 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDi Wen
Skeleton-Based Human Action Recognition with Noisy Labels
Mar 15, 2024
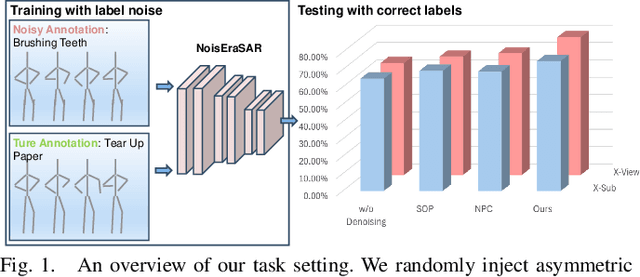
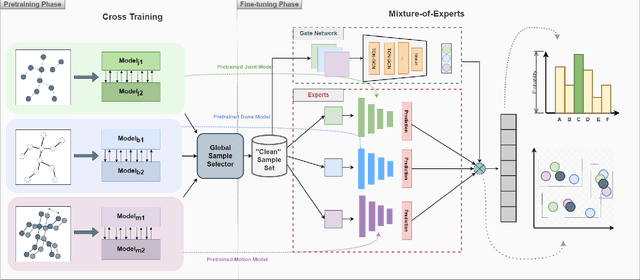
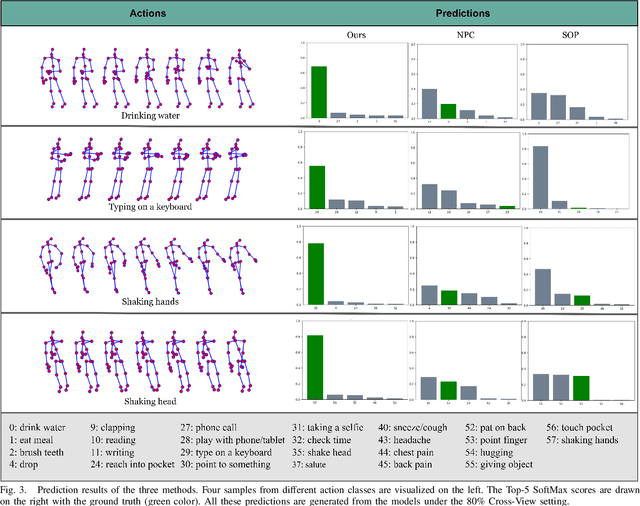
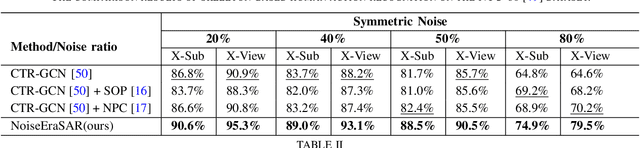
Understanding human actions from body poses is critical for assistive robots sharing space with humans in order to make informed and safe decisions about the next interaction. However, precise temporal localization and annotation of activity sequences is time-consuming and the resulting labels are often noisy. If not effectively addressed, label noise negatively affects the model's training, resulting in lower recognition quality. Despite its importance, addressing label noise for skeleton-based action recognition has been overlooked so far. In this study, we bridge this gap by implementing a framework that augments well-established skeleton-based human action recognition methods with label-denoising strategies from various research areas to serve as the initial benchmark. Observations reveal that these baselines yield only marginal performance when dealing with sparse skeleton data. Consequently, we introduce a novel methodology, NoiseEraSAR, which integrates global sample selection, co-teaching, and Cross-Modal Mixture-of-Experts (CM-MOE) strategies, aimed at mitigating the adverse impacts of label noise. Our proposed approach demonstrates better performance on the established benchmark, setting new state-of-the-art standards. The source code for this study will be made accessible at https://github.com/xuyizdby/NoiseEraSAR.
FeatFSDA: Towards Few-shot Domain Adaptation for Video-based Activity Recognition
May 15, 2023



Domain adaptation is essential for activity recognition, as common spatiotemporal architectures risk overfitting due to increased parameters arising from the temporal dimension. Unsupervised domain adaptation methods have been extensively studied, yet, they require large-scale unlabeled data from the target domain. In this work, we address few-shot domain adaptation for video-based activity recognition (FSDA-AR), which leverages a very small amount of labeled target videos to achieve effective adaptation. This setting is attractive and promising for applications, as it requires recording and labeling only a few, or even a single example per class in the target domain, which often includes activities that are rare yet crucial to recognize. We construct FSDA-AR benchmarks using five established datasets: UCF101, HMDB51, EPIC-KITCHEN, Sims4Action, and Toyota Smart Home. Our results demonstrate that FSDA-AR performs comparably to unsupervised domain adaptation with significantly fewer (yet labeled) target examples. We further propose a novel approach, FeatFSDA, to better leverage the few labeled target domain samples as knowledge guidance. FeatFSDA incorporates a latent space semantic adjacency loss, a domain prototypical similarity loss, and a graph-attentive-network-based edge dropout technique. Our approach achieves state-of-the-art performance on all datasets within our FSDA-AR benchmark. To encourage future research of few-shot domain adaptation for video-based activity recognition, we will release our benchmarks and code at https://github.com/KPeng9510/FeatFSDA.
Smoothed Gaussian Mixture Models for Video Classification and Recommendation
Dec 17, 2020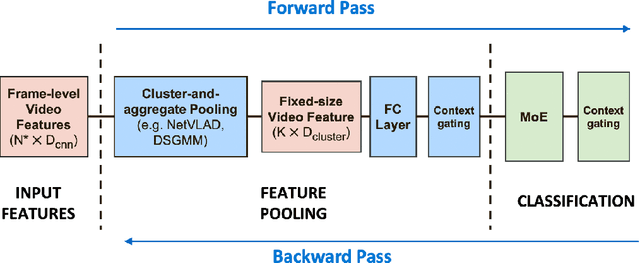



Cluster-and-aggregate techniques such as Vector of Locally Aggregated Descriptors (VLAD), and their end-to-end discriminatively trained equivalents like NetVLAD have recently been popular for video classification and action recognition tasks. These techniques operate by assigning video frames to clusters and then representing the video by aggregating residuals of frames with respect to the mean of each cluster. Since some clusters may see very little video-specific data, these features can be noisy. In this paper, we propose a new cluster-and-aggregate method which we call smoothed Gaussian mixture model (SGMM), and its end-to-end discriminatively trained equivalent, which we call deep smoothed Gaussian mixture model (DSGMM). SGMM represents each video by the parameters of a Gaussian mixture model (GMM) trained for that video. Low-count clusters are addressed by smoothing the video-specific estimates with a universal background model (UBM) trained on a large number of videos. The primary benefit of SGMM over VLAD is smoothing which makes it less sensitive to small number of training samples. We show, through extensive experiments on the YouTube-8M classification task, that SGMM/DSGMM is consistently better than VLAD/NetVLAD by a small but statistically significant margin. We also show results using a dataset created at LinkedIn to predict if a member will watch an uploaded video.