 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXi Lin
Multi-Agent RL-Based Industrial AIGC Service Offloading over Wireless Edge Networks
May 05, 2024
Currently, the generative model has garnered considerable attention due to its application in addressing the challenge of scarcity of abnormal samples in the industrial Internet of Things (IoT). However, challenges persist regarding the edge deployment of generative models and the optimization of joint edge AI-generated content (AIGC) tasks. In this paper, we focus on the edge optimization of AIGC task execution and propose GMEL, a generative model-driven industrial AIGC collaborative edge learning framework. This framework aims to facilitate efficient few-shot learning by leveraging realistic sample synthesis and edge-based optimization capabilities. First, a multi-task AIGC computational offloading model is presented to ensure the efficient execution of heterogeneous AIGC tasks on edge servers. Then, we propose an attention-enhanced multi-agent reinforcement learning (AMARL) algorithm aimed at refining offloading policies within the IoT system, thereby supporting generative model-driven edge learning. Finally, our experimental results demonstrate the effectiveness of the proposed algorithm in optimizing the total system latency of the edge-based AIGC task completion.
Instance-Conditioned Adaptation for Large-scale Generalization of Neural Combinatorial Optimization
May 03, 2024The neural combinatorial optimization (NCO) approach has shown great potential for solving routing problems without the requirement of expert knowledge. However, existing constructive NCO methods cannot directly solve large-scale instances, which significantly limits their application prospects. To address these crucial shortcomings, this work proposes a novel Instance-Conditioned Adaptation Model (ICAM) for better large-scale generalization of neural combinatorial optimization. In particular, we design a powerful yet lightweight instance-conditioned adaptation module for the NCO model to generate better solutions for instances across different scales. In addition, we develop an efficient three-stage reinforcement learning-based training scheme that enables the model to learn cross-scale features without any labeled optimal solution. Experimental results show that our proposed method is capable of obtaining excellent results with a very fast inference time in solving Traveling Salesman Problems (TSPs) and Capacitated Vehicle Routing Problems (CVRPs) across different scales. To the best of our knowledge, our model achieves state-of-the-art performance among all RL-based constructive methods for TSP and CVRP with up to 1,000 nodes.
Self-Improved Learning for Scalable Neural Combinatorial Optimization
Mar 30, 2024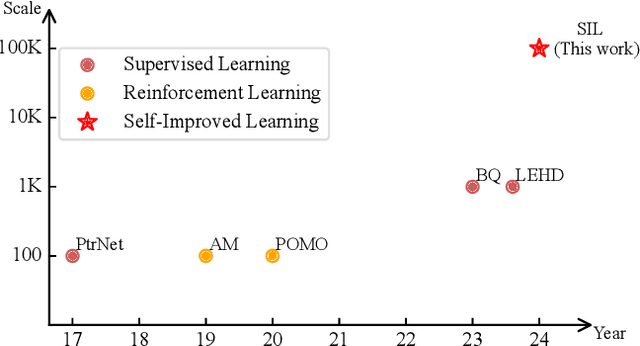


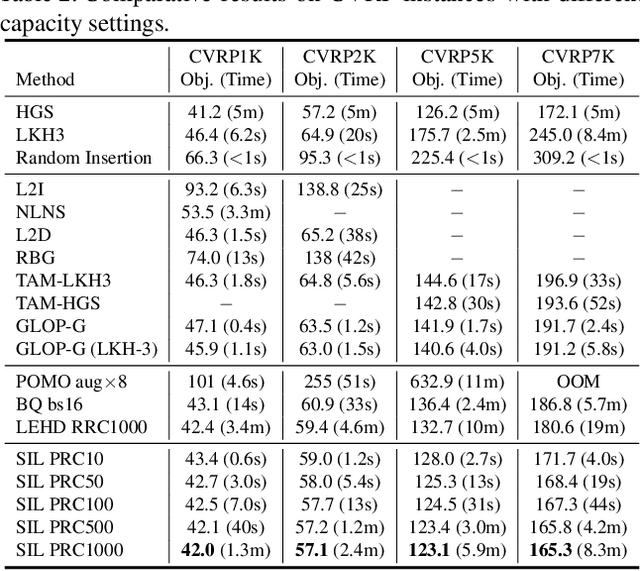
The end-to-end neural combinatorial optimization (NCO) method shows promising performance in solving complex combinatorial optimization problems without the need for expert design. However, existing methods struggle with large-scale problems, hindering their practical applicability. To overcome this limitation, this work proposes a novel Self-Improved Learning (SIL) method for better scalability of neural combinatorial optimization. Specifically, we develop an efficient self-improved mechanism that enables direct model training on large-scale problem instances without any labeled data. Powered by an innovative local reconstruction approach, this method can iteratively generate better solutions by itself as pseudo-labels to guide efficient model training. In addition, we design a linear complexity attention mechanism for the model to efficiently handle large-scale combinatorial problem instances with low computation overhead. Comprehensive experiments on the Travelling Salesman Problem (TSP) and the Capacitated Vehicle Routing Problem (CVRP) with up to 100K nodes in both uniform and real-world distributions demonstrate the superior scalability of our method.
Approximation of a Pareto Set Segment Using a Linear Model with Sharing Variables
Mar 30, 2024In many real-world applications, the Pareto Set (PS) of a continuous multiobjective optimization problem can be a piecewise continuous manifold. A decision maker may want to find a solution set that approximates a small part of the PS and requires the solutions in this set share some similarities. This paper makes a first attempt to address this issue. We first develop a performance metric that considers both optimality and variable sharing. Then we design an algorithm for finding the model that minimizes the metric to meet the user's requirements. Experimental results illustrate that we can obtain a linear model that approximates the mapping from the preference vectors to solutions in a local area well.
Spikewhisper: Temporal Spike Backdoor Attacks on Federated Neuromorphic Learning over Low-power Devices
Mar 27, 2024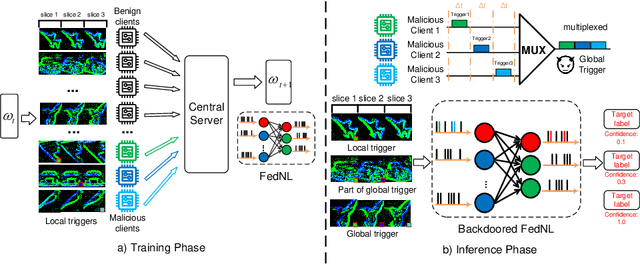

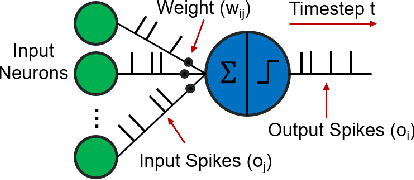
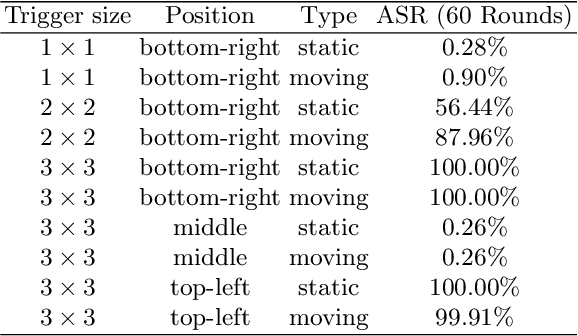
Federated neuromorphic learning (FedNL) leverages event-driven spiking neural networks and federated learning frameworks to effectively execute intelligent analysis tasks over amounts of distributed low-power devices but also perform vulnerability to poisoning attacks. The threat of backdoor attacks on traditional deep neural networks typically comes from time-invariant data. However, in FedNL, unknown threats may be hidden in time-varying spike signals. In this paper, we start to explore a novel vulnerability of FedNL-based systems with the concept of time division multiplexing, termed Spikewhisper, which allows attackers to evade detection as much as possible, as multiple malicious clients can imperceptibly poison with different triggers at different timeslices. In particular, the stealthiness of Spikewhisper is derived from the time-domain divisibility of global triggers, in which each malicious client pastes only one local trigger to a certain timeslice in the neuromorphic sample, and also the polarity and motion of each local trigger can be configured by attackers. Extensive experiments based on two different neuromorphic datasets demonstrate that the attack success rate of Spikewispher is higher than the temporally centralized attacks. Besides, it is validated that the effect of Spikewispher is sensitive to the trigger duration.
What Makes Good Collaborative Views? Contrastive Mutual Information Maximization for Multi-Agent Perception
Mar 15, 2024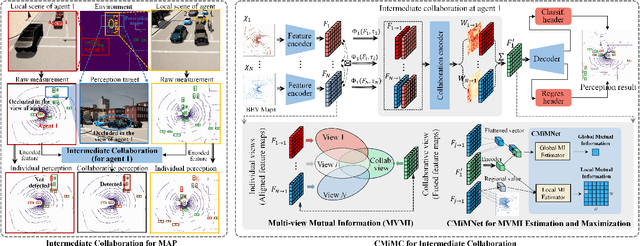
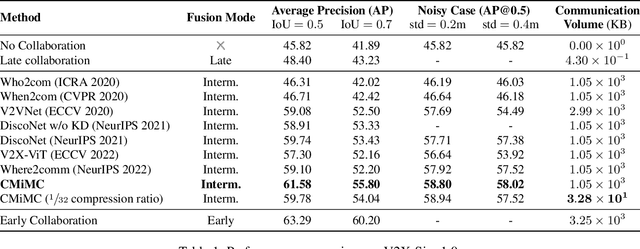
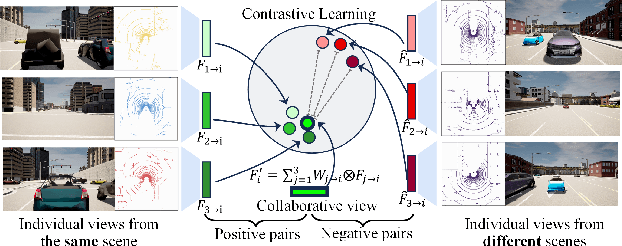
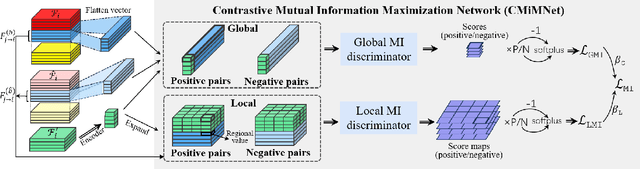
Multi-agent perception (MAP) allows autonomous systems to understand complex environments by interpreting data from multiple sources. This paper investigates intermediate collaboration for MAP with a specific focus on exploring "good" properties of collaborative view (i.e., post-collaboration feature) and its underlying relationship to individual views (i.e., pre-collaboration features), which were treated as an opaque procedure by most existing works. We propose a novel framework named CMiMC (Contrastive Mutual Information Maximization for Collaborative Perception) for intermediate collaboration. The core philosophy of CMiMC is to preserve discriminative information of individual views in the collaborative view by maximizing mutual information between pre- and post-collaboration features while enhancing the efficacy of collaborative views by minimizing the loss function of downstream tasks. In particular, we define multi-view mutual information (MVMI) for intermediate collaboration that evaluates correlations between collaborative views and individual views on both global and local scales. We establish CMiMNet based on multi-view contrastive learning to realize estimation and maximization of MVMI, which assists the training of a collaboration encoder for voxel-level feature fusion. We evaluate CMiMC on V2X-Sim 1.0, and it improves the SOTA average precision by 3.08% and 4.44% at 0.5 and 0.7 IoU (Intersection-over-Union) thresholds, respectively. In addition, CMiMC can reduce communication volume to 1/32 while achieving performance comparable to SOTA. Code and Appendix are released at https://github.com/77SWF/CMiMC.
Smooth Tchebycheff Scalarization for Multi-Objective Optimization
Mar 14, 2024Multi-objective optimization problems can be found in many real-world applications, where the objectives often conflict each other and cannot be optimized by a single solution. In the past few decades, numerous methods have been proposed to find Pareto solutions that represent different optimal trade-offs among the objectives for a given problem. However, these existing methods could have high computational complexity or may not have good theoretical properties for solving a general differentiable multi-objective optimization problem. In this work, by leveraging the smooth optimization technique, we propose a novel and lightweight smooth Tchebycheff scalarization approach for gradient-based multi-objective optimization. It has good theoretical properties for finding all Pareto solutions with valid trade-off preferences, while enjoying significantly lower computational complexity compared to other methods. Experimental results on various real-world application problems fully demonstrate the effectiveness of our proposed method.
Exploring the Adversarial Frontier: Quantifying Robustness via Adversarial Hypervolume
Mar 08, 2024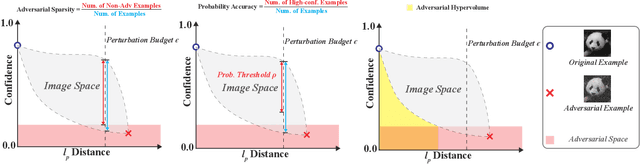
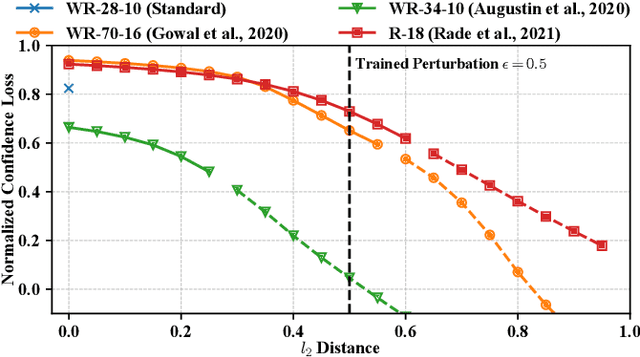
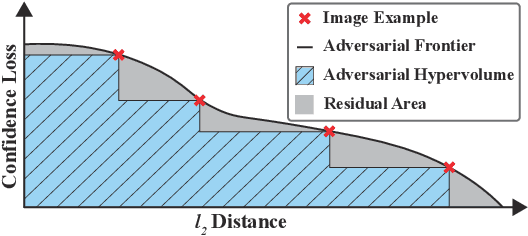
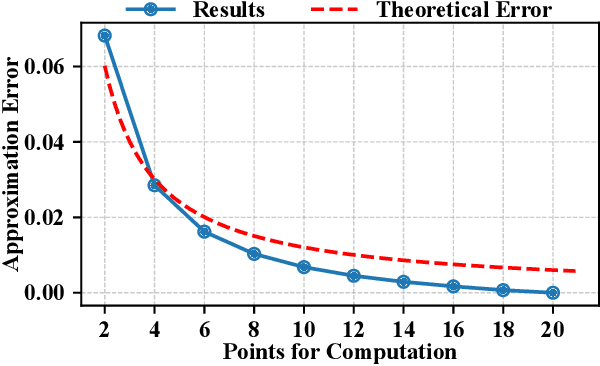
The escalating threat of adversarial attacks on deep learning models, particularly in security-critical fields, has underscored the need for robust deep learning systems. Conventional robustness evaluations have relied on adversarial accuracy, which measures a model's performance under a specific perturbation intensity. However, this singular metric does not fully encapsulate the overall resilience of a model against varying degrees of perturbation. To address this gap, we propose a new metric termed adversarial hypervolume, assessing the robustness of deep learning models comprehensively over a range of perturbation intensities from a multi-objective optimization standpoint. This metric allows for an in-depth comparison of defense mechanisms and recognizes the trivial improvements in robustness afforded by less potent defensive strategies. Additionally, we adopt a novel training algorithm that enhances adversarial robustness uniformly across various perturbation intensities, in contrast to methods narrowly focused on optimizing adversarial accuracy. Our extensive empirical studies validate the effectiveness of the adversarial hypervolume metric, demonstrating its ability to reveal subtle differences in robustness that adversarial accuracy overlooks. This research contributes a new measure of robustness and establishes a standard for assessing and benchmarking the resilience of current and future defensive models against adversarial threats.
Multi-Robot Autonomous Exploration and Mapping Under Localization Uncertainty with Expectation-Maximization
Mar 06, 2024


We propose an autonomous exploration algorithm designed for decentralized multi-robot teams, which takes into account map and localization uncertainties of range-sensing mobile robots. Virtual landmarks are used to quantify the combined impact of process noise and sensor noise on map uncertainty. Additionally, we employ an iterative expectation-maximization inspired algorithm to assess the potential outcomes of both a local robot's and its neighbors' next-step actions. To evaluate the effectiveness of our framework, we conduct a comparative analysis with state-of-the-art algorithms. The results of our experiments show the proposed algorithm's capacity to strike a balance between curbing map uncertainty and achieving efficient task allocation among robots.
Escaping Local Optima in Global Placement
Feb 28, 2024Placement is crucial in the physical design, as it greatly affects power, performance, and area metrics. Recent advancements in analytical methods, such as DREAMPlace, have demonstrated impressive performance in global placement. However, DREAMPlace has some limitations, e.g., may not guarantee legalizable placements under the same settings, leading to fragile and unpredictable results. This paper highlights the main issue as being stuck in local optima, and proposes a hybrid optimization framework to efficiently escape the local optima, by perturbing the placement result iteratively. The proposed framework achieves significant improvements compared to state-of-the-art methods on two popular benchmarks.