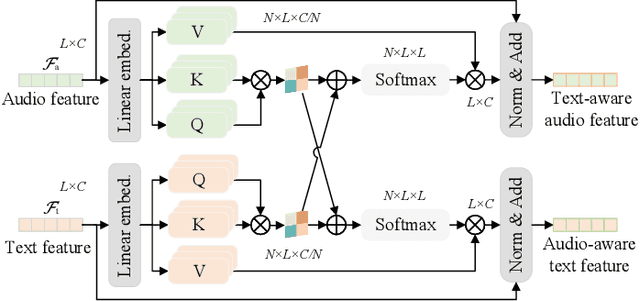
Audio-guided Video Object Segmentation (A-VOS) and Referring Video Object Segmentation (R-VOS) are two highly-related tasks, which both aim to segment specific objects from video sequences according to user-provided expression prompts. However, due to the challenges in modeling representations for different modalities, contemporary methods struggle to strike a balance between interaction flexibility and high-precision localization and segmentation. In this paper, we address this problem from two perspectives: the alignment representation of audio and text and the deep interaction among audio, text, and visual features. First, we propose a universal architecture, the Expression Prompt Collaboration Transformer, herein EPCFormer. Next, we propose an Expression Alignment (EA) mechanism for audio and text expressions. By introducing contrastive learning for audio and text expressions, the proposed EPCFormer realizes comprehension of the semantic equivalence between audio and text expressions denoting the same objects. Then, to facilitate deep interactions among audio, text, and video features, we introduce an Expression-Visual Attention (EVA) mechanism. The knowledge of video object segmentation in terms of the expression prompts can seamlessly transfer between the two tasks by deeply exploring complementary cues between text and audio. Experiments on well-recognized benchmarks demonstrate that our universal EPCFormer attains state-of-the-art results on both tasks. The source code of EPCFormer will be made publicly available at https://github.com/lab206/EPCFormer.
Contrast-augmented Diffusion Model with Fine-grained Sequence Alignment for Markup-to-Image Generation
Aug 02, 2023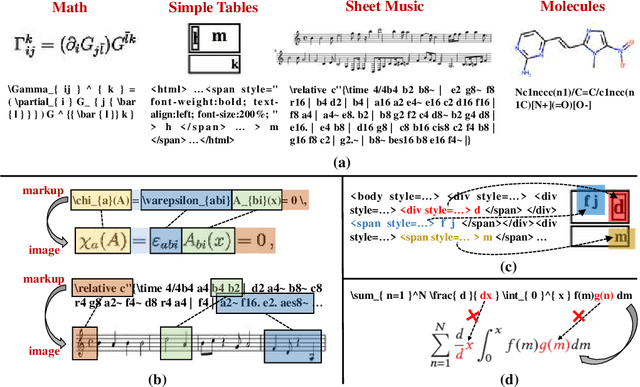
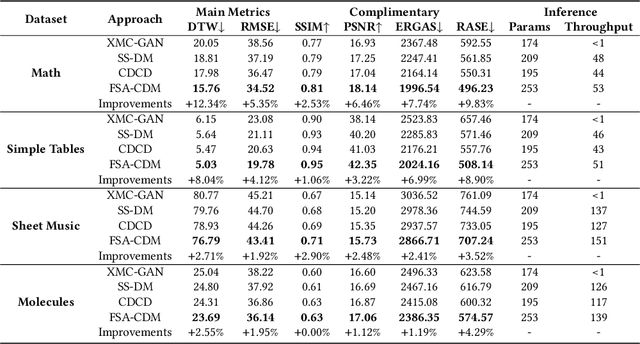
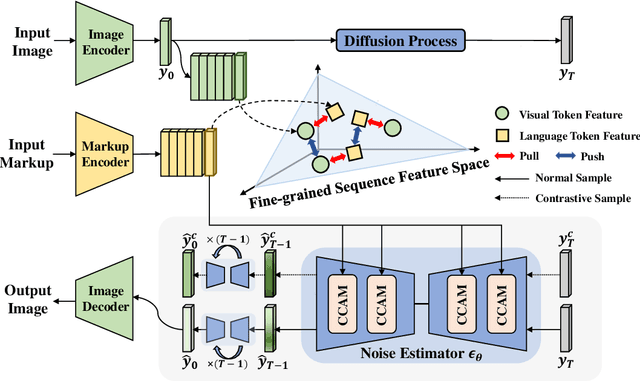
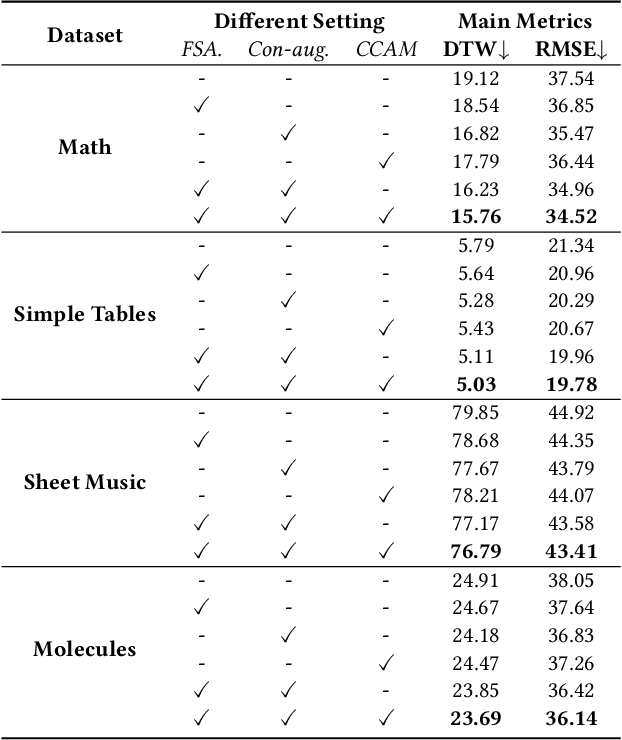
The recently rising markup-to-image generation poses greater challenges as compared to natural image generation, due to its low tolerance for errors as well as the complex sequence and context correlations between markup and rendered image. This paper proposes a novel model named "Contrast-augmented Diffusion Model with Fine-grained Sequence Alignment" (FSA-CDM), which introduces contrastive positive/negative samples into the diffusion model to boost performance for markup-to-image generation. Technically, we design a fine-grained cross-modal alignment module to well explore the sequence similarity between the two modalities for learning robust feature representations. To improve the generalization ability, we propose a contrast-augmented diffusion model to explicitly explore positive and negative samples by maximizing a novel contrastive variational objective, which is mathematically inferred to provide a tighter bound for the model's optimization. Moreover, the context-aware cross attention module is developed to capture the contextual information within markup language during the denoising process, yielding better noise prediction results. Extensive experiments are conducted on four benchmark datasets from different domains, and the experimental results demonstrate the effectiveness of the proposed components in FSA-CDM, significantly exceeding state-of-the-art performance by about 2%-12% DTW improvements. The code will be released at https://github.com/zgj77/FSACDM.
VPUFormer: Visual Prompt Unified Transformer for Interactive Image Segmentation
Jun 11, 2023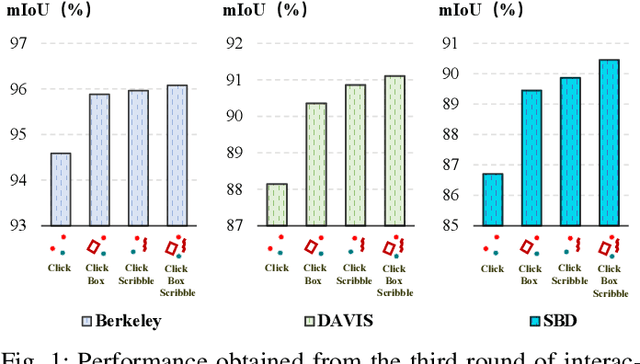
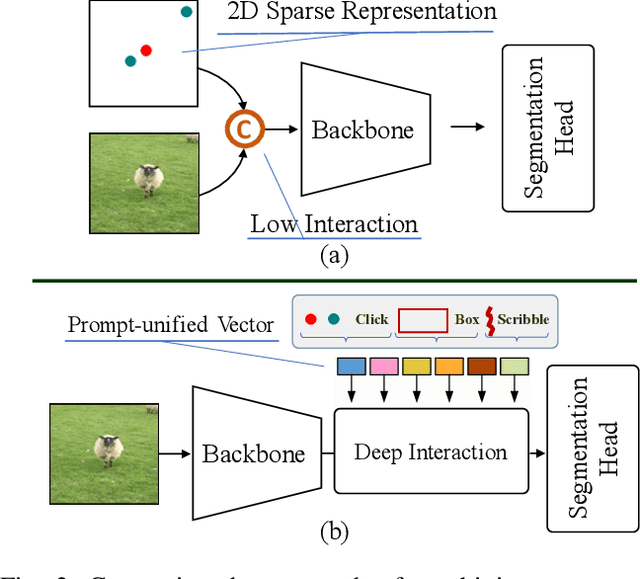
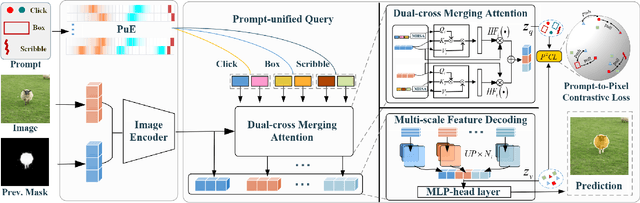
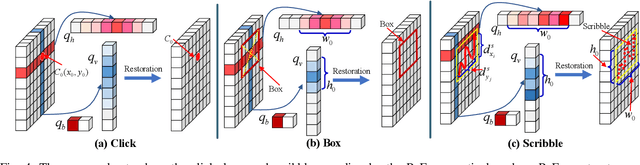
The integration of diverse visual prompts like clicks, scribbles, and boxes in interactive image segmentation could significantly facilitate user interaction as well as improve interaction efficiency. Most existing studies focus on a single type of visual prompt by simply concatenating prompts and images as input for segmentation prediction, which suffers from low-efficiency prompt representation and weak interaction issues. This paper proposes a simple yet effective Visual Prompt Unified Transformer (VPUFormer), which introduces a concise unified prompt representation with deeper interaction to boost the segmentation performance. Specifically, we design a Prompt-unified Encoder (PuE) by using Gaussian mapping to generate a unified one-dimensional vector for click, box, and scribble prompts, which well captures users' intentions as well as provides a denser representation of user prompts. In addition, we present a Prompt-to-Pixel Contrastive Loss (P2CL) that leverages user feedback to gradually refine candidate semantic features, aiming to bring image semantic features closer to the features that are similar to the user prompt, while pushing away those image semantic features that are dissimilar to the user prompt, thereby correcting results that deviate from expectations. On this basis, our approach injects prompt representations as queries into Dual-cross Merging Attention (DMA) blocks to perform a deeper interaction between image and query inputs. A comprehensive variety of experiments on seven challenging datasets demonstrates that the proposed VPUFormer with PuE, DMA, and P2CL achieves consistent improvements, yielding state-of-the-art segmentation performance. Our code will be made publicly available at https://github.com/XuZhang1211/VPUFormer.
SSD-MonoDTR: Supervised Scale-constrained Deformable Transformer for Monocular 3D Object Detection
May 12, 2023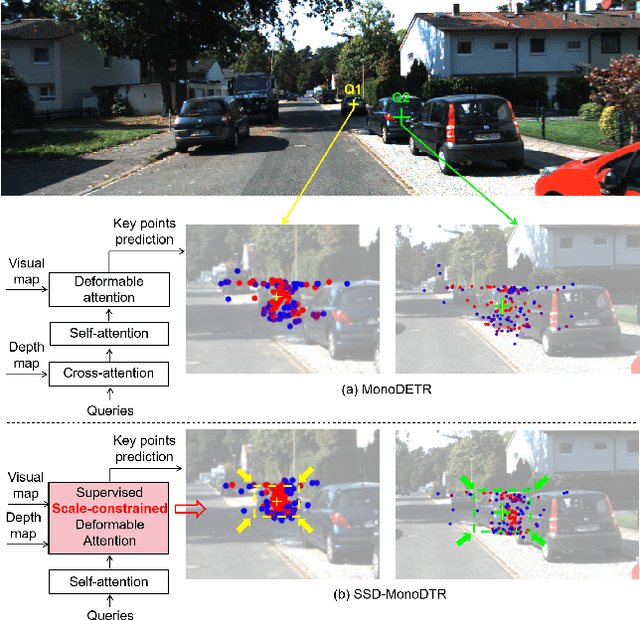
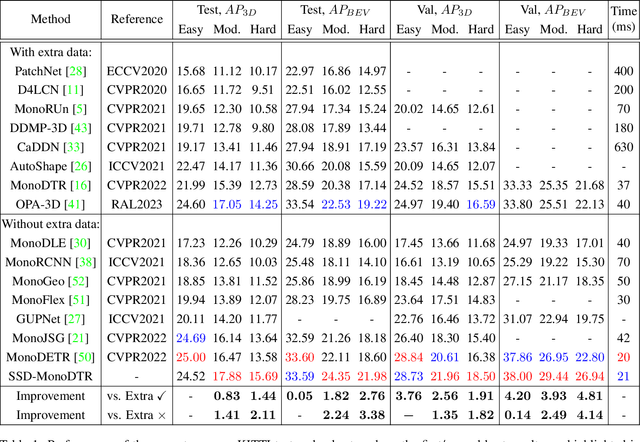
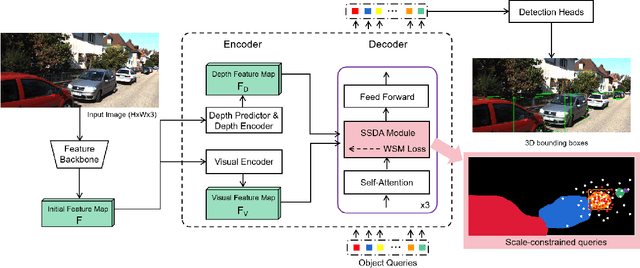
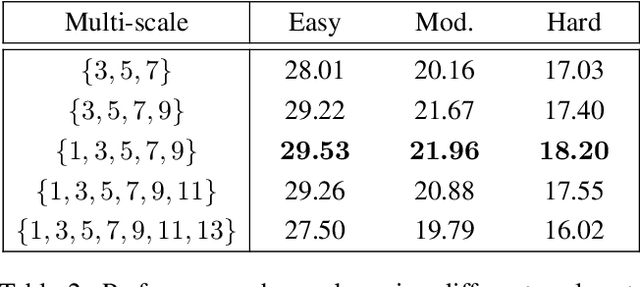
Transformer-based methods have demonstrated superior performance for monocular 3D object detection recently, which predicts 3D attributes from a single 2D image. Most existing transformer-based methods leverage visual and depth representations to explore valuable query points on objects, and the quality of the learned queries has a great impact on detection accuracy. Unfortunately, existing unsupervised attention mechanisms in transformer are prone to generate low-quality query features due to inaccurate receptive fields, especially on hard objects. To tackle this problem, this paper proposes a novel ``Supervised Scale-constrained Deformable Attention'' (SSDA) for monocular 3D object detection. Specifically, SSDA presets several masks with different scales and utilizes depth and visual features to predict the local feature for each query. Imposing the scale constraint, SSDA could well predict the accurate receptive field of a query to support robust query feature generation. What is more, SSDA is assigned with a Weighted Scale Matching (WSM) loss to supervise scale prediction, which presents more confident results as compared to the unsupervised attention mechanisms. Extensive experiments on ``KITTI'' demonstrate that SSDA significantly improves the detection accuracy especially on moderate and hard objects, yielding SOTA performance as compared to the existing approaches. Code will be publicly available at https://github.com/mikasa3lili/SSD-MonoDETR.