 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKarsten Roth
kNN-CLIP: Retrieval Enables Training-Free Segmentation on Continually Expanding Large Vocabularies
Apr 15, 2024
Rapid advancements in continual segmentation have yet to bridge the gap of scaling to large continually expanding vocabularies under compute-constrained scenarios. We discover that traditional continual training leads to catastrophic forgetting under compute constraints, unable to outperform zero-shot segmentation methods. We introduce a novel strategy for semantic and panoptic segmentation with zero forgetting, capable of adapting to continually growing vocabularies without the need for retraining or large memory costs. Our training-free approach, kNN-CLIP, leverages a database of instance embeddings to enable open-vocabulary segmentation approaches to continually expand their vocabulary on any given domain with a single-pass through data, while only storing embeddings minimizing both compute and memory costs. This method achieves state-of-the-art mIoU performance across large-vocabulary semantic and panoptic segmentation datasets. We hope kNN-CLIP represents a step forward in enabling more efficient and adaptable continual segmentation, paving the way for advances in real-world large-vocabulary continual segmentation methods.
Fantastic Gains and Where to Find Them: On the Existence and Prospect of General Knowledge Transfer between Any Pretrained Model
Oct 26, 2023Training deep networks requires various design decisions regarding for instance their architecture, data augmentation, or optimization. In this work, we find these training variations to result in networks learning unique feature sets from the data. Using public model libraries comprising thousands of models trained on canonical datasets like ImageNet, we observe that for arbitrary pairings of pretrained models, one model extracts significant data context unavailable in the other -- independent of overall performance. Given any arbitrary pairing of pretrained models and no external rankings (such as separate test sets, e.g. due to data privacy), we investigate if it is possible to transfer such "complementary" knowledge from one model to another without performance degradation -- a task made particularly difficult as additional knowledge can be contained in stronger, equiperformant or weaker models. Yet facilitating robust transfer in scenarios agnostic to pretrained model pairings would unlock auxiliary gains and knowledge fusion from any model repository without restrictions on model and problem specifics - including from weaker, lower-performance models. This work therefore provides an initial, in-depth exploration on the viability of such general-purpose knowledge transfer. Across large-scale experiments, we first reveal the shortcomings of standard knowledge distillation techniques, and then propose a much more general extension through data partitioning for successful transfer between nearly all pretrained models, which we show can also be done unsupervised. Finally, we assess both the scalability and impact of fundamental model properties on successful model-agnostic knowledge transfer.
Vision-by-Language for Training-Free Compositional Image Retrieval
Oct 13, 2023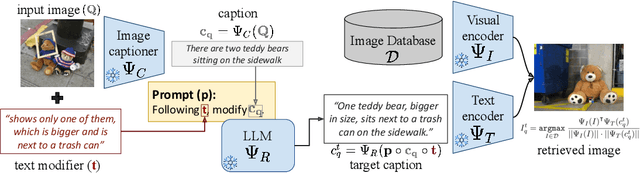
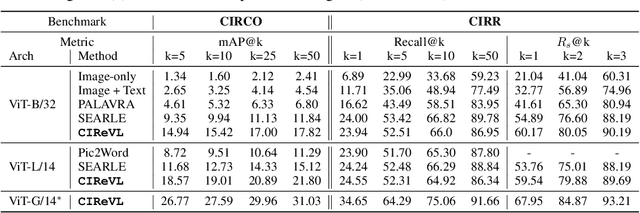
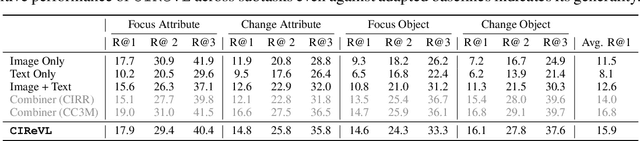
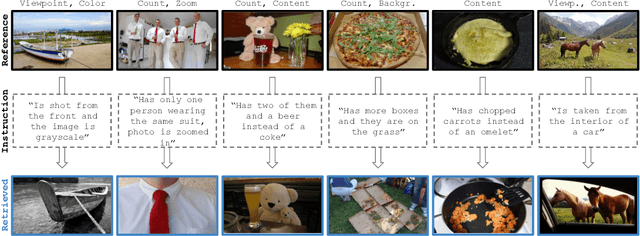
Given an image and a target modification (e.g an image of the Eiffel tower and the text "without people and at night-time"), Compositional Image Retrieval (CIR) aims to retrieve the relevant target image in a database. While supervised approaches rely on annotating triplets that is costly (i.e. query image, textual modification, and target image), recent research sidesteps this need by using large-scale vision-language models (VLMs), performing Zero-Shot CIR (ZS-CIR). However, state-of-the-art approaches in ZS-CIR still require training task-specific, customized models over large amounts of image-text pairs. In this work, we propose to tackle CIR in a training-free manner via our Compositional Image Retrieval through Vision-by-Language (CIReVL), a simple, yet human-understandable and scalable pipeline that effectively recombines large-scale VLMs with large language models (LLMs). By captioning the reference image using a pre-trained generative VLM and asking a LLM to recompose the caption based on the textual target modification for subsequent retrieval via e.g. CLIP, we achieve modular language reasoning. In four ZS-CIR benchmarks, we find competitive, in-part state-of-the-art performance - improving over supervised methods. Moreover, the modularity of CIReVL offers simple scalability without re-training, allowing us to both investigate scaling laws and bottlenecks for ZS-CIR while easily scaling up to in parts more than double of previously reported results. Finally, we show that CIReVL makes CIR human-understandable by composing image and text in a modular fashion in the language domain, thereby making it intervenable, allowing to post-hoc re-align failure cases. Code will be released upon acceptance.
Waffling around for Performance: Visual Classification with Random Words and Broad Concepts
Jun 12, 2023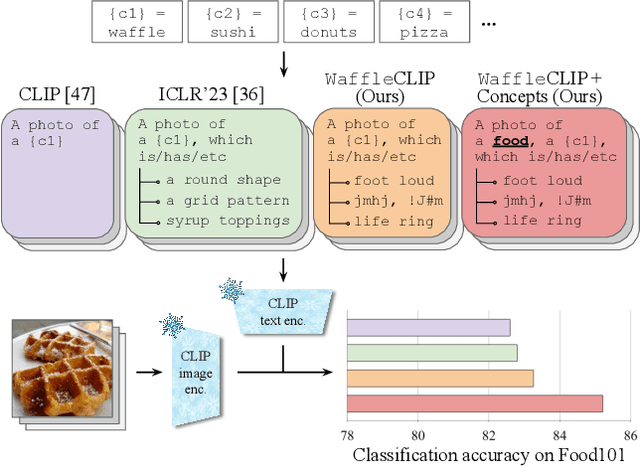

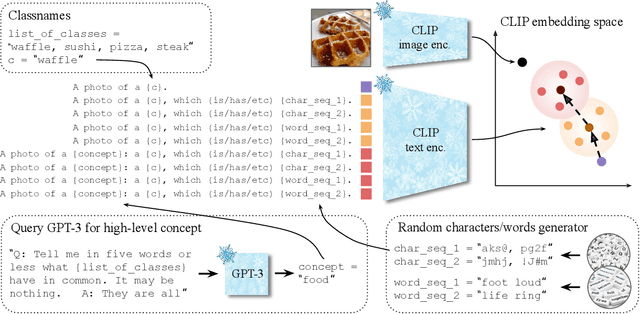

The visual classification performance of vision-language models such as CLIP can benefit from additional semantic knowledge, e.g. via large language models (LLMs) such as GPT-3. Further extending classnames with LLM-generated class descriptors, e.g. ``waffle, \textit{which has a round shape}'', or averaging retrieval scores over multiple such descriptors, has been shown to improve generalization performance. In this work, we study this behavior in detail and propose \texttt{Waffle}CLIP, a framework for zero-shot visual classification which achieves similar performance gains on a large number of visual classification tasks by simply replacing LLM-generated descriptors with random character and word descriptors \textbf{without} querying external models. We extend these results with an extensive experimental study on the impact and shortcomings of additional semantics introduced via LLM-generated descriptors, and showcase how semantic context is better leveraged by automatically querying LLMs for high-level concepts, while jointly resolving potential class name ambiguities. Link to the codebase: https://github.com/ExplainableML/WaffleCLIP.
If at First You Don't Succeed, Try, Try Again: Faithful Diffusion-based Text-to-Image Generation by Selection
May 22, 2023

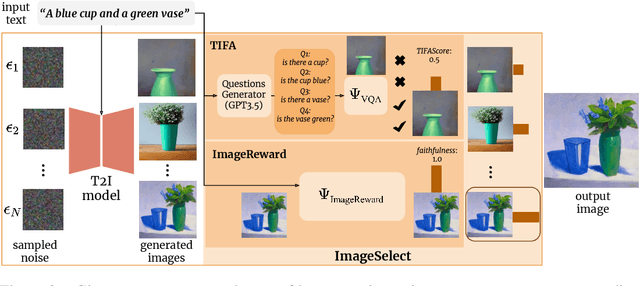
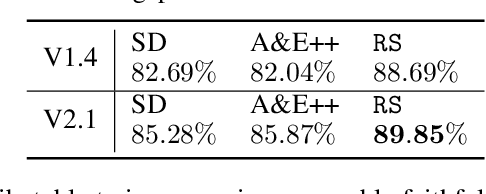
Despite their impressive capabilities, diffusion-based text-to-image (T2I) models can lack faithfulness to the text prompt, where generated images may not contain all the mentioned objects, attributes or relations. To alleviate these issues, recent works proposed post-hoc methods to improve model faithfulness without costly retraining, by modifying how the model utilizes the input prompt. In this work, we take a step back and show that large T2I diffusion models are more faithful than usually assumed, and can generate images faithful to even complex prompts without the need to manipulate the generative process. Based on that, we show how faithfulness can be simply treated as a candidate selection problem instead, and introduce a straightforward pipeline that generates candidate images for a text prompt and picks the best one according to an automatic scoring system that can leverage already existing T2I evaluation metrics. Quantitative comparisons alongside user studies on diverse benchmarks show consistently improved faithfulness over post-hoc enhancement methods, with comparable or lower computational cost. Code is available at \url{https://github.com/ExplainableML/ImageSelect}.
Momentum-based Weight Interpolation of Strong Zero-Shot Models for Continual Learning
Nov 06, 2022
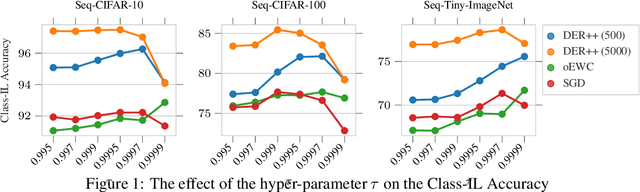
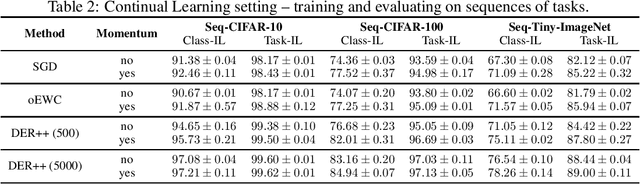
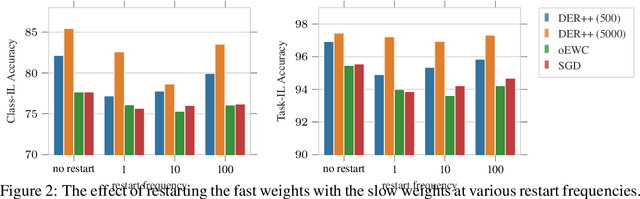
Large pre-trained, zero-shot capable models have shown considerable success both for standard transfer and adaptation tasks, with particular robustness towards distribution shifts. In addition, subsequent fine-tuning can considerably improve performance on a selected downstream task. However, through naive fine-tuning, these zero-shot models lose their generalizability and robustness towards distribution shifts. This is a particular problem for tasks such as Continual Learning (CL), where continuous adaptation has to be performed as new task distributions are introduced sequentially. In this work, we showcase that where fine-tuning falls short to adapt such zero-shot capable models, simple momentum-based weight interpolation can provide consistent improvements for CL tasks in both memory-free and memory-based settings. In particular, we find improvements of over $+4\%$ on standard CL benchmarks, while reducing the error to the upper limit of jointly training on all tasks at once in parts by more than half, allowing the continual learner to inch closer to the joint training limits.
Disentanglement of Correlated Factors via Hausdorff Factorized Support
Oct 13, 2022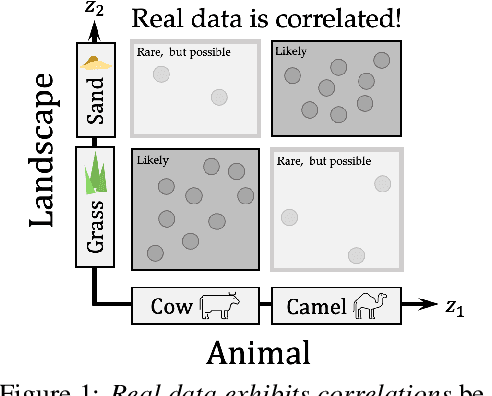
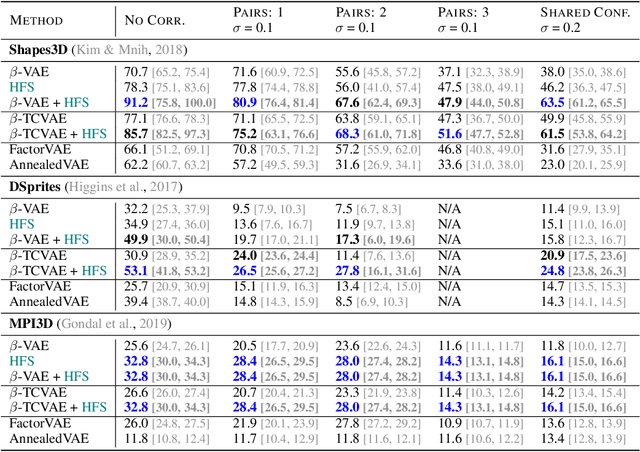
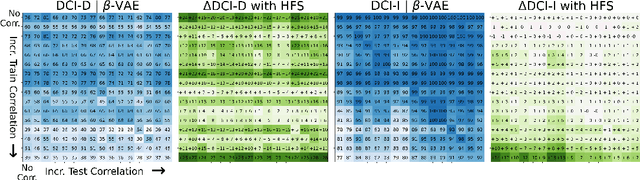
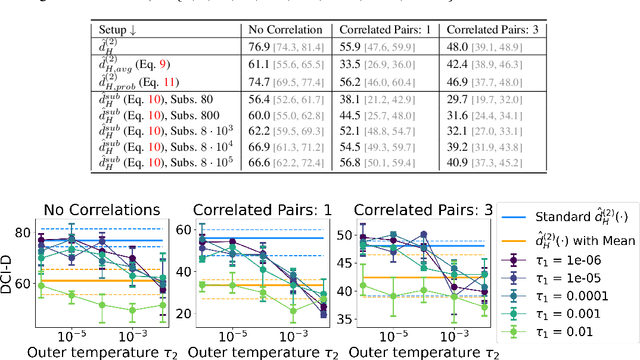
A grand goal in deep learning research is to learn representations capable of generalizing across distribution shifts. Disentanglement is one promising direction aimed at aligning a models representations with the underlying factors generating the data (e.g. color or background). Existing disentanglement methods, however, rely on an often unrealistic assumption: that factors are statistically independent. In reality, factors (like object color and shape) are correlated. To address this limitation, we propose a relaxed disentanglement criterion - the Hausdorff Factorized Support (HFS) criterion - that encourages a factorized support, rather than a factorial distribution, by minimizing a Hausdorff distance. This allows for arbitrary distributions of the factors over their support, including correlations between them. We show that the use of HFS consistently facilitates disentanglement and recovery of ground-truth factors across a variety of correlation settings and benchmarks, even under severe training correlations and correlation shifts, with in parts over +60% in relative improvement over existing disentanglement methods. In addition, we find that leveraging HFS for representation learning can even facilitate transfer to downstream tasks such as classification under distribution shifts. We hope our original approach and positive empirical results inspire further progress on the open problem of robust generalization.
A Non-isotropic Probabilistic Take on Proxy-based Deep Metric Learning
Jul 08, 2022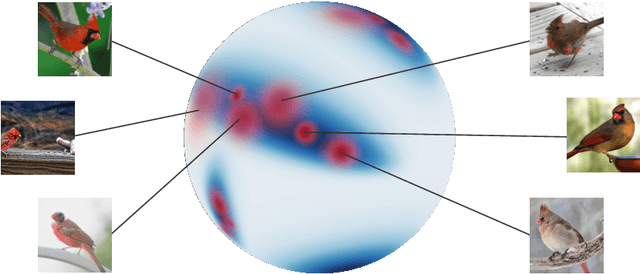
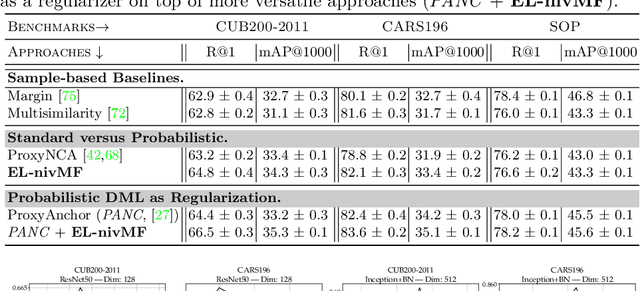
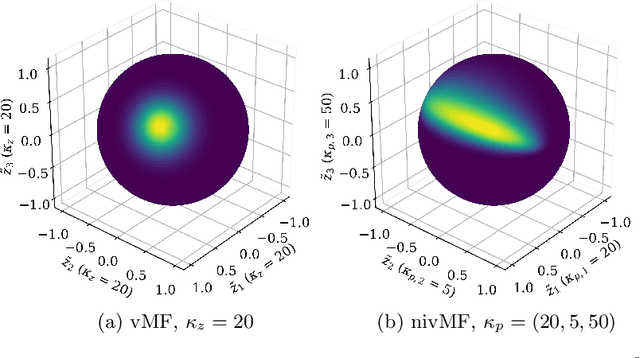
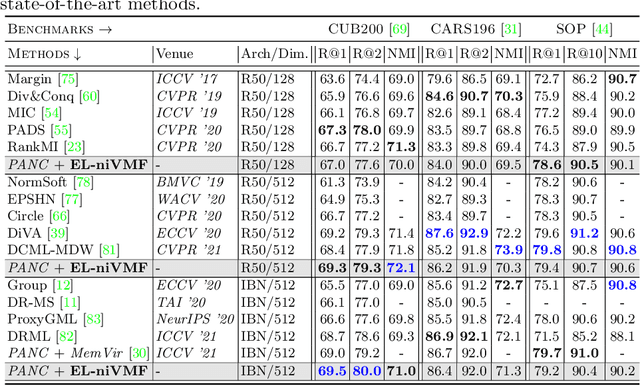
Proxy-based Deep Metric Learning (DML) learns deep representations by embedding images close to their class representatives (proxies), commonly with respect to the angle between them. However, this disregards the embedding norm, which can carry additional beneficial context such as class- or image-intrinsic uncertainty. In addition, proxy-based DML struggles to learn class-internal structures. To address both issues at once, we introduce non-isotropic probabilistic proxy-based DML. We model images as directional von Mises-Fisher (vMF) distributions on the hypersphere that can reflect image-intrinsic uncertainties. Further, we derive non-isotropic von Mises-Fisher (nivMF) distributions for class proxies to better represent complex class-specific variances. To measure the proxy-to-image distance between these models, we develop and investigate multiple distribution-to-point and distribution-to-distribution metrics. Each framework choice is motivated by a set of ablational studies, which showcase beneficial properties of our probabilistic approach to proxy-based DML, such as uncertainty-awareness, better-behaved gradients during training, and overall improved generalization performance. The latter is especially reflected in the competitive performance on the standard DML benchmarks, where our approach compares favorably, suggesting that existing proxy-based DML can significantly benefit from a more probabilistic treatment. Code is available at github.com/ExplainableML/Probabilistic_Deep_Metric_Learning.
Is Fairness Only Metric Deep? Evaluating and Addressing Subgroup Gaps in Deep Metric Learning
Mar 23, 2022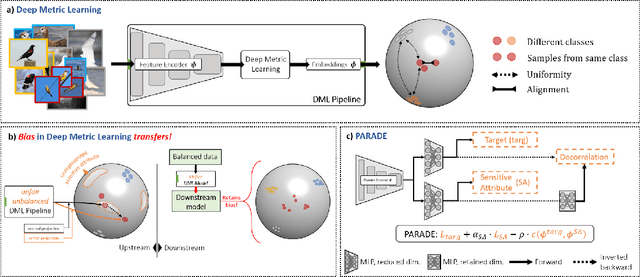
Deep metric learning (DML) enables learning with less supervision through its emphasis on the similarity structure of representations. There has been much work on improving generalization of DML in settings like zero-shot retrieval, but little is known about its implications for fairness. In this paper, we are the first to evaluate state-of-the-art DML methods trained on imbalanced data, and to show the negative impact these representations have on minority subgroup performance when used for downstream tasks. In this work, we first define fairness in DML through an analysis of three properties of the representation space -- inter-class alignment, intra-class alignment, and uniformity -- and propose finDML, the fairness in non-balanced DML benchmark to characterize representation fairness. Utilizing finDML, we find bias in DML representations to propagate to common downstream classification tasks. Surprisingly, this bias is propagated even when training data in the downstream task is re-balanced. To address this problem, we present Partial Attribute De-correlation (PARADE) to de-correlate feature representations from sensitive attributes and reduce performance gaps between subgroups in both embedding space and downstream metrics.
Improving the Fairness of Chest X-ray Classifiers
Mar 23, 2022
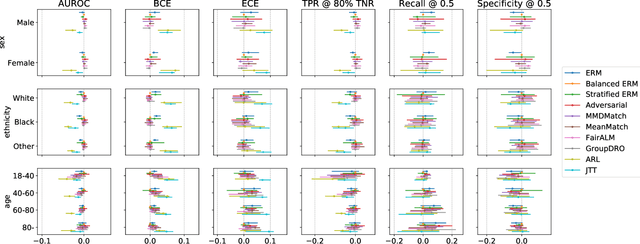
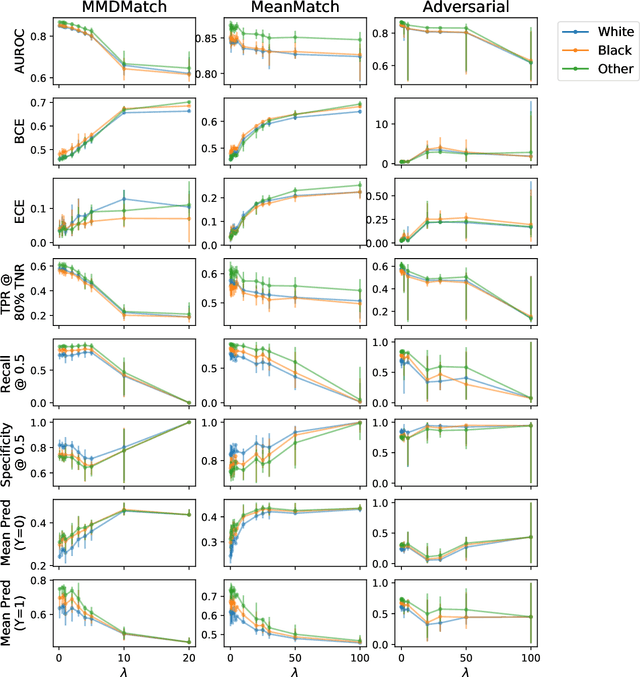
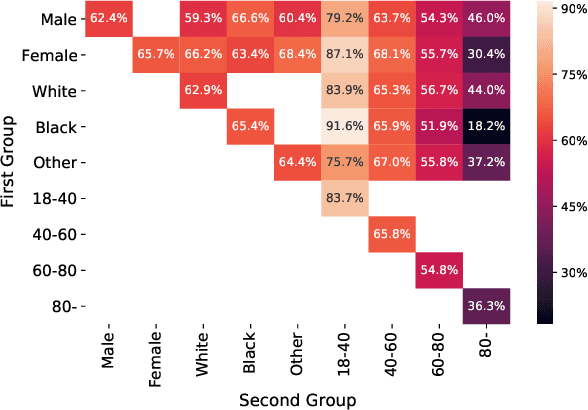
Deep learning models have reached or surpassed human-level performance in the field of medical imaging, especially in disease diagnosis using chest x-rays. However, prior work has found that such classifiers can exhibit biases in the form of gaps in predictive performance across protected groups. In this paper, we question whether striving to achieve zero disparities in predictive performance (i.e. group fairness) is the appropriate fairness definition in the clinical setting, over minimax fairness, which focuses on maximizing the performance of the worst-case group. We benchmark the performance of nine methods in improving classifier fairness across these two definitions. We find, consistent with prior work on non-clinical data, that methods which strive to achieve better worst-group performance do not outperform simple data balancing. We also find that methods which achieve group fairness do so by worsening performance for all groups. In light of these results, we discuss the utility of fairness definitions in the clinical setting, advocating for an investigation of the bias-inducing mechanisms in the underlying data generating process whenever possible.