 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYang Bai
Semi-supervised Text-based Person Search
Apr 28, 2024
Text-based person search (TBPS) aims to retrieve images of a specific person from a large image gallery based on a natural language description. Existing methods rely on massive annotated image-text data to achieve satisfactory performance in fully-supervised learning. It poses a significant challenge in practice, as acquiring person images from surveillance videos is relatively easy, while obtaining annotated texts is challenging. The paper undertakes a pioneering initiative to explore TBPS under the semi-supervised setting, where only a limited number of person images are annotated with textual descriptions while the majority of images lack annotations. We present a two-stage basic solution based on generation-then-retrieval for semi-supervised TBPS. The generation stage enriches annotated data by applying an image captioning model to generate pseudo-texts for unannotated images. Later, the retrieval stage performs fully-supervised retrieval learning using the augmented data. Significantly, considering the noise interference of the pseudo-texts on retrieval learning, we propose a noise-robust retrieval framework that enhances the ability of the retrieval model to handle noisy data. The framework integrates two key strategies: Hybrid Patch-Channel Masking (PC-Mask) to refine the model architecture, and Noise-Guided Progressive Training (NP-Train) to enhance the training process. PC-Mask performs masking on the input data at both the patch-level and the channel-level to prevent overfitting noisy supervision. NP-Train introduces a progressive training schedule based on the noise level of pseudo-texts to facilitate noise-robust learning. Extensive experiments on multiple TBPS benchmarks show that the proposed framework achieves promising performance under the semi-supervised setting.
Energy-Latency Manipulation of Multi-modal Large Language Models via Verbose Samples
Apr 25, 2024Despite the exceptional performance of multi-modal large language models (MLLMs), their deployment requires substantial computational resources. Once malicious users induce high energy consumption and latency time (energy-latency cost), it will exhaust computational resources and harm availability of service. In this paper, we investigate this vulnerability for MLLMs, particularly image-based and video-based ones, and aim to induce high energy-latency cost during inference by crafting an imperceptible perturbation. We find that high energy-latency cost can be manipulated by maximizing the length of generated sequences, which motivates us to propose verbose samples, including verbose images and videos. Concretely, two modality non-specific losses are proposed, including a loss to delay end-of-sequence (EOS) token and an uncertainty loss to increase the uncertainty over each generated token. In addition, improving diversity is important to encourage longer responses by increasing the complexity, which inspires the following modality specific loss. For verbose images, a token diversity loss is proposed to promote diverse hidden states. For verbose videos, a frame feature diversity loss is proposed to increase the feature diversity among frames. To balance these losses, we propose a temporal weight adjustment algorithm. Experiments demonstrate that our verbose samples can largely extend the length of generated sequences.
MedRG: Medical Report Grounding with Multi-modal Large Language Model
Apr 10, 2024Medical Report Grounding is pivotal in identifying the most relevant regions in medical images based on a given phrase query, a critical aspect in medical image analysis and radiological diagnosis. However, prevailing visual grounding approaches necessitate the manual extraction of key phrases from medical reports, imposing substantial burdens on both system efficiency and physicians. In this paper, we introduce a novel framework, Medical Report Grounding (MedRG), an end-to-end solution for utilizing a multi-modal Large Language Model to predict key phrase by incorporating a unique token, BOX, into the vocabulary to serve as an embedding for unlocking detection capabilities. Subsequently, the vision encoder-decoder jointly decodes the hidden embedding and the input medical image, generating the corresponding grounding box. The experimental results validate the effectiveness of MedRG, surpassing the performance of the existing state-of-the-art medical phrase grounding methods. This study represents a pioneering exploration of the medical report grounding task, marking the first-ever endeavor in this domain.
Natural-artificial hybrid swarm: Cyborg-insect group navigation in unknown obstructed soft terrain
Mar 27, 2024
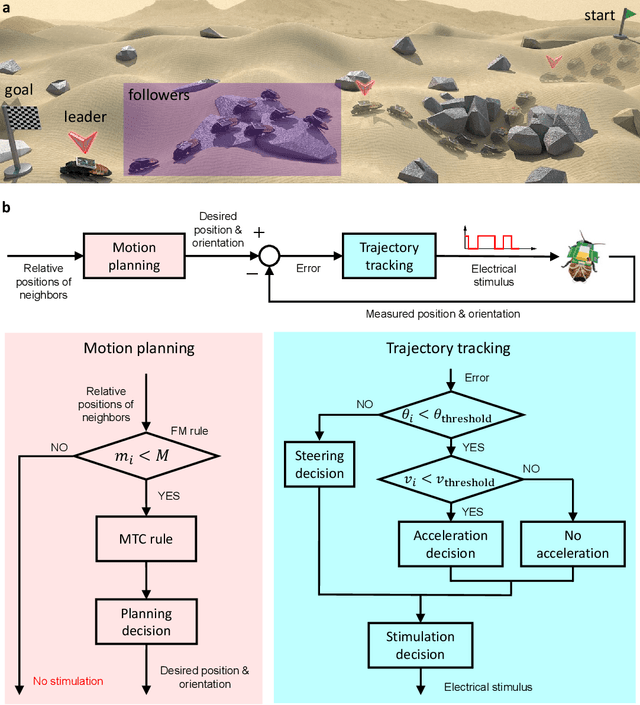
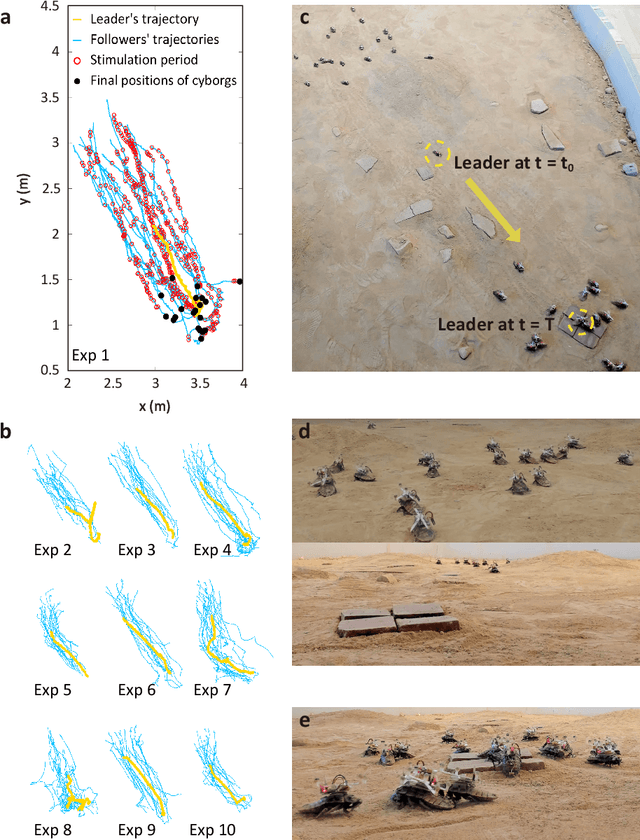
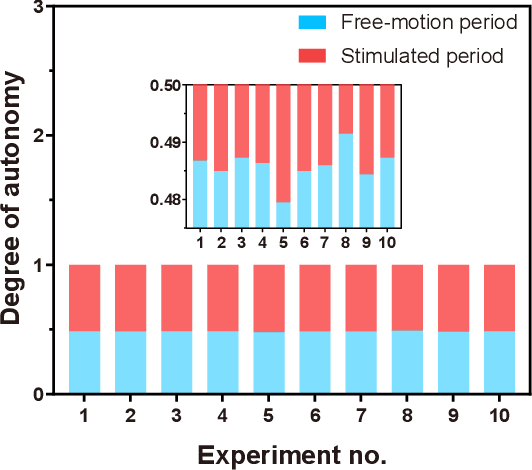
Navigating multi-robot systems in complex terrains has always been a challenging task. This is due to the inherent limitations of traditional robots in collision avoidance, adaptation to unknown environments, and sustained energy efficiency. In order to overcome these limitations, this research proposes a solution by integrating living insects with miniature electronic controllers to enable robotic-like programmable control, and proposing a novel control algorithm for swarming. Although these creatures, called cyborg insects, have the ability to instinctively avoid collisions with neighbors and obstacles while adapting to complex terrains, there is a lack of literature on the control of multi-cyborg systems. This research gap is due to the difficulty in coordinating the movements of a cyborg system under the presence of insects' inherent individual variability in their reactions to control input. In response to this issue, we propose a novel swarm navigation algorithm addressing these challenges. The effectiveness of the algorithm is demonstrated through an experimental validation in which a cyborg swarm was successfully navigated through an unknown sandy field with obstacles and hills. This research contributes to the domain of swarm robotics and showcases the potential of integrating biological organisms with robotics and control theory to create more intelligent autonomous systems with real-world applications.
M3: A Multi-Task Mixed-Objective Learning Framework for Open-Domain Multi-Hop Dense Sentence Retrieval
Mar 21, 2024
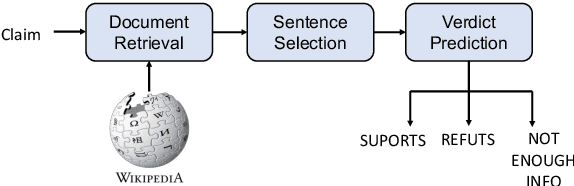
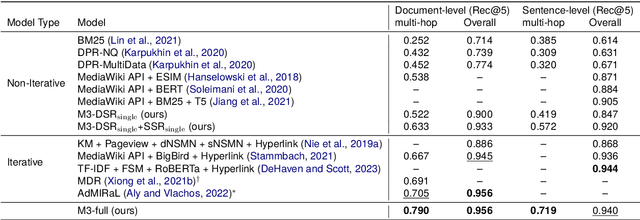
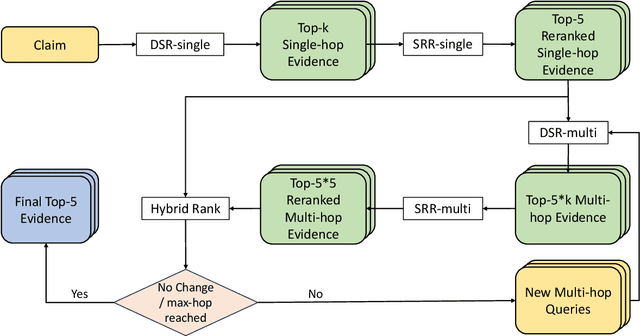
In recent research, contrastive learning has proven to be a highly effective method for representation learning and is widely used for dense retrieval. However, we identify that relying solely on contrastive learning can lead to suboptimal retrieval performance. On the other hand, despite many retrieval datasets supporting various learning objectives beyond contrastive learning, combining them efficiently in multi-task learning scenarios can be challenging. In this paper, we introduce M3, an advanced recursive Multi-hop dense sentence retrieval system built upon a novel Multi-task Mixed-objective approach for dense text representation learning, addressing the aforementioned challenges. Our approach yields state-of-the-art performance on a large-scale open-domain fact verification benchmark dataset, FEVER. Code and data are available at: https://github.com/TonyBY/M3
FMM-Attack: A Flow-based Multi-modal Adversarial Attack on Video-based LLMs
Mar 21, 2024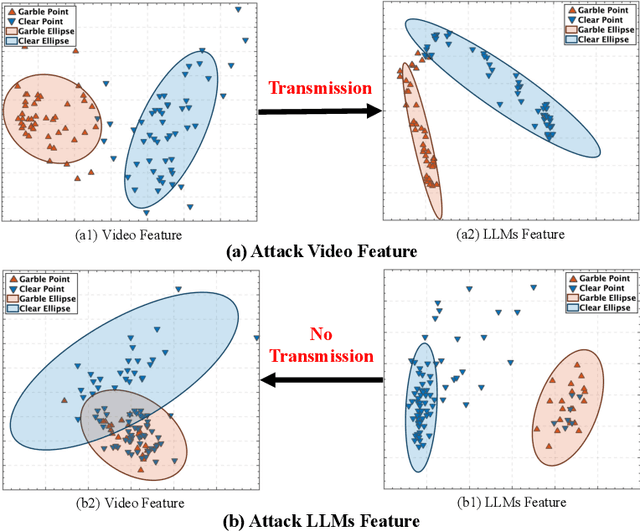
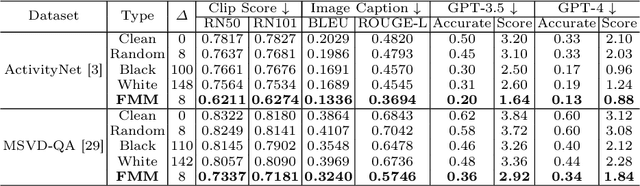
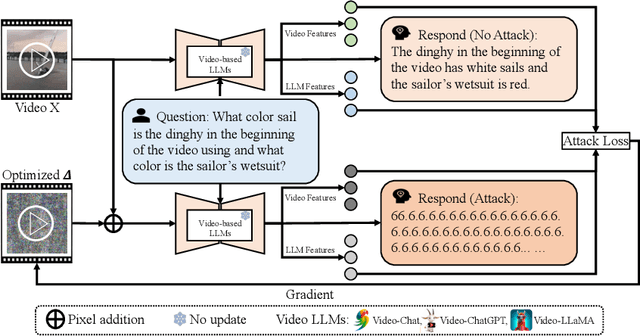

Despite the remarkable performance of video-based large language models (LLMs), their adversarial threat remains unexplored. To fill this gap, we propose the first adversarial attack tailored for video-based LLMs by crafting flow-based multi-modal adversarial perturbations on a small fraction of frames within a video, dubbed FMM-Attack. Extensive experiments show that our attack can effectively induce video-based LLMs to generate incorrect answers when videos are added with imperceptible adversarial perturbations. Intriguingly, our FMM-Attack can also induce garbling in the model output, prompting video-based LLMs to hallucinate. Overall, our observations inspire a further understanding of multi-modal robustness and safety-related feature alignment across different modalities, which is of great importance for various large multi-modal models. Our code is available at https://github.com/THU-Kingmin/FMM-Attack.
Solving General Noisy Inverse Problem via Posterior Sampling: A Policy Gradient Viewpoint
Mar 15, 2024
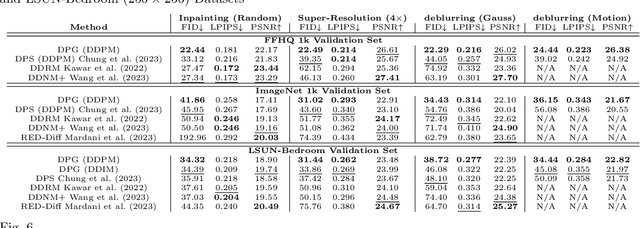

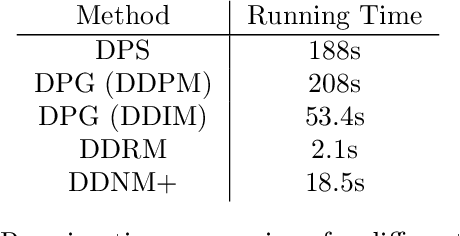
Solving image inverse problems (e.g., super-resolution and inpainting) requires generating a high fidelity image that matches the given input (the low-resolution image or the masked image). By using the input image as guidance, we can leverage a pretrained diffusion generative model to solve a wide range of image inverse tasks without task specific model fine-tuning. To precisely estimate the guidance score function of the input image, we propose Diffusion Policy Gradient (DPG), a tractable computation method by viewing the intermediate noisy images as policies and the target image as the states selected by the policy. Experiments show that our method is robust to both Gaussian and Poisson noise degradation on multiple linear and non-linear inverse tasks, resulting into a higher image restoration quality on FFHQ, ImageNet and LSUN datasets.
What Makes Good Collaborative Views? Contrastive Mutual Information Maximization for Multi-Agent Perception
Mar 15, 2024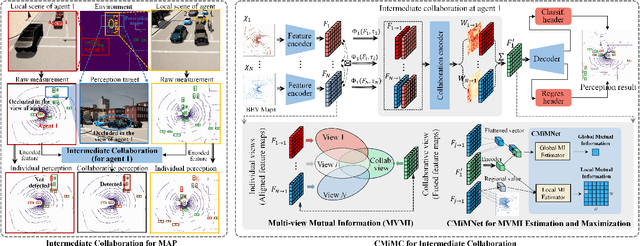
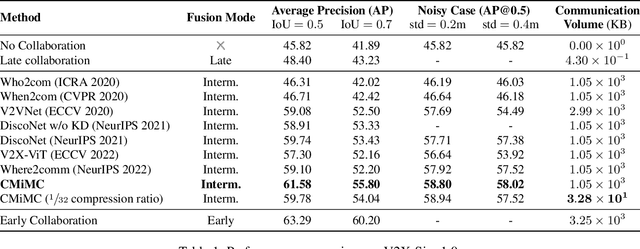
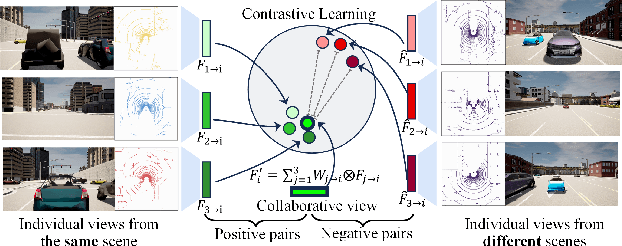
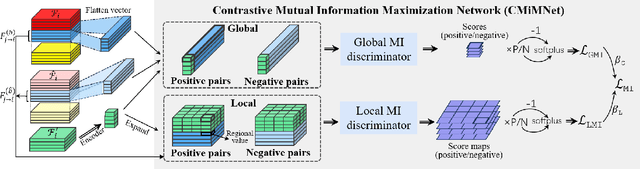
Multi-agent perception (MAP) allows autonomous systems to understand complex environments by interpreting data from multiple sources. This paper investigates intermediate collaboration for MAP with a specific focus on exploring "good" properties of collaborative view (i.e., post-collaboration feature) and its underlying relationship to individual views (i.e., pre-collaboration features), which were treated as an opaque procedure by most existing works. We propose a novel framework named CMiMC (Contrastive Mutual Information Maximization for Collaborative Perception) for intermediate collaboration. The core philosophy of CMiMC is to preserve discriminative information of individual views in the collaborative view by maximizing mutual information between pre- and post-collaboration features while enhancing the efficacy of collaborative views by minimizing the loss function of downstream tasks. In particular, we define multi-view mutual information (MVMI) for intermediate collaboration that evaluates correlations between collaborative views and individual views on both global and local scales. We establish CMiMNet based on multi-view contrastive learning to realize estimation and maximization of MVMI, which assists the training of a collaboration encoder for voxel-level feature fusion. We evaluate CMiMC on V2X-Sim 1.0, and it improves the SOTA average precision by 3.08% and 4.44% at 0.5 and 0.7 IoU (Intersection-over-Union) thresholds, respectively. In addition, CMiMC can reduce communication volume to 1/32 while achieving performance comparable to SOTA. Code and Appendix are released at https://github.com/77SWF/CMiMC.
ChatPattern: Layout Pattern Customization via Natural Language
Mar 15, 2024Existing works focus on fixed-size layout pattern generation, while the more practical free-size pattern generation receives limited attention. In this paper, we propose ChatPattern, a novel Large-Language-Model (LLM) powered framework for flexible pattern customization. ChatPattern utilizes a two-part system featuring an expert LLM agent and a highly controllable layout pattern generator. The LLM agent can interpret natural language requirements and operate design tools to meet specified needs, while the generator excels in conditional layout generation, pattern modification, and memory-friendly patterns extension. Experiments on challenging pattern generation setting shows the ability of ChatPattern to synthesize high-quality large-scale patterns.
IMUOptimize: A Data-Driven Approach to Optimal IMU Placement for Human Pose Estimation with Transformer Architecture
Feb 16, 2024This paper presents a novel approach for predicting human poses using IMU data, diverging from previous studies such as DIP-IMU, IMUPoser, and TransPose, which use up to 6 IMUs in conjunction with bidirectional RNNs. We introduce two main innovations: a data-driven strategy for optimal IMU placement and a transformer-based model architecture for time series analysis. Our findings indicate that our approach not only outperforms traditional 6 IMU-based biRNN models but also that the transformer architecture significantly enhances pose reconstruction from data obtained from 24 IMU locations, with equivalent performance to biRNNs when using only 6 IMUs. The enhanced accuracy provided by our optimally chosen locations, when coupled with the parallelizability and performance of transformers, provides significant improvements to the field of IMU-based pose estimation.